Clear Sky Science · de
Design, Rahmenwerk und Benchmark von Sicherheitsmonitoren für Black-Box-Klassifikatoren
Warum sichere maschinelle Entscheidungen wichtig sind
Immer öfter helfen Maschinen beim Fahren von Fahrzeugen, beim Führen chirurgischer Instrumente, bei der Überwachung von Fabriken und bei der Inspektion kritischer Infrastruktur. All diese Aufgaben beruhen auf Software, die Daten auswertet und zwischen Optionen wie „sicher“ oder „unsicher“ entscheidet. Fällt diese Einschätzung falsch, kann das Ergebnis ein übersehener Eindringling, eine falsch gelesene Ampel oder ein nicht erkannter defekter Bauteil sein. Dieser Artikel untersucht, wie man solche Entscheidungs‑Software mit einer zusätzlichen Schutzschicht umgibt, sodass riskante Antworten markiert und zurückgehalten werden, anstatt blind vertraut zu werden.
Von perfekten Antworten zu vertrauenswürdigem Verhalten
Die meisten Arbeiten zur künstlichen Intelligenz zielen darauf ab, Klassifikatoren so genau wie möglich zu machen, doch selbst die besten Systeme machen Fehler. Auch menschliche Expertinnen und Experten beurteilen Situationen falsch, dennoch vertrauen wir ihnen, weil sie meist wissen, wann sie um Hilfe bitten sollten. Die Autorinnen und Autoren argumentieren, dass sich maschinelle Entscheider ähnlich verhalten sollten. Statt einen Klassifikator dazu zu zwingen, immer ein Label zu wählen, sollte er „Ich bin mir nicht sicher“ sagen dürfen und so dem größeren System ermöglichen, sicher zu reagieren. In der Praxis bedeutet das, unvorhersehbare falsche Antworten in kontrollierte Ablehnungen zu verwandeln, die andere Systemteile handhaben können, etwa indem ein Fahrzeug verlangsamt, ein Mensch um Eingriff gebeten oder in einen sichereren Modus geschaltet wird.
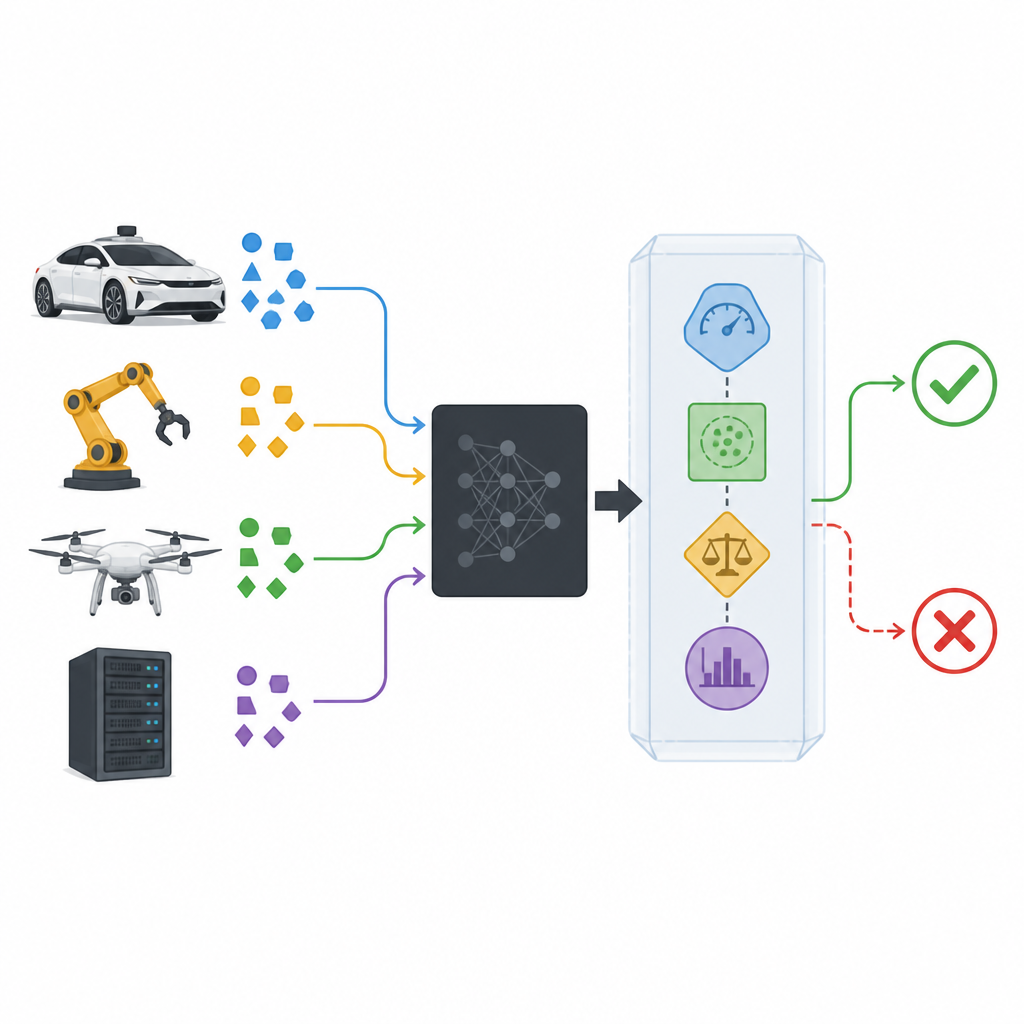
Ein Sicherheits‑Wrapper für Black‑Box‑Modelle
