Clear Sky Science · nl
Ontwerp, raamwerk en benchmark van veiligheidsmonitors voor black-box-classifiers
Waarom veilige machinaal genomen beslissingen ertoe doen
Steeds vaker helpen machines bij het besturen van auto’s, het leiden van chirurgische instrumenten, het toezien op fabrieken en het inspecteren van kritieke infrastructuur. Al deze taken hangen af van software die data bekijkt en tussen opties kiest, zoals “veilig” of “onveilig.” Wanneer dat oordeel fout is, kan dat leiden tot een gemiste indringer, een verkeerd geïnterpreteerd verkeerslicht of een niet-gedetecteerd falend onderdeel. Dit artikel onderzoekt hoe zulke beslissingssoftware omringd kan worden met een extra beschermingslaag zodat risicovolle antwoorden worden gemarkeerd en tegengehouden in plaats van blind vertrouwd.
Van perfecte antwoorden naar betrouwbaar gedrag
Het meeste werk aan kunstmatige intelligentie probeert classifiers zo nauwkeurig mogelijk te maken, maar zelfs de beste systemen maken nog steeds fouten. Menselijke experts vergissen zich ook, toch vertrouwen we op hen omdat ze meestal weten wanneer ze hulp moeten vragen. De auteurs bepleiten dat machinale beslissers zich meer zo zouden moeten gedragen. In plaats van een classifier te dwingen altijd een label te kiezen, zou hij moeten kunnen zeggen “Ik weet het niet” en het grotere systeem veilig laten reageren. In de praktijk betekent dit dat onvoorspelbare foutieve antwoorden worden omgezet in gecontroleerde afwijzingen die andere delen van het systeem kunnen afhandelen, bijvoorbeeld door een voertuig te vertragen, een mens om input te vragen of over te schakelen naar een veiligere modus.
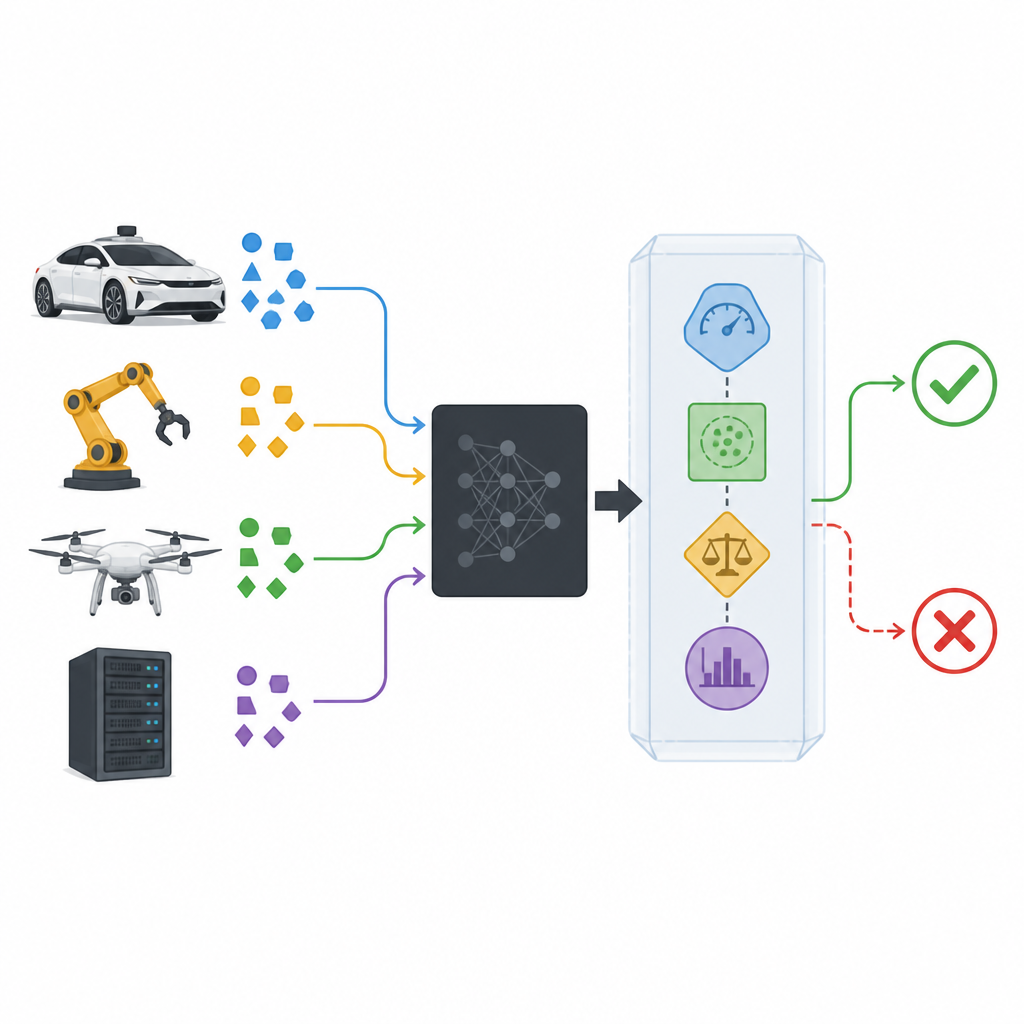
Een veiligheidswrapper rondom black-box-modellen toevoegen
Moderne classifiers worden vaak als black boxes behandeld: ze nemen data in en geven een voorspelling, terwijl hun interne werking verborgen blijft of te complex is om te inspecteren. De voorgestelde veiligheidswrapper, SPROUT genoemd, zit rond zo’n black box zonder erin te hoeven kijken. Hij observeert elke nieuwe invoer, de kansen die de classifier toekent aan