Clear Sky Science · ja
複数のESMの知見を単一のタンパク質言語モデルに凝縮する
多くのタンパク質モデルを一つにまとめることがなぜ重要か
私たち一人ひとりのDNAには何百万もの小さな違いがあり、その多くはタンパク質の一つの構成要素を変えます。ほとんどの変化は無害ですが、中には疾患を引き起こすものもあります。医師や研究者は、タンパク質配列だけを使ってどの変化が有害かを素早く正確に判断する手段を強く求めています。本稿は、多数の既存のタンパク質「言語モデル」が持つ集合的知見を取り出し、それを単一で効率的なシステムに圧縮する新しい戦略を示します。これにより、遺伝変化の影響を判定する既存の最良ツールに匹敵するかそれを上回る性能が得られます。
文章を読むことからタンパク質を読むことへ
タンパク質言語モデルは、現代の翻訳やチャットシステムの技術からアイデアを借用しています。文中の単語を学ぶ代わりに、アミノ酸の並び—タンパク質配列の文字—の中のパターンを学習します。何億という天然タンパク質で学習することで、どの位置が高度に保存され変化に敏感か、どの位置が変化を許容するかといったシグナルを獲得します。これらのパターンは遺伝変異のスコアリングに用いられます。進化が強く保護しているパターンを壊す変化は、有害である可能性が高いのです。これまでは、最も強力な手法は3次元構造や進化系統などの追加情報とこれらのモデルを組み合わせており、強力ではあるものの複雑で広く適用するのが難しいことがありました。
モデル同士に教えさせる
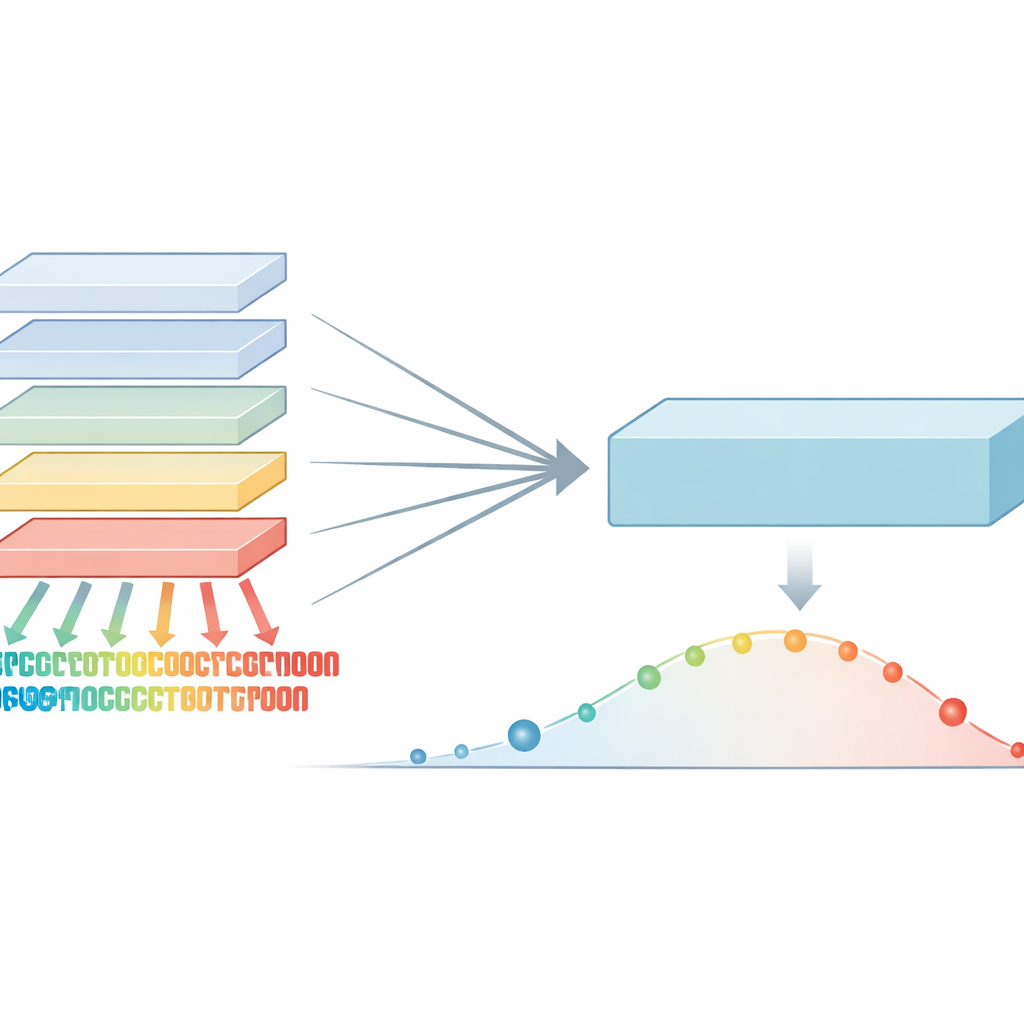
著者らは、類似のデータに基づいて構築されたモデルであっても、それぞれ異なる強みと盲点を持っていることに気づきました。あるモデルは特定のタンパク質ファミリーの敏感な領域を見抜くのが得意でも、別のモデルは別の領域で優れているかもしれません。単に意見を平均化する代わりに、チームは「最大確信」ルールを導入しました。可能なすべてのタンパク質変化について、モデル群全体を参照し、その変化が有害であると最も確信しているモデルの評価を採用します。このステップにより、どのモデルにも存在する最も強い進化的警告シグナルを捉え、平均化で埋もれてしまうことを防いだ強化されたスコア群が得られます。
多くの声を一つに煮詰める
