Clear Sky Science · es
Diseño, marco y evaluación de monitores de seguridad para clasificadores de caja negra
Por qué importan las decisiones seguras de las máquinas
Cada vez más, las máquinas ayudan a conducir vehículos, guiar herramientas quirúrgicas, vigilar fábricas e inspeccionar infraestructuras críticas. Todas estas tareas dependen de software que analiza datos y elige entre opciones, como “seguro” o “no seguro”. Cuando ese juicio es erróneo, el resultado puede ser un intruso no detectado, un semáforo mal interpretado o una pieza en fallo sin identificar. Este artículo explora cómo rodear ese software de toma de decisiones con una capa adicional de protección para que las respuestas riesgosas sean señalizadas y retenidas en lugar de confiarse ciegamente.
De respuestas perfectas a comportamiento confiable
La mayor parte del trabajo en inteligencia artificial intenta hacer los clasificadores lo más precisos posible, pero incluso los mejores sistemas siguen cometiendo errores. Los expertos humanos también valoran mal algunas situaciones; aun así, seguimos confiando en ellos porque suelen saber cuándo pedir ayuda. Los autores sostienen que los sistemas de decisión automática deberían comportarse más así. En lugar de forzar a un clasificador a elegir siempre una etiqueta, debería permitírsele decir “no estoy seguro” y dejar que el sistema mayor reaccione de forma segura. En la práctica, esto significa convertir respuestas equivocadas e impredecibles en rechazos controlados que otras partes del sistema puedan manejar, por ejemplo reduciendo la velocidad de un vehículo, solicitando intervención humana o cambiando a un modo más seguro.
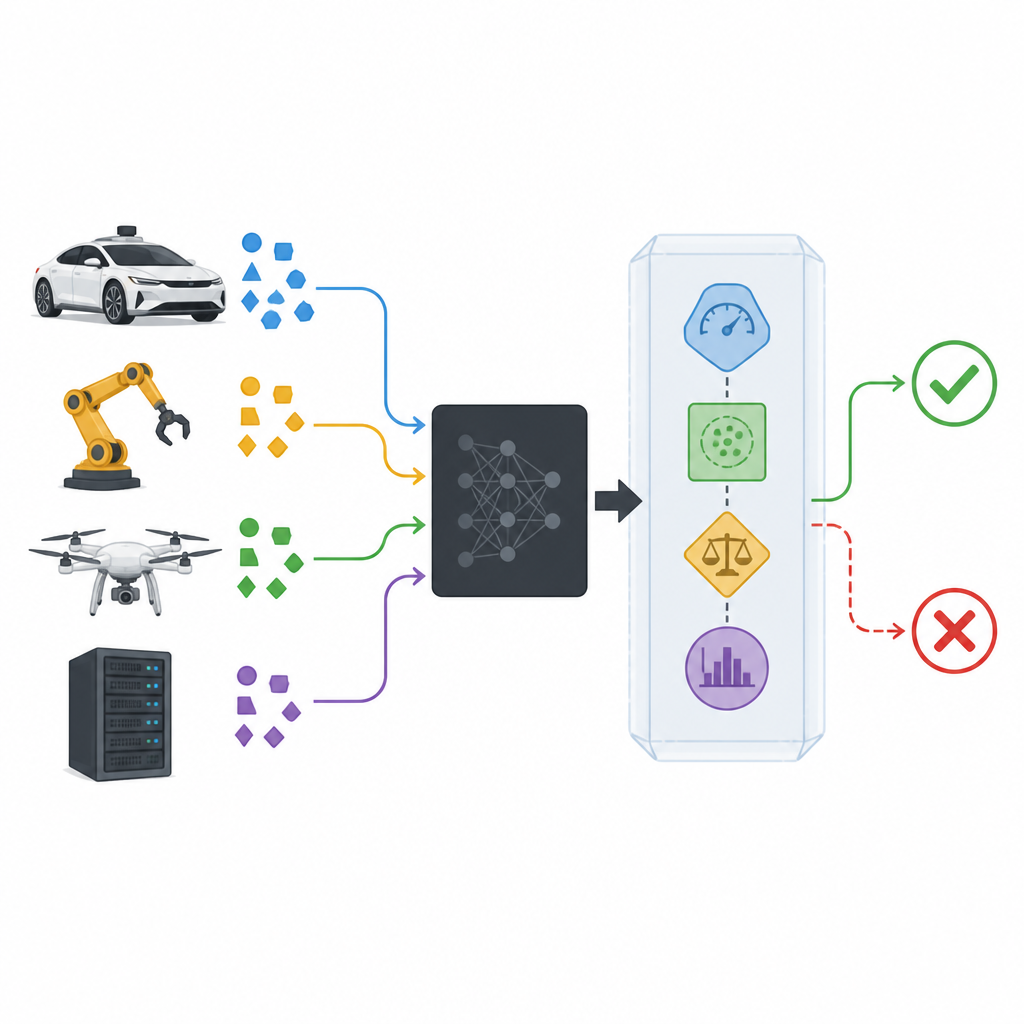
Añadiendo un envoltorio de seguridad alrededor de modelos de caja negra
Los clasificadores modernos suelen tratarse como cajas negras: reciben datos y devuelven una predicción, mientras que su funcionamiento interno permanece oculto o es demasiado complejo para inspeccionarlo. El envoltorio de seguridad propuesto, llamado SPROUT, se coloca alrededor de dicha caja negra sin necesidad de mirar dentro. Observa cada entrada nueva, las probabilidades que el clasificador asigna a las