Clear Sky Science · fr
Conception, cadre et évaluation des moniteurs de sécurité pour classificateurs boîte noire
Pourquoi les décisions machine sûres comptent
De plus en plus, des machines aident à conduire des véhicules, guider des instruments chirurgicaux, surveiller des usines et inspecter des infrastructures critiques. Toutes ces tâches reposent sur des logiciels qui examinent des données et choisissent entre des options, par exemple « sûr » ou « dangereux ». Lorsqu’un tel jugement est erroné, les conséquences peuvent être un intrus manqué, un feu de signalisation mal interprété ou une pièce défaillante non détectée. Cet article examine comment entourer ce logiciel de décision d’une couche de protection supplémentaire afin que les réponses risquées soient signalées et retenues au lieu d’être aveuglément acceptées.
D’un résultat parfait à un comportement digne de confiance
La plupart des travaux en intelligence artificielle cherchent à rendre les classificateurs aussi précis que possible, mais même les meilleurs systèmes font encore des erreurs. Les experts humains se trompent aussi, pourtant nous continuons à leur faire confiance parce qu’ils savent généralement quand demander de l’aide. Les auteurs soutiennent que les systèmes de décision machine devraient se comporter davantage de la sorte. Plutôt que d’obliger un classificateur à choisir toujours une étiquette, il devrait pouvoir dire « je ne suis pas sûr » et laisser le système plus large réagir en sécurité. Concrètement, cela signifie transformer des réponses fausses et imprévisibles en rejets contrôlés que d’autres composants du système peuvent gérer, par exemple en ralentissant un véhicule, en sollicitant l’intervention d’un humain ou en basculant dans un mode plus sûr.
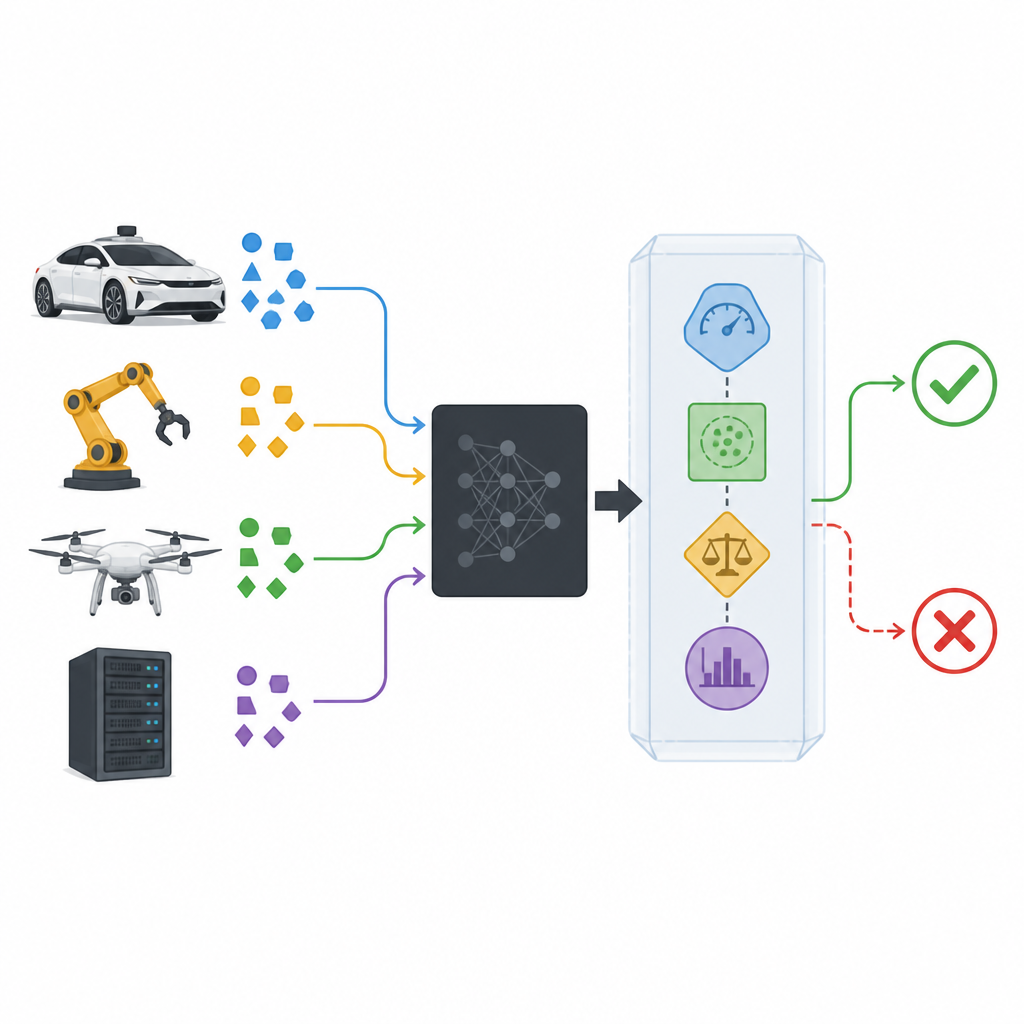
Ajouter une enveloppe de sécurité autour de modèles boîte noire
Les classificateurs modernes sont souvent traités comme des boîtes noires : ils reçoivent des données et produisent une prédiction, tandis que leur fonctionnement interne reste caché ou trop complexe à analyser. L’enveloppe de sécurité proposée, appelée SPROUT, s’installe autour d’une telle boîte noire sans avoir besoin d’en regarder l’intérieur. Elle surveille chaque nouvel exemple en entrée, les probabilités que le classificateur attribue