mogelijke klassen, en hoe die invoer zich verhoudt tot eerdere data. Vanuit deze informatie beslist SPROUT of een voorspelling betrouwbaar genoeg lijkt om door te geven, of dat deze als verdacht moet worden geweigerd. Het belangrijkste punt is dat vrijwel elke bestaande classifier — voor beelden of tabeldata, binair of multi-klasse — op deze manier gewrapt kan worden zolang hij klassekansen kan uitgeven.
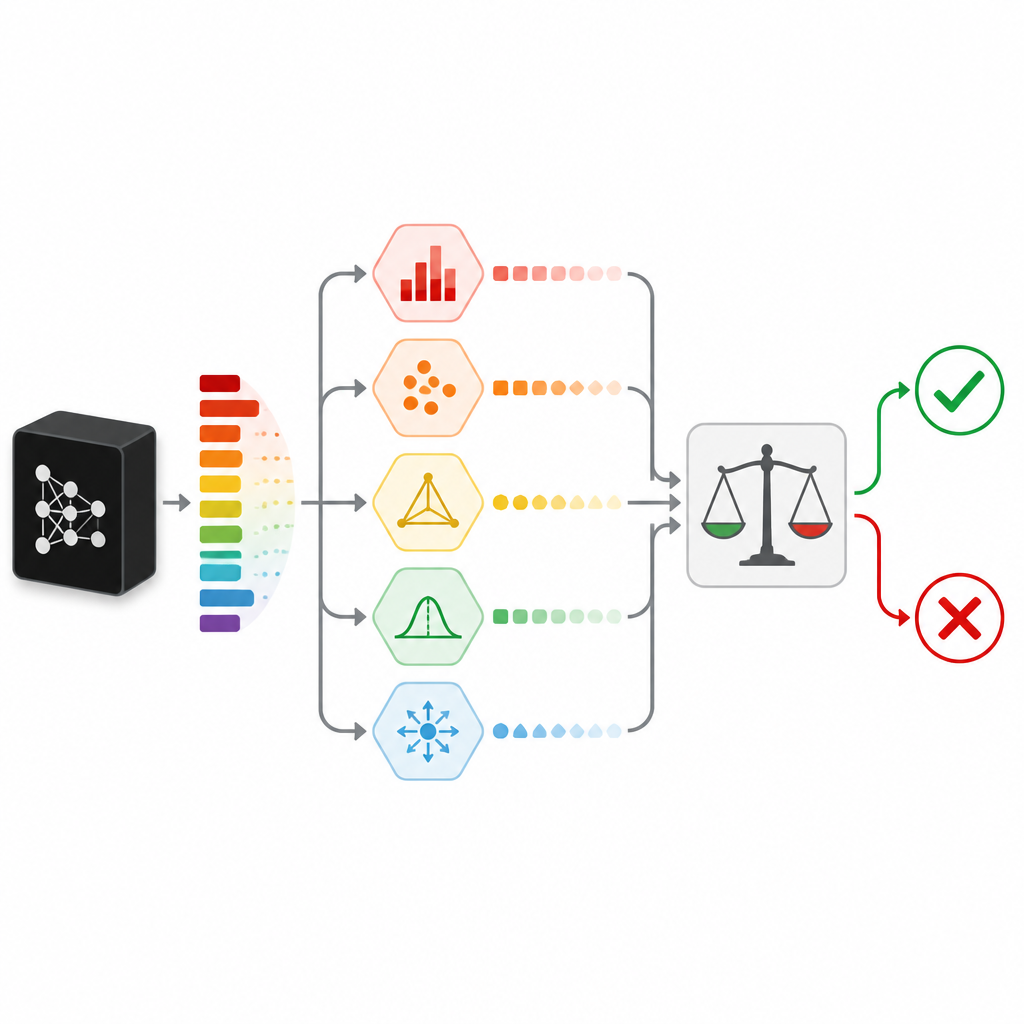
Twijfel op vele verschillende manieren meten
Om te beoordelen hoe zeker een voorspelling werkelijk is, vertrouwt SPROUT niet op één enkel signaal. In plaats daarvan combineert het meerdere “onzekerheidsmaatregelen” die elk twijfel vanuit een andere invalshoek bekijken. Sommige controleren eenvoudige tekenen, zoals of één klassekans echt uitspringt of dat de kansen gelijkmatig verdeeld zijn. Andere vergelijken het antwoord van de classifier met dat van extra “checker”-modellen die op dezelfde data zijn getraind, of met de antwoorden gegeven op nabije datapunten in de trainingsset. Een andere maatstaf probeert de invoer te reconstrueren met een autoencoder-netwerk en ziet een slechte reconstructie als een aanwijzing dat de nieuwe data afwijkend zijn. Samen vormen deze maatregelen een compact overzicht van getallen dat een klein tweede-niveau model, de adjudicator genoemd, omzet in een simpele bewaar-of-weiger-beslissing.
Testen over vele datasets en modeltypen
De auteurs voerden een grote experimentele studie uit met 35 publiek beschikbare datasets, die netwerkaanvallen, biometrische spoofing, hardwarestoringen, Internet of Things-sensoren en verschillende populaire beeldsets beslaan. Ze probeerden meer dan 20 typen classifiers, zowel supervised als unsupervised, en bouwden aparte SPROUT-opstellingen voor tabeldata en beelden. Voor elk geval maten ze hoe vaak de oorspronkelijke classifier fout zat en hoe vaak SPROUT erin slaagde die foute antwoorden te weigeren voordat ze konden ontsnappen. Voor veel supervised taken, inclusief sommige beeldproblemen, verlaagde SPROUT de resterende foutkans dramatisch. In bepaalde gevallen, zoals een logistieke regressie op een netwerkanalysedataset, wees het elke enkele misclassificatie af, waardoor een soms onbetrouwbare component veranderde in een component waarvan de outputs vertrouwd konden worden wanneer ze niet werden geweigerd.