posibles clases y cómo esa entrada se compara con datos pasados. Con esta información, SPROUT decide si una predicción parece lo suficientemente confiable para transmitirse o si debe rechazarse por sospechosa. El punto clave es que casi cualquier clasificador existente, para imágenes o tablas numéricas, binario o multicategoría, puede envolverse de este modo siempre que pueda proporcionar probabilidades de clase.
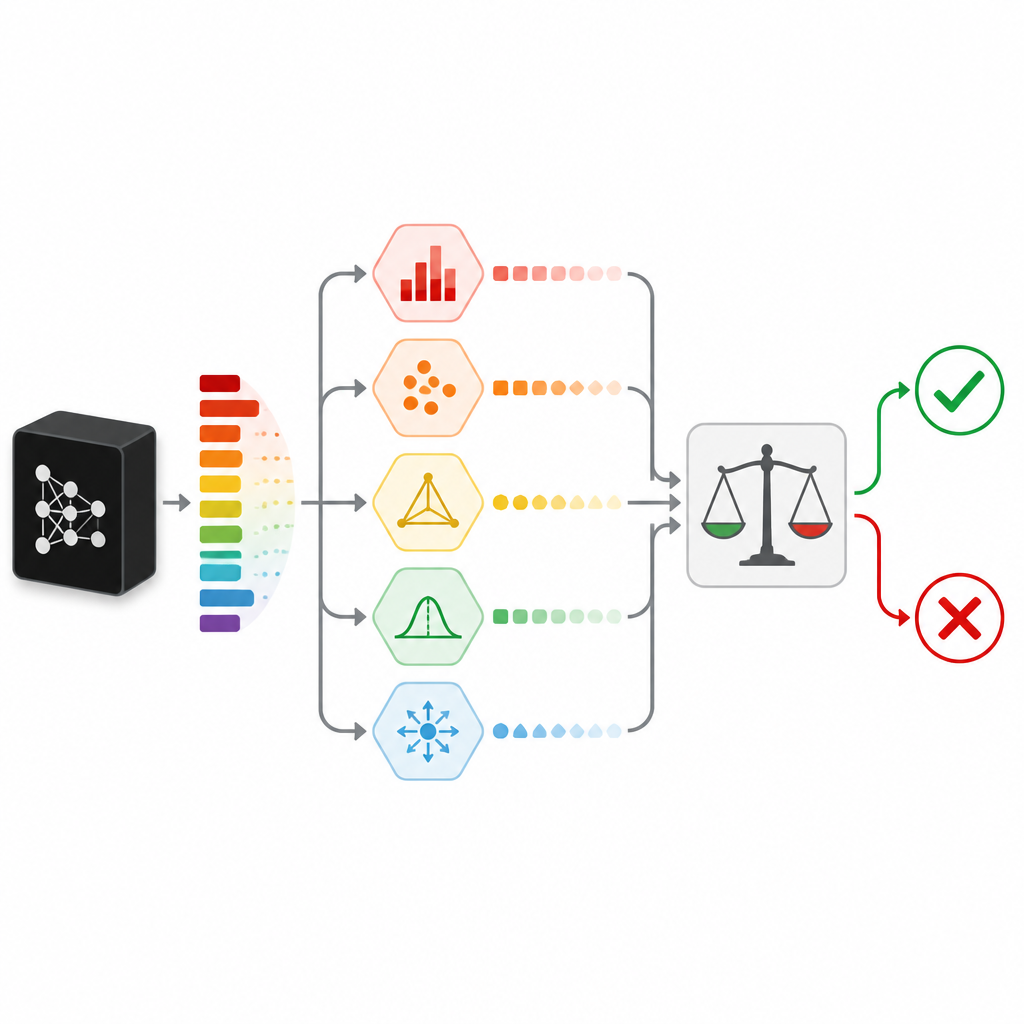
Midiendo la duda de muchas maneras diferentes
Para juzgar cuán confiable es realmente una predicción, SPROUT no se apoya en una única señal. En su lugar, combina varias “medidas de incertidumbre” que cada una examina la duda desde un ángulo distinto. Algunas comprueban signos sencillos, como si una probabilidad de clase destaca claramente o si las probabilidades están uniformemente repartidas. Otras comparan la respuesta del clasificador con la de modelos “verificadores” adicionales entrenados con los mismos datos, o con las respuestas dadas a puntos de datos cercanos en el conjunto de entrenamiento. Otra medida intenta reconstruir la entrada usando una red autoencoder y considera una mala reconstrucción como indicio de que los nuevos datos son distintos de todo lo visto antes. En conjunto, estas medidas forman una tabla compacta de números que un pequeño modelo de segundo nivel, llamado adjudicador, convierte en una simple decisión de mantener o rechazar.
Pruebas en múltiples conjuntos de datos y tipos de modelos
Los autores realizaron un amplio estudio experimental con 35 conjuntos de datos públicos, que abarcan ataques de red, suplantación biométrica, fallos de hardware, sensores del Internet de las Cosas y varios conjuntos populares de imágenes. Probaron más de 20 tipos de clasificadores, tanto supervisados como no supervisados, y construyeron configuraciones separadas de SPROUT para datos tabulares e imágenes. Para cada caso, midieron con qué frecuencia el clasificador original se equivocaba y con qué frecuencia SPROUT conseguía rechazar esas respuestas erróneas antes de que se escaparan. En muchas tareas supervisadas, incluidos algunos problemas con imágenes, SPROUT redujo de forma drástica la tasa de error restante. En ciertos casos, como un modelo de regresión logística en un conjunto de datos de seguridad de red, rechazó cada una de las malas clasificaciones, transformando un componente a veces poco fiable en uno cuyas salidas podían confiarse cuando no eran rechazadas.
