Clear Sky Science · ru
Безопасное управление на основе наблюдателя в смысле $$H_{\infty}$$ для сетевых систем управления с множественными возмущениями, отказами приводов и атаками обмана при адаптивном событийно-триггерном механизме
Как сохранять безопасность и устойчивость подключённых машин
Современные технологии опираются на сети датчиков, компьютеров и приводов, чтобы управлять всем — от роботизированных манипуляторов на заводах до автономных дронов и интеллектуальных энергетических систем. Эти сетевые системы управления могут быть эффективными и гибкими, но они также уязвимы: случайные внешние возмущения, изношенное оборудование и даже преднамеренные кибератаки способны вывести их из равновесия. В статье предлагается новый подход к поддержанию таких систем стабильными и надёжными, даже при одновременном воздействии множества проблем, при этом снижая объём передаваемых по сети данных.
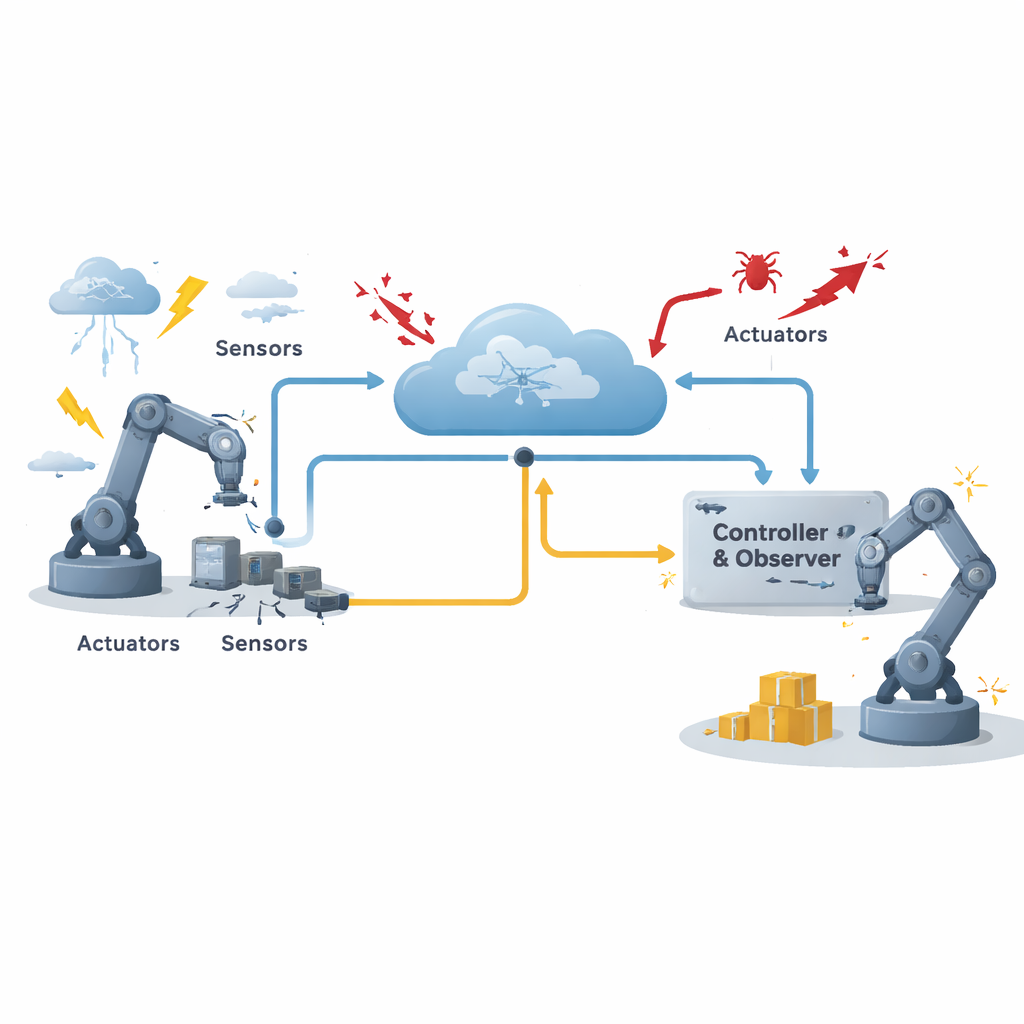
Почему защищать сетевые машины сложно
В типичной сетевой системе управления датчики измеряют поведение механизма, контроллер вычисляет требуемые действия, а приводы реализуют силы или движения — всё это соединено через общую коммуникационную сеть. Такой подход экономит прокладку кабелей, затраты и усилия по обслуживанию, но вводит новые риски. Сообщения могут задерживаться или теряться, устройства выходить из строя, а злоумышленники вмешиваться в передаваемые данные. Авторы сосредотачивают внимание на особенно опасном типе киберугроз — атаках обмана, при которых в систему вводятся ложные сигналы, и контроллер «видит» искаженную картину. Одновременно система подвергается двум типам возмущений: одни можно грубо смоделировать, например предсказуемые вибрации, тогда как другие хаотичны и трудно поддаются априорному описанию. Приводы сами по себе могут частично или полностью отказывать из‑за износа или перегрузок.
