Clear Sky Science · pt
Design, estrutura e avaliação de monitores de segurança para classificadores caixa-preta
Por que decisões de máquina seguras importam
Cada vez mais, máquinas ajudam a conduzir carros, guiar instrumentos cirúrgicos, supervisionar fábricas e inspecionar infraestrutura crítica. Todas essas tarefas dependem de software que analisa dados e escolhe entre opções, como “seguro” ou “inseguro”. Quando esse julgamento falha, o resultado pode ser um intruso não detectado, um semáforo interpretado erroneamente ou uma peça com defeito não identificada. Este artigo explora como cercar esse software de decisão com uma camada extra de proteção para que respostas de risco sejam sinalizadas e retidas em vez de ser confiadas cegamente.
De respostas perfeitas a comportamento confiável
A maior parte do trabalho em inteligência artificial busca tornar classificadores o mais precisos possível, mas mesmo os melhores sistemas ainda cometem erros. Especialistas humanos também avaliam mal situações, contudo continuamos a confiar neles porque geralmente sabem quando pedir ajuda. Os autores argumentam que os decisores automáticos devem se comportar de forma mais parecida. Em vez de forçar um classificador a escolher sempre um rótulo, ele deveria ter permissão para dizer “não tenho certeza” e deixar o sistema mais amplo reagir com segurança. Na prática, isso significa transformar respostas erradas imprevisíveis em rejeições controladas que outras partes do sistema podem manejar, por exemplo desacelerando um veículo, solicitando intervenção humana ou mudando para um modo mais seguro.
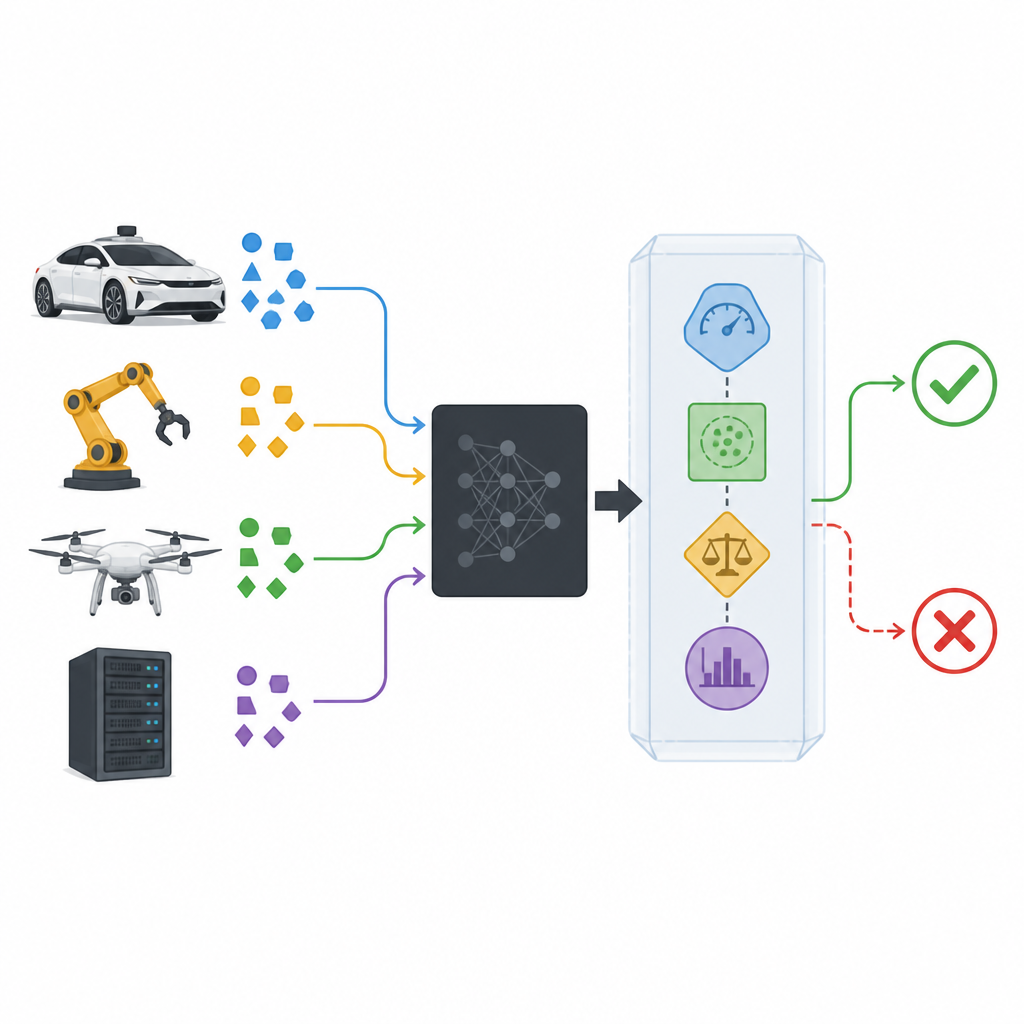
Adicionando um invólucro de segurança em torno de modelos caixa-preta
Classificadores modernos são frequentemente tratados como caixas-pretas: recebem dados e retornam uma previsão, enquanto seu funcionamento interno permanece oculto ou complexo demais para inspecionar. O invólucro de segurança proposto, chamado SPROUT, envolve tal caixa-preta sem precisar olhar para dentro. Ele observa cada nova entrada, as probabilidades que o classificador atribui às classes