Moderne Klassifikatoren werden oft als Black Boxes behandelt: Sie nehmen Daten auf und geben eine Vorhersage aus, während ihr Innenleben verborgen oder zu komplex ist, um es zu analysieren. Der vorgeschlagene Sicherheits‑Wrapper, SPROUT genannt, umgibt eine solche Black Box, ohne hineinschauen zu müssen. Er beobachtet jeden neuen Eingang, die Wahrscheinlichkeiten, die der Klassifikator den möglichen Klassen zuordnet, und wie dieser Eingang im Vergleich zu früheren Daten steht. Aus diesen Informationen entscheidet SPROUT, ob eine Vorhersage vertrauenswürdig genug ist, um weitergegeben zu werden, oder ob sie als verdächtig abgelehnt werden sollte. Der Knackpunkt ist, dass nahezu jeder existierende Klassifikator — für Bilder oder tabellarische Daten, binär oder multi‑klassig — auf diese Weise umhüllt werden kann, sofern er Klassenwahrscheinlichkeiten ausgeben kann.
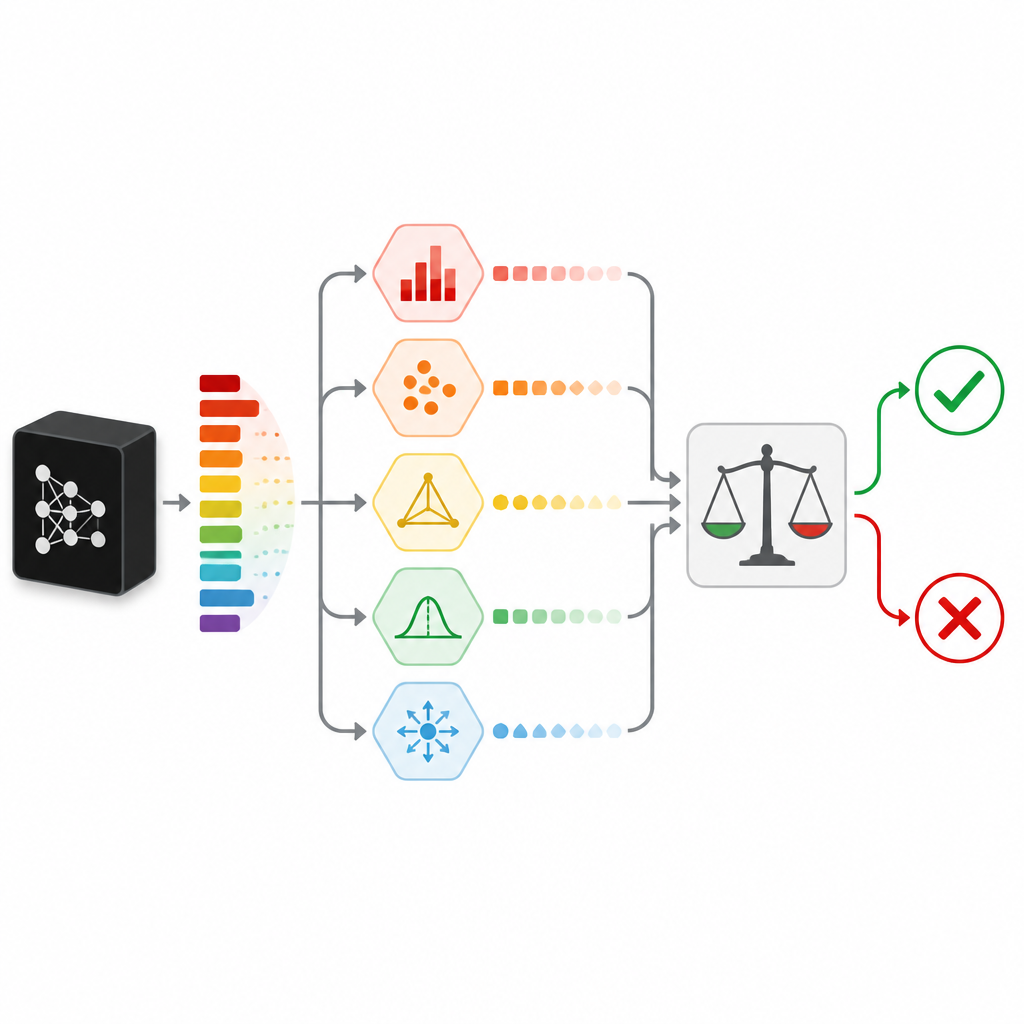
Zweifel auf viele Arten messen
Um zu beurteilen, wie sicher eine Vorhersage wirklich ist, verlässt sich SPROUT nicht auf ein einzelnes Signal. Stattdessen kombiniert es mehrere „Unsicherheitsmaße“, die jeden Zweifel aus einem anderen Blickwinkel betrachten. Einige prüfen einfache Anzeichen, etwa ob eine Klassenwahrscheinlichkeit deutlich herausragt oder ob die Wahrscheinlichkeiten gleichmäßig verteilt sind. Andere vergleichen die Antwort des Klassifikators mit der von zusätzlichen „Checker“-Modellen, die auf denselben Daten trainiert wurden, oder mit den Antworten für nahegelegene Datenpunkte im Trainingssatz. Ein weiteres Maß versucht, den Eingang mit einem Autoencoder-Netzwerk rekonstruiert wieder aufzubauen und wertet eine schlecht gelungene Rekonstruktion als Hinweis, dass die neuen Daten anders sind als alles zuvor Gesehene. Zusammen bilden diese Maße eine kompakte Zahlenmatrix, die ein kleines sekundäres Modell, der sogenannte Adjudicator, in eine einfache Behalte‑oder‑Ablehne‑Entscheidung umwandelt.