aux classes possibles et la comparaison de cet exemple avec les données passées. À partir de ces informations, SPROUT décide si une prédiction semble suffisamment fiable pour être transmise ou si elle doit être rejetée comme suspecte. Le point clé est que presque tout classificateur existant, pour des images ou des tableaux de nombres, binaire ou multi-classe, peut être enveloppé de cette manière tant qu’il peut fournir des probabilités de classe.
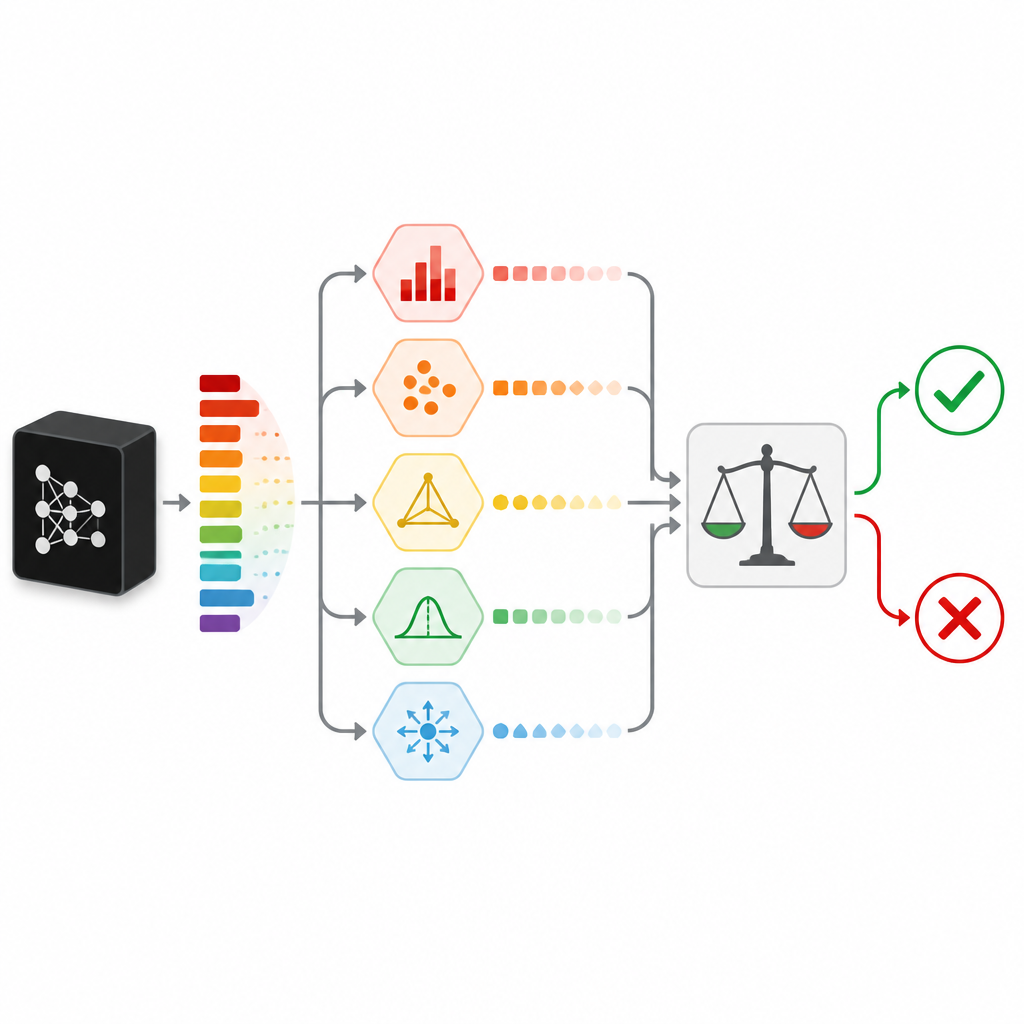
Mesurer le doute de bien des façons
Pour juger de la véritable confiance d’une prédiction, SPROUT ne s’appuie pas sur un signal unique. Il combine plusieurs « mesures d’incertitude » qui examinent chacune le doute sous un angle différent. Certaines vérifient des signes simples, comme si une probabilité de classe se démarque vraiment ou si les probabilités sont réparties uniformément. D’autres comparent la réponse du classificateur à celle de modèles « vérificateurs » supplémentaires entraînés sur les mêmes données, ou aux réponses données à des points de données proches dans l’ensemble d’entraînement. Une autre mesure tente de reconstruire l’entrée à l’aide d’un autoencodeur et interprète une mauvaise reconstruction comme un indice que les nouvelles données sont différentes de tout ce qui a été vu auparavant. Ensemble, ces mesures forment un tableau compact de nombres qu’un petit modèle de second niveau, appelé un arbitre, convertit en une simple décision conserver-ou-rejeter.
Tests sur de nombreux jeux de données et types de modèles
Les auteurs ont réalisé une grande étude expérimentale utilisant 35 jeux de données publics, couvrant des attaques réseau, des usurpations biométriques, des pannes matérielles, des capteurs Internet des objets et plusieurs ensembles d’images populaires. Ils ont essayé plus de 20 types de classificateurs, supervisés et non supervisés, et construit des configurations SPROUT distinctes pour les données tabulaires et les images. Pour chaque cas, ils ont mesuré la fréquence des erreurs du classificateur d’origine et la fréquence à laquelle SPROUT parvenait à rejeter ces réponses erronées avant qu’elles ne passent. Pour de nombreuses tâches supervisées, y compris certains problèmes d’image, SPROUT a réduit de manière spectaculaire le taux d’erreur résiduel. Dans certains cas, comme un modèle de régression logistique sur un jeu de données de sécurité réseau, il a rejeté toutes les classifications erronées, transformant un composant parfois peu fiable en un élément dont les sorties pouvaient être considérées comme dignes de confiance lorsqu’elles n’étaient pas rejetées.
