Clear Sky Science · it
Controllo sicuro basato su osservatore $$H_{\infty }$$ per sistemi di controllo in rete con disturbi multipli, guasti agli attuatori e attacchi di deception sotto un meccanismo adattivo a eventi
Mantenere sicure e stabili le macchine connesse
La tecnologia moderna fa affidamento su reti di sensori, calcolatori e attuatori per far funzionare tutto, dai bracci robotici in fabbrica ai droni autonomi e ai sistemi energetici intelligenti. Questi sistemi di controllo in rete possono essere efficienti e flessibili, ma sono anche vulnerabili: disturbi casuali dall’ambiente, componenti usurati e perfino attacchi informatici deliberati possono farli perdere l’equilibrio. Questo articolo presenta un nuovo modo per mantenere tali sistemi stabili e affidabili, anche quando sono soggetti a molteplici problemi contemporaneamente, riducendo al contempo la quantità di dati da trasmettere in rete.
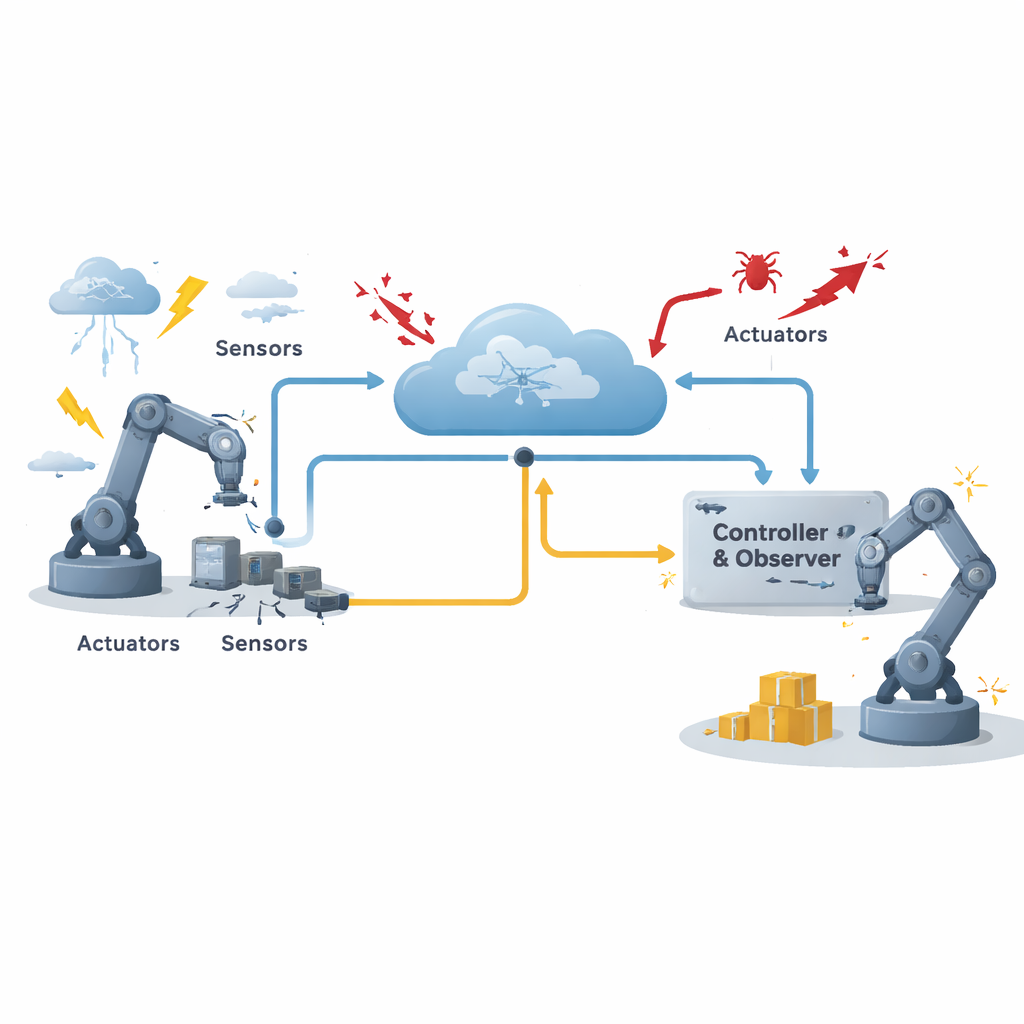
Perché è difficile proteggere le macchine in rete
In un tipico sistema di controllo in rete, i sensori misurano il comportamento di una macchina, un controllore calcola cosa fare e gli attuatori applicano forze o movimenti, il tutto collegato tramite una rete di comunicazione condivisa. Questa configurazione riduce cablaggi, costi e sforzi di manutenzione, ma introduce nuovi rischi. I messaggi possono subire ritardi o essere persi, i dispositivi possono guastarsi e attori ostili possono manomettere i dati in transito. Gli autori si concentrano su un tipo particolarmente pericoloso di minaccia informatica chiamata attacco di deception, in cui vengono iniettati segnali falsi in modo che il controllore «veda» un quadro ingannevole del sistema. Allo stesso tempo, la macchina affronta due tipi di disturbi: alcuni possono essere modellati approssimativamente, come vibrazioni prevedibili, mentre altri sono caotici e difficili da descrivere a priori. Anche gli attuatori possono fallire parzialmente o completamente a causa di usura o sovraccarico.
