Clear Sky Science · en
Design, framework and benchmark of safety monitors for black-box classifiers
Why safe machine decisions matter
More and more, machines are helping to drive cars, guide surgical tools, watch over factories and inspect critical infrastructure. All of these tasks depend on software that looks at data and chooses between options, such as “safe” or “unsafe.” When that judgment is wrong, the result can be a missed intruder, a misread traffic light or an undetected failing part. This paper explores how to surround such decision software with an extra layer of protection so that risky answers are flagged and held back instead of blindly trusted.
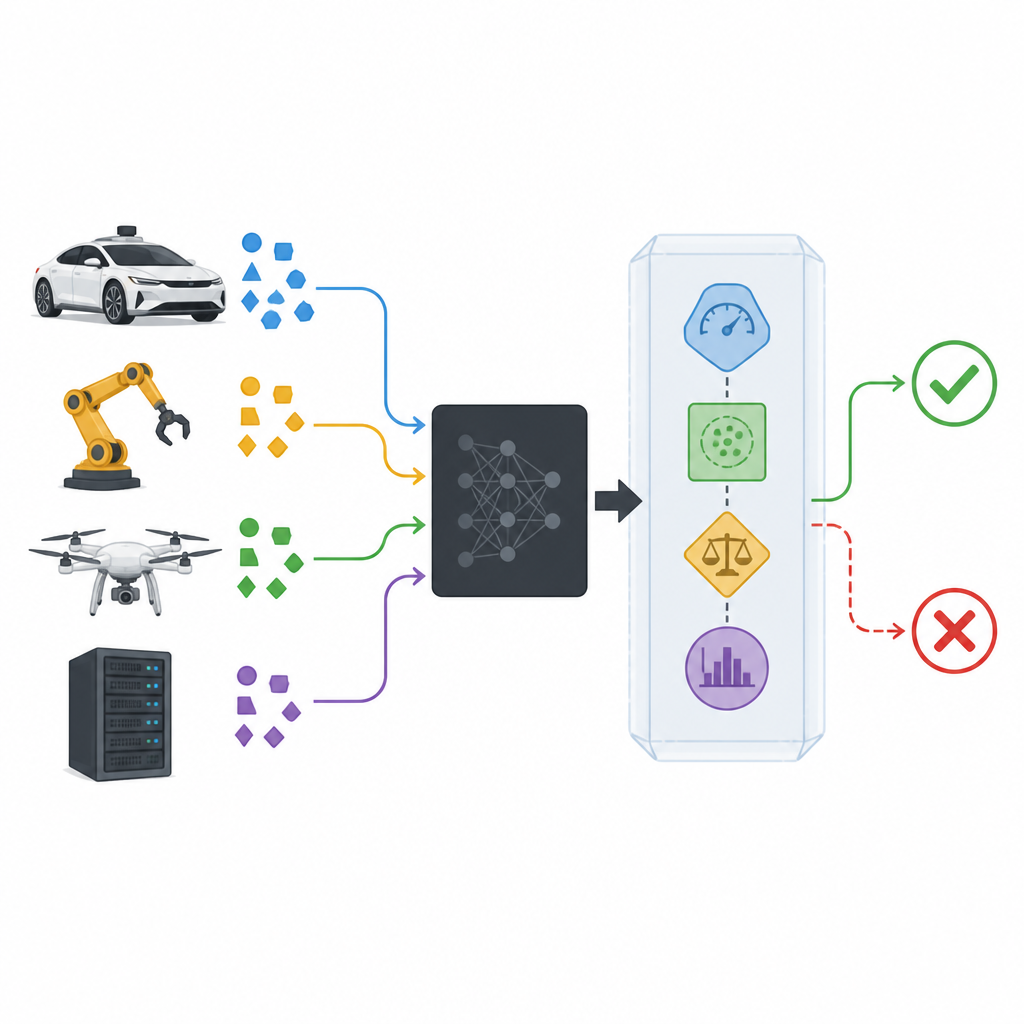
From perfect answers to trustworthy behavior
Most work on artificial intelligence tries to make classifiers as accurate as possible, but even the best systems still make mistakes. Human experts also misjudge situations, yet we still rely on them because they usually know when to ask for help. The authors argue that machine decision makers should behave more like that. Instead of forcing a classifier to always choose a label, it should be allowed to say “I am not sure” and let the larger system react safely. In practice, this means turning unpredictable wrong answers into controlled rejections that other parts of the system can handle, for example by slowing a vehicle, asking a human for input, or switching to a safer mode.
Adding a safety wrapper around black box models
Modern classifiers are often treated as black boxes: they take in data and output a prediction, while their inner workings remain hidden or too complex to inspect. The proposed safety wrapper, called SPROUT, sits around such a black box without needing to look inside. It watches each new input, the probabilities the classifier assigns to possible classes, and how that input compares to past data. From this information, SPROUT decides whether a prediction seems trustworthy enough to pass on, or whether it should be rejected as suspicious. The key point is that almost any existing classifier, for images or tables of numbers, binary or multi-class, can be wrapped in this way as long as it can output class probabilities.
Measuring doubt in many different ways
To judge how confident a prediction really is, SPROUT does not rely on a single signal. Instead, it combines several “uncertainty measures” that each look at doubt from a different angle. Some check simple signs, such as whether one class probability really stands out or whether the probabilities are spread out evenly. Others compare the classifier’s answer with that of extra “checker” models trained on the same data, or with the answers given to nearby data points in the training set. Another measure tries to rebuild the input using an autoencoder network and treats a poor reconstruction as a hint that the new data are unlike anything seen before. Together these measures form a compact table of numbers which a small second-level model, called an adjudicator, converts into a simple keep-or-reject decision.
