Clear Sky Science · pt
Completação de grafos de conhecimento com poucos exemplos baseada em meta‑aprendizado e agregação por domínio selecionado
Por que ensinar máquinas com apenas alguns exemplos é importante
Sistemas modernos de inteligência artificial dependem cada vez mais de vastos “grafos de conhecimento” que conectam pessoas, lugares, coisas e ideias em enormes redes de fatos. Esses grafos alimentam mecanismos de busca, sistemas de recomendação e ferramentas de perguntas e respostas. Mas, no mundo real, muitas conexões nesses grafos são raras, mal documentadas ou recém‑surgidas. Ensinar uma máquina a reconhecer e completar esses links raros quando existem apenas alguns exemplos é uma tarefa difícil. Este artigo apresenta um método que ajuda a IA a aprender com pouquíssimas amostras enquanto filtra informações distraidoras, permitindo que ela estime com mais precisão fatos ausentes em um grafo de conhecimento.
Mapas de conhecimento formados por fatos simples
Um grafo de conhecimento representa informação como declarações simples de três partes, por exemplo “pessoa A trabalha_para empresa B” ou “cidade C está_em país D.” Cada declaração vincula duas entidades por meio de uma relação, e milhões desses vínculos juntos formam um mapa de conhecimento. Técnicas tradicionais transformam cada entidade e relação em vetores num espaço matemático e então aprendem regras que permitem ao sistema prever novos links. Essas técnicas funcionam bem quando há muitos exemplos para cada relação, como “nascido_em” ou “localizado_em,” mas falham quando uma relação aparece apenas algumas vezes nos dados. Na prática, relações raras são comuns — por exemplo, uma condição médica específica, um título de trabalho de nicho ou uma parceria recém‑formada — portanto melhorar o desempenho nesses casos de “few‑shot” é crucial.
Aprender com vizinhos sem se perder no ruído
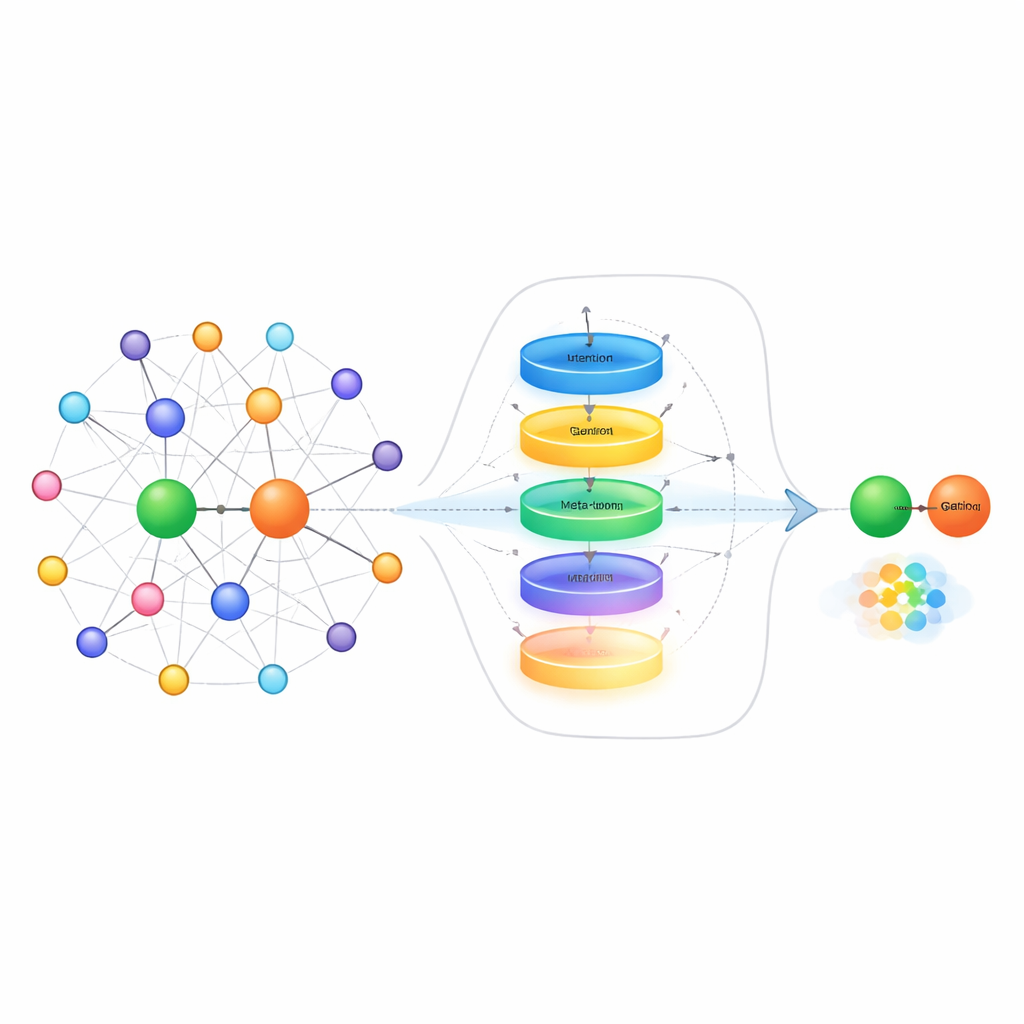
Uma forma de lidar com exemplos escassos é olhar para os “vizinhos” de cada entidade no grafo — os outros fatos diretamente conectados a ela. Por exemplo, ao tentar prever o cônjuge de alguém, é mais útil conhecer seus familiares do que seus parceiros comerciais. Métodos existentes frequentemente tratam todos os fatos próximos como igualmente úteis, o que pode abafar as pistas realmente relevantes com ruído. Os autores propõem um módulo de seleção de vizinhança que primeiro pontua cada vizinho segundo sua relevância, mantém apenas os de maior pontuação e então usa um mecanismo de gating inspirado em redes recorrentes para decidir quanto dessa informação dos vizinhos deve realmente atualizar a representação da entidade. Esse processo em duas etapas tanto filtra vizinhos fora do tópico quanto equilibra dinamicamente o que lembrar e o que ignorar, sendo especialmente útil quando há apenas alguns exemplos de treinamento disponíveis.
Ensinar o sistema a aprender novas relações