Наблюдение скрытых возмущений в реальном времени
Чтобы справиться с этими неопределённостями, исследователи разработали специальный программный компонент — наблюдатель. Вместо того чтобы полагаться только на прямые показания датчиков, наблюдатель воспроизводит скрытые возмущения, сравнивая ожидаемое поведение системы с фактическими измерениями. Он оценивает, какая часть наблюдаемого движения вызвана известными воздействиями, а какая — неизвестными нарушениями. Эта оценка передаётся контроллеру, который использует её для максимально возможного компенсирования возмущений. Проще говоря, система учится отличать собственные преднамеренные действия от «шума» из окружающей среды или от злонамеренного вмешательства и затем активно противодействует этому шуму.
Передавать данные только когда это важно
Постоянная передача каждого показания датчика может перегрузить общую сеть, особенно при большом числе устройств, конкурирующих за пропускную способность. Чтобы экономить ресурсы, авторы вводят адаптивный событийно-триггерный механизм. Вместо передачи данных через фиксированные интервалы система отслеживает, насколько текущее показание отличается от последнего переданного. Динамический порог решает, достаточно ли велика разница, чтобы оправдать новую отправку. Этот порог не фиксирован: он сам подстраивается по простому правилу обновления на основе недавнего поведения, так что в спокойные периоды система отправляет очень мало обновлений, а при быстрых или непредсказуемых изменениях — становится более разговорчивой. Важно, что механизм спроектирован с учётом устойчивости к атакам обмана, которые пытаются внедрить искажённые данные; условие срабатывания учитывает как сетевые ошибки, так и возможные сигналы атаки.
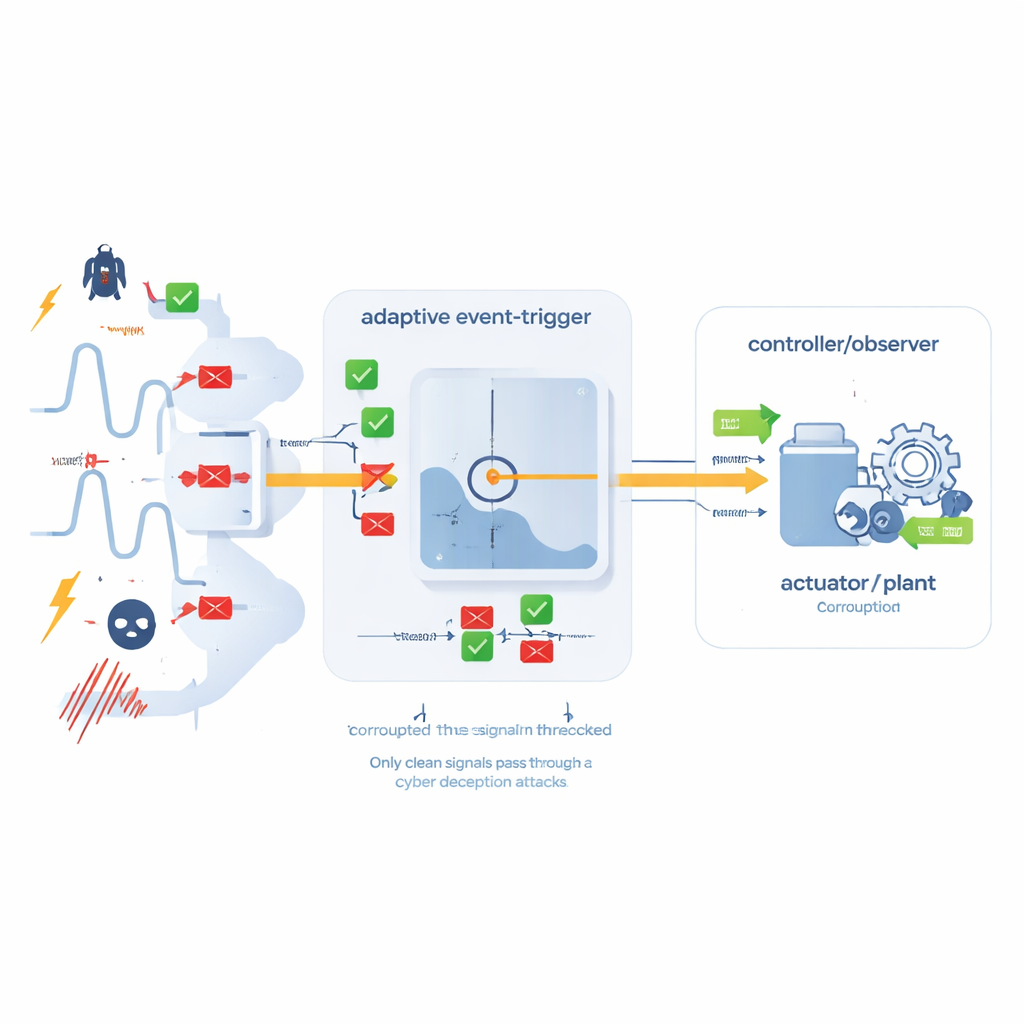
Математические гарантии и тестовые примеры