Equilibrando seguridad, disponibilidad y coste
Por supuesto, detectar más errores suele significar también rechazar más respuestas correctas, y calcular muchas medidas de incertidumbre añade tiempo y coste en recursos. El estudio muestra que SPROUT típicamente hace que los clasificadores supervisados sean entre cuatro y cinco veces más lentos y que algunas medidas son más costosas que otras. Esto sugiere un compromiso de diseño: los sistemas críticos para la seguridad podrían aceptar mayor retraso y más rechazos para evitar resultados dañinos, mientras que las aplicaciones sensibles al tiempo o con recursos limitados podrían elegir un conjunto menor de comprobaciones económicas. Los autores también identifican qué medidas importan más en la práctica, ofreciendo orientación sobre cómo construir versiones más ligeras cuando sea necesario.
Qué implica esto para una IA más segura en la práctica
En términos sencillos, el mensaje principal del artículo es que debemos dejar de esperar decisiones perfectas de las máquinas y exigir en su lugar que nuestros sistemas sepan cuándo pueden estar equivocados. SPROUT ofrece un plano práctico para envolver clasificadores de caja negra existentes con un escudo consciente de la duda que rechaza salidas sospechosas antes de que causen daño. Aunque esta protección conlleva cálculo adicional y la pérdida ocasional de predicciones válidas, los resultados muestran que puede reducir considerablemente la probabilidad de que un error peligroso pase desapercibido, haciendo que la toma de decisiones basada en IA sea más confiable en el mundo real.
Cita: Khokhar, F.A., Zoppi, T., Cennini, L. et al. Design, framework and benchmark of safety monitors for black-box classifiers. Sci Rep 16, 15626 (2026). https://doi.org/10.1038/s41598-026-45091-2
Palabras clave: seguridad de la IA, incertidumbre, IA confiable, monitor de aprendizaje automático, marco SPROUT