possíveis e como essa entrada se compara a dados anteriores. A partir dessas informações, o SPROUT decide se uma previsão parece confiável o suficiente para ser repassada, ou se deve ser rejeitada como suspeita. O ponto-chave é que quase qualquer classificador existente, para imagens ou tabelas numéricas, binário ou multiclasses, pode ser envolvido dessa maneira desde que consiga fornecer probabilidades de classe.
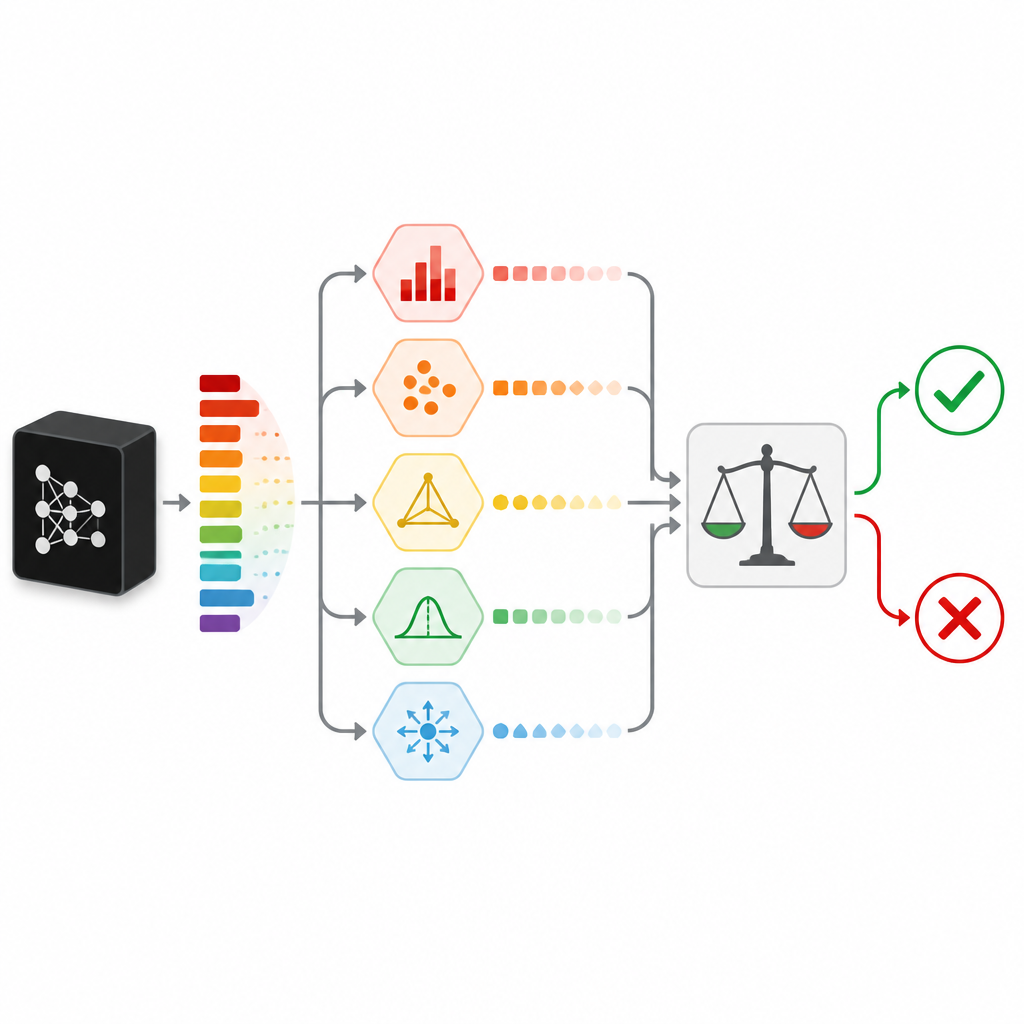
Medindo dúvida de várias maneiras
Para avaliar quão confiante é uma previsão, o SPROUT não depende de um único sinal. Em vez disso, combina várias “medidas de incerteza” que olham para a dúvida por ângulos diferentes. Algumas verificam sinais simples, como se uma probabilidade de classe realmente se destaca ou se as probabilidades estão distribuídas uniformemente. Outras comparam a resposta do classificador com a de modelos “verificadores” adicionais treinados sobre os mesmos dados, ou com as respostas dadas a pontos de dados vizinhos no conjunto de treinamento. Outra medida tenta reconstruir a entrada usando uma rede autoencoder e trata uma reconstrução ruim como um indício de que os novos dados são diferentes de tudo visto antes. Juntas, essas medidas formam uma tabela compacta de números que um pequeno modelo de segundo nível, chamado adjudicador, converte em uma simples decisão de manter ou rejeitar.
Testes em muitos conjuntos de dados e tipos de modelos
Os autores realizaram um grande estudo experimental usando 35 conjuntos de dados públicos, cobrindo ataques de rede, spoofing biométrico, falhas de hardware, sensores da Internet das Coisas e vários conjuntos de imagens populares. Testaram mais de 20 tipos de classificadores, tanto supervisionados quanto não supervisionados, e construíram configurações separadas do SPROUT para dados tabulares e imagens. Para cada caso, mediram com que frequência o classificador original errou e com que frequência o SPROUT conseguiu rejeitar essas respostas erradas antes que escapassem. Para muitas tarefas supervisionadas, incluindo alguns problemas de imagem, o SPROUT reduziu dramaticamente a taxa de erro remanescente. Em certos casos, como um modelo de regressão logística em um conjunto de dados de segurança de rede, ele rejeitou todas as classificações erradas, transformando um componente às vezes pouco confiável em um cujas saídas podiam ser confiadas quando não eram rejeitadas.
