Clear Sky Science · ru
Сжатие коллективных знаний ESM в одну белковую языковую модель
Почему важно объединить множество белковых моделей в одну
У каждого человека есть миллионы небольших отличий в ДНК, многие из которых меняют отдельные строительные блоки в белках. Большинство таких изменений безвредны, но некоторые могут приводить к заболеваниям. Врачи и исследователи хотят иметь быстрый и точный способ отличать одни изменения от других, опираясь только на последовательность белка. В этой статье описана новая стратегия, которая собирает коллективный опыт множества существующих белковых «языковых моделей» и сжимает его в одну эффективную систему, сопоставимую или превосходящую современные лучшие инструменты для оценки влияния генетических изменений.
От чтения предложений к чтению белков
Белковые языковые модели заимствуют идеи из технологий, лежащих в основе современных систем перевода и чатов. Вместо изучения слов в предложении они ищут закономерности в строках аминокислот — «буквах» белковых последовательностей. Обучаясь на сотнях миллионов природных белков, эти модели улавливают сигналы о том, какие позиции строго консервативны, а какие допускают изменения. Эти закономерности затем можно использовать для оценки генетических вариантов: если замена нарушает паттерн, который эволюция сильно сохраняет, она с большей вероятностью будет вредной. До сих пор самые сильные методы сочетали такие модели с дополнительной информацией, например 3D‑структурой или эволюционными деревьями, что делало их мощными, но сложными и не всегда удобными для широкого применения.
Когда модели учат друг друга
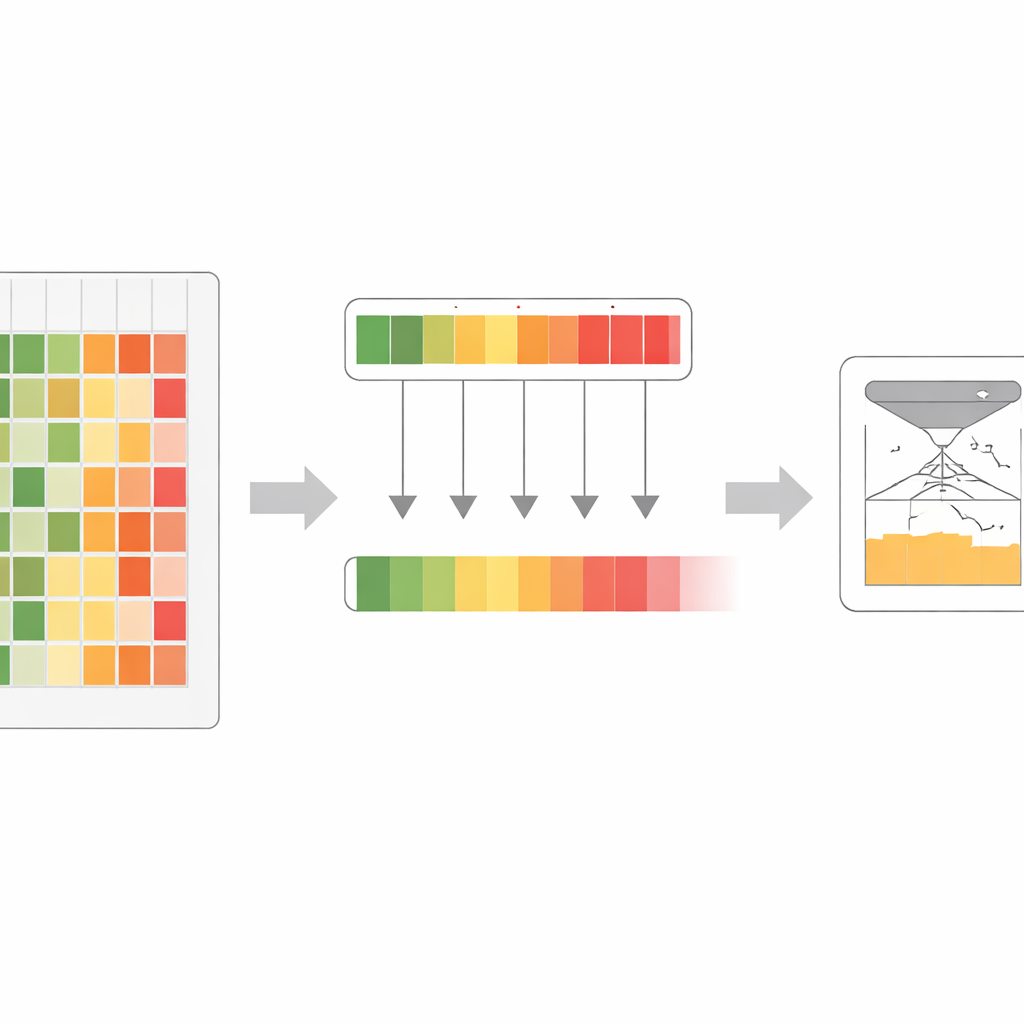
Авторы отметили, что разные белковые языковые модели, даже обученные на схожих данных, имеют свои сильные стороны и слепые зоны. Одна модель может особенно хорошо находить чувствительные участки в одной семейства белков, тогда как другая превосходит её в другом месте. Вместо простого усреднения мнений команда предложила правило «максимальной уверенности»: для каждой возможной замены белка они просматривают всю группу моделей и выбирают ту оценку, в которой модель наиболее уверена, что изменение вредно. Этот шаг даёт обогащённый набор оценок, который фиксирует самые сильные эволюционные предупреждения от любой модели в ансамбле, вместо того чтобы их размывать.
Сведение многих голосов к одному