Osservare le perturbazioni nascoste in tempo reale
Per far fronte a queste incertezze, i ricercatori progettano un componente software speciale chiamato osservatore. Invece di fare affidamento solo sulle letture dirette dei sensori, l’osservatore ricostruisce le perturbazioni nascoste confrontando il comportamento previsto del sistema con quanto effettivamente misurato. Stima quindi quanto del moto osservato sia dovuto a influenze note e quanto a disturbi sconosciuti. Questa stima viene fornita al controllore, che la usa per cancellare l’effetto delle perturbazioni il più possibile. In termini semplici, il sistema impara a distinguere tra le proprie azioni volute e il «rumore» proveniente dall’ambiente o da interferenze malevole, e quindi si oppone attivamente a quel rumore.
Trasmettere dati solo quando è importante
Trasmettere continuamente ogni lettura dei sensori può sovraccaricare una rete condivisa, specialmente quando molti dispositivi competono per la larghezza di banda. Per risparmiare risorse, gli autori introducono un meccanismo adattivo a eventi. Invece di inviare dati a intervalli di tempo fissi, il sistema monitora quanto la lettura corrente differisce dall’ultima trasmessa. Una soglia dinamica decide se la variazione è sufficientemente importante da giustificare un nuovo messaggio. Questa soglia non è fissa: si autoregola mediante una semplice regola di aggiornamento basata sul comportamento recente, in modo che durante periodi di calma il sistema invii pochissimi aggiornamenti, mentre durante cambiamenti rapidi o imprevedibili diventi più loquace. È importante che questo meccanismo sia progettato per essere robusto anche contro attacchi di deception che tentano di introdurre dati alterati; la condizione di triggering tiene conto sia degli errori di rete sia dei possibili segnali d’attacco.
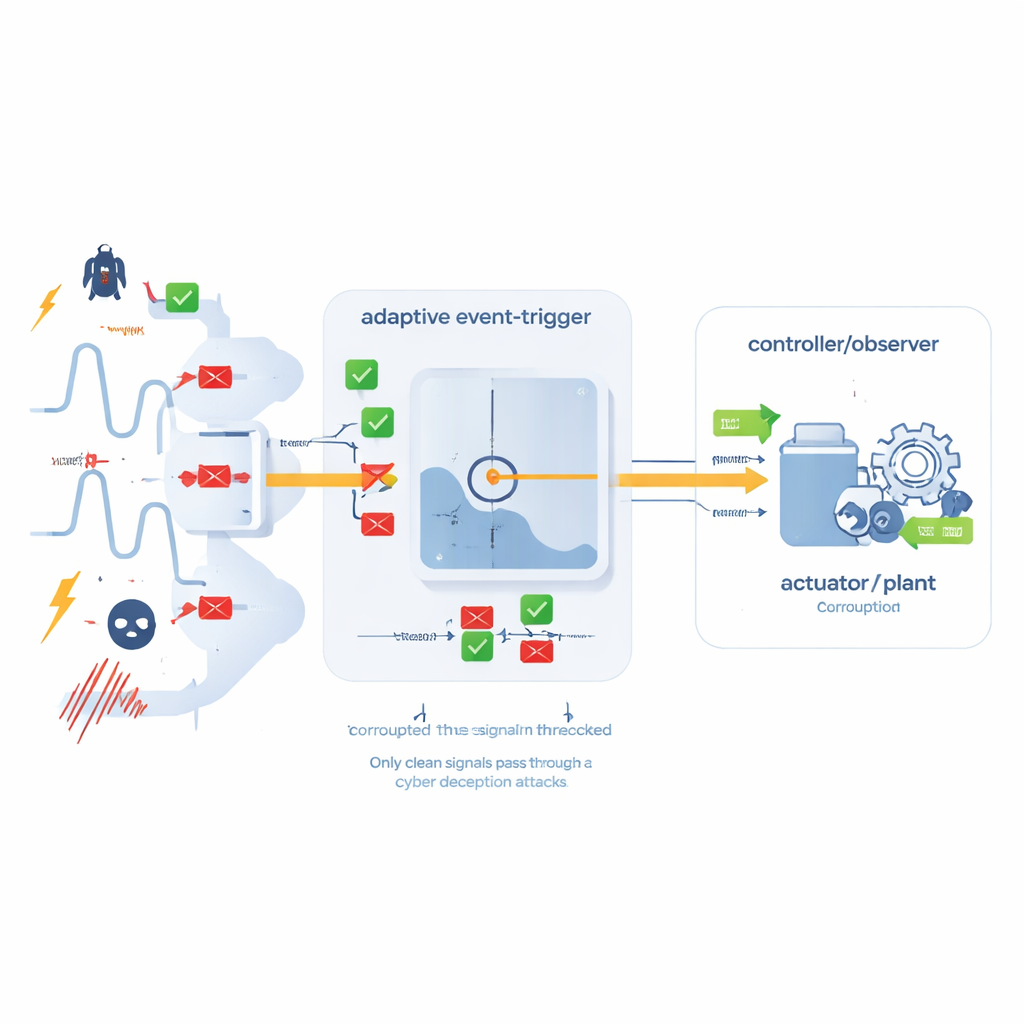
Garanzie matematiche e casi di prova