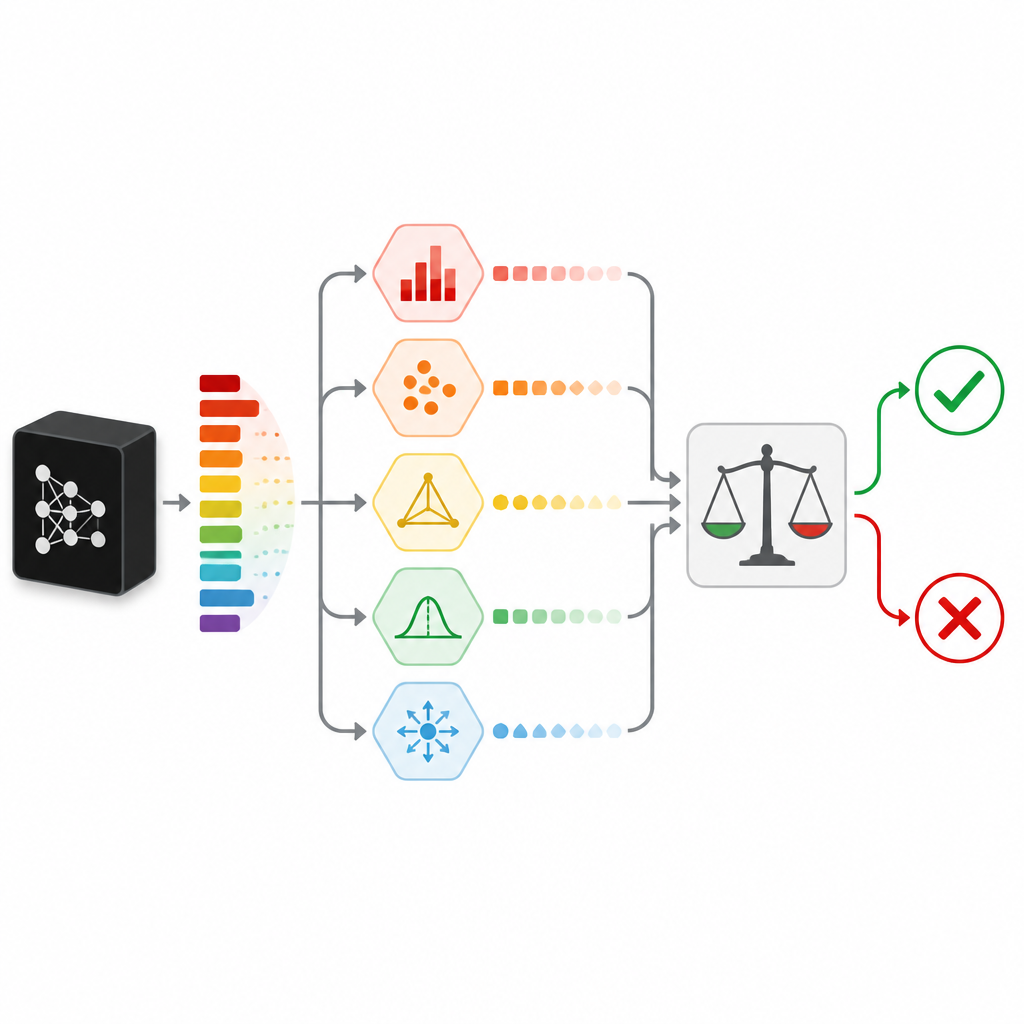
Testing across many datasets and model types
The authors carried out a large experimental study using 35 publicly available datasets, covering network attacks, biometric spoofing, hardware failures, Internet of Things sensors and several popular image sets. They tried more than 20 types of classifiers, both supervised and unsupervised, and built separate SPROUT setups for tabular data and images. For each case, they measured how often the original classifier was wrong and how often SPROUT managed to reject those wrong answers before they could escape. For many supervised tasks, including some image problems, SPROUT cut the remaining error rate dramatically. In certain cases, such as a logistic regression model on a network security dataset, it rejected every single misclassification, turning a sometimes unreliable component into one whose outputs could be trusted when they were not rejected.
Balancing safety, availability and cost
Of course, catching more mistakes often means rejecting more correct answers as well, and computing many uncertainty measures adds time and resource overhead. The study shows that SPROUT typically makes supervised classifiers about four to five times slower and that some measures are more costly than others. This suggests a design trade-off: safety-critical systems might accept extra delay and more rejections to avoid harmful outcomes, while time-sensitive or resource-limited applications might choose a smaller set of inexpensive checks. The authors also identify which measures matter most in practice, giving guidance on how to build lighter versions when needed.
What this means for safer AI in practice
In plain terms, the paper’s main message is that we should stop expecting flawless machine decisions and instead demand that our systems know when they might be wrong. SPROUT offers a practical blueprint for wrapping existing black box classifiers with a doubt-aware shield that rejects suspicious outputs before they cause damage. While this protection comes with extra computation and occasional loss of valid predictions, the results show that it can greatly reduce the chance that a dangerous mistake slips through unnoticed, making AI-based decision making more trustworthy in the real world.
Citation: Khokhar, F.A., Zoppi, T., Cennini, L. et al. Design, framework and benchmark of safety monitors for black-box classifiers. Sci Rep 16, 15626 (2026). https://doi.org/10.1038/s41598-026-45091-2
Keywords: AI safety, uncertainty, trustworthy AI, machine learning monitor, SPROUT framework