Работая с этим обогащённым сигналом, исследователи разработали процесс обучения, который называют со‑дистилляцией. В нём все исходные модели многократно тренируются, пытаясь соответствовать сильнейшему объединённому сигналу, попеременно выступая «учеником» и «учителем» в зависимости от того, где каждая наиболее уверена. На ранних этапах правило максимальной уверенности помогает выявить тонкие, но важные паттерны, которые некоторые модели пропустили. На более поздних этапах более мягкое усреднение помогает моделям прийти к согласию и сгладить шум. Через несколько циклов одна крупная модель постепенно поглощает почти всю полезную информацию, ранее распределённую по ансамблю. Эта итоговая модель, названная VESM‑3B, затем используется для обучения уменьшенных версий, которые работают достаточно быстро для больших генетических наборов данных, сохраняя при этом основную точность.
Превосходство сложных систем при помощи только последовательностей
Несмотря на использование в качестве входа только сырых белковых последовательностей, модели VESM сопоставимы или превосходят сложных конкурентов, которые также опираются на 3D‑структуры, вручную построенные эволюционные истории или данные из популяций людей. На клинических бенчмарках, взятых из базы ClinVar с вариантами, связанными с болезнями, основная модель VESM показывает результаты лучше многих широко используемых инструментов и даже превосходит AlphaMissense — недавнюю заметную систему, объединяющую структуру и популяционные данные. Важно, что производительность VESM сохраняется для очень редких вариантов — тех, с которыми клиницисты испытывают наибольшие трудности интерпретации. Модели также превосходно работают по лабораторным измерениям, тестирующим, как мутации влияют на пригодность белка, стабильность и связывание, и способны отслеживать величину и направление эффектов вариантов по реальным клиническим признакам в больших биобанках.
Что это означает для генетики и медицины
Тщательно объединяя и оттачивая сильные стороны множества последовательных моделей, эта работа демонстрирует, что сами по себе сырые белковые последовательности могут нести достаточно сигнала для прогнозирования влияния генетических изменений на современном уровне. В результате получилась семейство инструментов, которые проще развёртывать, чем системы, требующие структуры или больших объёмов дополнительных данных, при этом оставаясь высокоточными для белков человека, микроорганизмов и вирусов. Для клиницистов и исследователей это означает более быструю и надёжную сортировку ДНК‑вариантов, ясное представление о том, насколько сильно изменение может влиять на признаки, связанные с болезнью, и практический способ внедрить мощные предсказательные модели в повседневные рабочие процессы генетики и дизайна белков.
Цитирование: Dinh, T., Jang, SK., Zaitlen, N. et al. Compressing the collective knowledge of ESM into a single protein language model. Nat Methods 23, 772–784 (2026). https://doi.org/10.1038/s41592-026-03050-9
Ключевые слова: языковые модели белков, предсказание эффектов вариантов, генетические варианты, эволюционные сигналы, клиническая геномика