Dietro questa strategia c’è un’attenta analisi matematica. Gli autori modellano guasti casuali agli attuatori e attacchi informatici usando strumenti probabilistici standard, quindi costruiscono una funzione speciale simile all’energia per tracciare l’evoluzione del sistema nel tempo. Impedendo un insieme di disuguaglianze matriciali, ricavano condizioni sotto le quali l’osservatore, il controllore e le regole di triggering mantengono il sistema stabile e limitano l’impatto delle perturbazioni a un livello prefissato. Testano poi il loro progetto su due esempi: un sistema benchmark generico e un braccio robotico a singolo giunto soggetto a ritardi variabili nel tempo, disturbi, attacchi sul canale di comunicazione e guasti casuali agli attuatori. In entrambi i casi, il sistema non controllato diventa instabile, mentre il metodo proposto riporta rapidamente i moti verso lo zero e li mantiene lì.
Che cosa significa per i sistemi del mondo reale
Lo studio dimostra che è possibile progettare schemi di controllo che siano al tempo stesso sicuri e parsimoniosi nell’uso della rete, senza sacrificare le prestazioni. Combinando osservazione delle perturbazioni, tolleranza ai guasti e trasmissione adattiva dei dati in un unico quadro, il metodo fornisce una cassetta degli attrezzi per i futuri sistemi cibernetico-fisici che devono operare in ambienti ostili o incerti. Per gli ingegneri che costruiscono robot industriali, smart grid o veicoli autonomi, questo approccio offre un modo per mantenere le macchine stabili anche quando alcune parti si comportano male e quando gli attaccanti cercano di fuorviare la logica di controllo, il tutto riducendo il carico di comunicazione e risparmiando energia.
Citazione: Tajudeen, M.M., Banu, K.A., Tatar, Ne. et al. Observer-based secure \(H_{\infty }\) control for networked control systems with multiple disturbances, actuator failures, and deception attacks under adaptive event-triggered mechanism. Sci Rep 16, 10092 (2026). https://doi.org/10.1038/s41598-026-36662-4
Parole chiave: sistemi di controllo in rete, sicurezza cibernetica-fisica, controllo a eventi, guasti agli attuatori, reiezione delle perturbazioni