Tests über viele Datensätze und Modelltypen hinweg
Die Autorinnen und Autoren führten eine große experimentelle Studie mit 35 öffentlich verfügbaren Datensätzen durch, die Netzwerkangriffe, biometrisches Spoofing, Hardwarefehler, Sensoren des Internets der Dinge und mehrere populäre Bilddatensätze abdecken. Sie prüften mehr als 20 Arten von Klassifikatoren, sowohl überwachte als auch unüberwachte, und bauten separate SPROUT‑Setups für tabellarische Daten und Bilder. In jedem Fall maßen sie, wie oft der ursprüngliche Klassifikator falsch lag und wie oft SPROUT diese falschen Antworten ablehnen konnte, bevor sie entweichen. Für viele überwachte Aufgaben, einschließlich einiger Bildprobleme, reduzierte SPROUT die verbleibende Fehlerrate deutlich. In bestimmten Fällen, etwa bei einer logistischen Regression auf einem Netzwerksicherheitsdatensatz, lehnte es jede einzelne Fehlklassifikation ab und verwandelte so eine zeitweise unzuverlässige Komponente in eine, deren Ausgaben vertrauenswürdig sind, sofern sie nicht abgelehnt werden.
Sicherheit, Verfügbarkeit und Kosten abwägen
Naturgemäß bedeutet das Auffangen weiterer Fehler oft auch, mehr korrekte Antworten abzulehnen, und das Berechnen vieler Unsicherheitsmaße verursacht zusätzlichen Zeit‑ und Ressourcenaufwand. Die Studie zeigt, dass SPROUT überwachte Klassifikatoren typischerweise etwa vier- bis fünfmal langsamer macht und dass einige Maße kostenintensiver sind als andere. Das deutet auf einen Design‑Trade‑off hin: sicherheitskritische Systeme könnten zusätzliche Verzögerung und mehr Ablehnungen in Kauf nehmen, um schädliche Folgen zu vermeiden, während zeitkritische oder ressourcenbeschränkte Anwendungen eine kleinere Auswahl kostengünstiger Prüfungen wählen könnten. Die Autorinnen und Autoren identifizieren zudem, welche Maße in der Praxis am wichtigsten sind, und geben Hinweise, wie man bei Bedarf leichtere Versionen bauen kann.
Was das für praktischere, sicherere KI bedeutet
Vereinfacht gesagt lautet die Kernbotschaft des Papiers: Wir sollten aufhören, makellose maschinelle Entscheidungen zu erwarten, und stattdessen verlangen, dass unsere Systeme wissen, wann sie sich irren könnten. SPROUT bietet einen praktischen Bauplan, um bestehende Black‑Box‑Klassifikatoren mit einem zweifelbewussten Schutz zu umhüllen, der verdächtige Ausgaben ablehnt, bevor sie Schaden anrichten. Auch wenn dieser Schutz mit zusätzlicher Rechenlast und gelegentlichem Verlust gültiger Vorhersagen einhergeht, zeigen die Ergebnisse, dass er die Wahrscheinlichkeit drastisch senken kann, dass ein gefährlicher Fehler unbemerkt durchrutscht, und so KI‑gestützte Entscheidungsfindung in der realen Welt vertrauenswürdiger macht.
Zitation: Khokhar, F.A., Zoppi, T., Cennini, L. et al. Design, framework and benchmark of safety monitors for black-box classifiers. Sci Rep 16, 15626 (2026). https://doi.org/10.1038/s41598-026-45091-2
Schlüsselwörter: KI-Sicherheit, Unsicherheit, vertrauenswürdige KI, Machine-Learning-Monitor, SPROUT-Rahmenwerk