Een balans tussen veiligheid, beschikbaarheid en kosten
Natuurlijk betekent het vangen van meer fouten vaak ook dat meer correcte antwoorden worden geweigerd, en het berekenen van veel onzekerheidsmaatregelen voegt tijds- en resource-overhead toe. De studie laat zien dat SPROUT supervised classifiers doorgaans ongeveer vier tot vijf keer trager maakt en dat sommige maatregelen duurder zijn dan andere. Dit suggereert een ontwerpafweging: veiligheidkritische systemen kunnen extra vertraging en meer weigeringen accepteren om schadelijke uitkomsten te vermijden, terwijl tijdkritische of resource-beperkte toepassingen kunnen kiezen voor een kleinere set goedkope controles. De auteurs identificeren ook welke maatregelen in de praktijk het belangrijkst zijn, wat aanwijzingen geeft over hoe lichtere versies kunnen worden gebouwd indien nodig.
Wat dit betekent voor veiliger AI in de praktijk
Kort gezegd is de hoofdboodschap van het artikel dat we moeten ophouden perfecte machinale beslissingen te verwachten en in plaats daarvan eisen dat onze systemen weten wanneer ze het mogelijk mis hebben. SPROUT biedt een praktisch stappenplan om bestaande black-box-classifiers te omhullen met een twijfelbewuste schild die verdachte outputs afwijst voordat ze schade veroorzaken. Hoewel deze bescherming extra rekenwerk en af en toe verlies van geldige voorspellingen met zich meebrengt, tonen de resultaten aan dat het de kans dat een gevaarlijke fout ongezien doorlekt sterk kan verkleinen, waardoor op AI gebaseerde besluitvorming betrouwbaarder wordt in de echte wereld.
Bronvermelding: Khokhar, F.A., Zoppi, T., Cennini, L. et al. Design, framework and benchmark of safety monitors for black-box classifiers. Sci Rep 16, 15626 (2026). https://doi.org/10.1038/s41598-026-45091-2
Trefwoorden: AI-veiligheid, onzekerheid, vertrouwwaardige AI, monitor voor machine learning, SPROUT-raamwerk