Équilibrer sécurité, disponibilité et coût
Évidemment, attraper davantage d’erreurs signifie souvent rejeter aussi plus de réponses correctes, et le calcul de nombreuses mesures d’incertitude ajoute du temps et des ressources. L’étude montre que SPROUT rend généralement les classificateurs supervisés environ quatre à cinq fois plus lents et que certaines mesures sont plus coûteuses que d’autres. Cela suggère un compromis de conception : les systèmes critiques pour la sécurité peuvent accepter des délais supplémentaires et plus de rejets pour éviter des conséquences néfastes, tandis que les applications sensibles au temps ou limitées en ressources pourraient choisir un ensemble réduit de vérifications peu coûteuses. Les auteurs identifient également quelles mesures sont les plus pertinentes en pratique, offrant des indications sur la façon de concevoir des versions allégées lorsque c’est nécessaire.
Ce que cela signifie pour une IA plus sûre en pratique
En termes simples, le message principal de l’article est que nous devons cesser d’attendre des décisions machine impeccables et exiger plutôt que nos systèmes sachent quand ils pourraient se tromper. SPROUT offre une feuille de route pratique pour envelopper des classificateurs boîte noire existants d’un bouclier conscient du doute qui rejette les sorties suspectes avant qu’elles ne causent des dommages. Si cette protection entraîne un surcoût en calcul et une perte occasionnelle de prédictions valides, les résultats montrent qu’elle peut grandement réduire la probabilité qu’une erreur dangereuse passe inaperçue, rendant la prise de décision basée sur l’IA plus digne de confiance dans le monde réel.
Citation: Khokhar, F.A., Zoppi, T., Cennini, L. et al. Design, framework and benchmark of safety monitors for black-box classifiers. Sci Rep 16, 15626 (2026). https://doi.org/10.1038/s41598-026-45091-2
Mots-clés: Sécurité de l’IA, incertitude, IA digne de confiance, moniteur d’apprentissage automatique, cadre SPROUT