この強化されたシグナルをもとに、研究者たちは共蒸留(co-distillation)と呼ぶ学習プロセスを設計しました。ここでは、元のすべてのモデルが繰り返しその最強の結合シグナルに合わせる練習を行い、各モデルは自分が最も確信している領域に応じて「生徒」や「教師」を交替します。初期のラウンドでは、最大確信ルールが一部のモデルが見逃していた微妙だが重要なパターンを浮かび上がらせます。後半のラウンドでは、より穏やかな平均化がモデル間の合意を促しノイズをならします。数サイクルを経て、1つの大きなモデルがアンサンブル全体に分散していた有用な情報のほとんどを徐々に吸収します。この最終モデルはVESM‑3Bと名付けられ、さらにその後、精度の大部分を保ちながら大量の遺伝データを扱えるほど高速に動く小型版の学習にも使われます。
配列だけで複雑なシステムを超える
生のタンパク質配列のみを入力としながら、VESMモデルは3次元構造や手作りの進化履歴、人間集団データを併用する高度な競合手法に匹敵するかそれを上回ります。ClinVarの疾患変異から取られた臨床ベンチマークでは、主要なVESMモデルは広く用いられる多くのツールを凌ぎ、構造と集団データを組み合わせた最近の注目システムAlphaMissenseに迫るか上回る結果を示しました。重要なのは、VESMの性能が臨床で解釈が特に難しい非常に稀な変異でも維持される点です。さらに、これらのモデルは変異がタンパク質の適合度、安定性、結合に与える影響を測る実験データでも優れ、また大規模バイオバンクの臨床形質に対する変異効果の大きさと方向を追跡することもできます。
遺伝学と医学にとっての意義
多くの配列モデルの強みを慎重に組み合わせ洗練することで、本研究は生のタンパク質配列だけでも遺伝変化の影響を最先端レベルで予測するのに十分なシグナルを含むことを示しました。その成果は、構造重視や大量データを要するシステムよりも展開が容易でありながら、人間・微生物・ウイルスを含む多様なタンパク質で高精度を維持するツール群です。臨床医や研究者にとって、これはDNA変異のより迅速で信頼できる一次選別、変化が疾患関連形質にどれほど影響するかの明確な見立て、そして強力な予測モデルを日常的な遺伝学やタンパク質設計のワークフローに実用的に導入する道を意味します。
引用: Dinh, T., Jang, SK., Zaitlen, N. et al. Compressing the collective knowledge of ESM into a single protein language model. Nat Methods 23, 772–784 (2026). https://doi.org/10.1038/s41592-026-03050-9
キーワード: タンパク質言語モデル, 変異の影響予測, 遺伝的変異, 進化的シグナル, 臨床ゲノミクス