Balanceando segurança, disponibilidade e custo
Naturalmente, capturar mais erros frequentemente significa rejeitar mais respostas corretas também, e calcular muitas medidas de incerteza acrescenta tempo e custo computacional. O estudo mostra que o SPROUT normalmente torna classificadores supervisionados cerca de quatro a cinco vezes mais lentos e que algumas medidas são mais custosas que outras. Isso sugere um trade-off de projeto: sistemas críticos para segurança podem aceitar atraso extra e mais rejeições para evitar resultados prejudiciais, enquanto aplicações sensíveis ao tempo ou com recursos limitados podem escolher um conjunto menor de verificações baratas. Os autores também identificam quais medidas importam mais na prática, fornecendo orientação sobre como construir versões mais leves quando necessário.
O que isso significa para uma IA mais segura na prática
Em termos simples, a mensagem principal do artigo é que devemos parar de esperar decisões perfeitas das máquinas e, em vez disso, exigir que nossos sistemas saibam quando podem estar errados. O SPROUT oferece um roteiro prático para envolver classificadores caixa-preta existentes com um escudo atento à dúvida que rejeita saídas suspeitas antes que causem danos. Embora essa proteção envolva computação adicional e perda ocasional de previsões válidas, os resultados mostram que ela pode reduzir muito a chance de que um erro perigoso passe despercebido, tornando a tomada de decisão baseada em IA mais confiável no mundo real.
Citação: Khokhar, F.A., Zoppi, T., Cennini, L. et al. Design, framework and benchmark of safety monitors for black-box classifiers. Sci Rep 16, 15626 (2026). https://doi.org/10.1038/s41598-026-45091-2
Palavras-chave: Segurança em IA, incerteza, IA confiável, monitor de aprendizado de máquina, estrutura SPROUT