За этой стратегией стоит тщательный математический анализ. Авторы моделируют случайные отказы приводов и кибератаки с помощью стандартных вероятностных инструментов, затем строят специальную энерго‑подобную функцию для отслеживания эволюции системы во времени. Через введение набора матричных неравенств они выводят условия, при которых объединённые наблюдатель, контроллер и правила событийной передачи обеспечивают устойчивость системы и ограничивают влияние возмущений до заданного уровня. Далее они испытывают свою схему на двух примерах: на типовой эталонной системе и на однозвенной роботизированной руке, подверженной временным задержкам, возмущениям, атакам на канал связи и случайным отказам приводов. В обоих случаях неуправляемая система становилась неустойчивой, тогда как предложенный метод быстро возвращал движение к нулю и удерживал его там.
Что это означает для систем в реальном мире
Исследование показывает, что можно разработать управляющие схемы, одновременно защищённые и экономные по использованию сети, без ущерба для характеристик. Объединяя наблюдение возмущений, отказоустойчивость и адаптивную передачу данных в единую структуру, метод предоставляет набор инструментов для будущих киберфизических систем, которые должны работать безопасно в враждебной или неопределённой среде. Для инженеров, создающих промышленных роботов, интеллектуальные сети или автономные транспортные средства, этот подход предлагает способ сохранять устойчивость машин даже при неправильной работе некоторых компонентов и при попытках атакующих ввести контроллер в заблуждение, одновременно снижая нагрузку на связь и экономя энергию.
Цитирование: Tajudeen, M.M., Banu, K.A., Tatar, Ne. et al. Observer-based secure \(H_{\infty }\) control for networked control systems with multiple disturbances, actuator failures, and deception attacks under adaptive event-triggered mechanism. Sci Rep 16, 10092 (2026). https://doi.org/10.1038/s41598-026-36662-4
Ключевые слова: сетевые системы управления, безопасность киберфизических систем, событийно-триггерное управление, отказы исполнительных устройств, подавление возмущений