Além de limpar a informação da vizinhança, o método também aborda como o sistema representa as próprias relações quando vê apenas alguns exemplos de links. Em vez de simplesmente fazer a média dessas amostras, os autores constroem um “meta‑aprendizador” de relações. Ele trata todos os pares de exemplo para uma dada relação como uma pequena sequência e os passa por uma unidade recorrente com portas (GRU) para captar padrões entre as amostras. Um mecanismo de atenção contextual permite ao modelo focar mais nos pares mais informativos, enquanto uma pequena rede feed‑forward refina ainda mais o sinal combinado. Conexões residuais e normalização ajudam a estabilizar o aprendizado. O resultado é uma representação compacta e sensível à tarefa da relação, que captura diferenças sutis em como as entidades interagem, como direção, intensidade ou tipo de conexão.
Aprender a adaptar-se rapidamente com meta‑otimização
A peça final da abordagem é um aprendiz de embeddings que usa ideias de meta‑aprendizado — frequentemente chamado de “aprender a aprender.” Durante o treinamento, o sistema vê muitas relações diferentes como tarefas pequenas e separadas. Para cada tarefa, ele adapta brevemente seus parâmetros usando apenas os poucos exemplos disponíveis e então verifica quão bem se sai em novas consultas para aquela relação. Os gradientes desse segundo passo atualizam um conjunto compartilhado de parâmetros de modo que, ao longo do tempo, o modelo se torna melhor em adaptar‑se rapidamente a relações totalmente novas que nunca viu antes. O método se baseia em uma técnica existente que posiciona entidades em superfícies geométricas específicas para cada relação, e atualiza tanto a representação da relação quanto essas superfícies durante o meta‑aprendizado, afinando ainda mais suas previsões.
O que os resultados significam para ferramentas de IA do dia a dia
Os autores testam seu método em dois conjuntos de referência amplamente usados, NELL‑One e Wiki‑One, e o comparam com muitos sistemas de ponta para compleção de grafos de conhecimento com poucos exemplos. Em várias métricas de avaliação, sua abordagem apresenta desempenho consistentemente melhor, particularmente quando há cinco links de exemplo por relação. Os ganhos são mais pronunciados em um conjunto de dados onde a informação dos vizinhos é mais rica, ressaltando o valor da seleção cuidadosa de vizinhos e do meta‑aprendizado de relações. Para aplicações cotidianas, isso significa que sistemas de IA poderiam completar de forma mais confiável partes faltantes do conhecimento — como relações raras, conceitos especializados ou fatos emergentes — mesmo quando há apenas um pequeno número de exemplos disponíveis, tornando ferramentas a jusante como busca, recomendação e perguntas e respostas mais precisas e robustas.
Citação: Yang, B., Peng, M., Liu, S. et al. Meta learning based few shot knowledge graph completion with domain selected aggregation. Sci Rep 16, 12333 (2026). https://doi.org/10.1038/s41598-026-42198-4
Palavras-chave: grafos de conhecimento, aprendizado com poucos exemplos, meta‑aprendizado, redes neurais de grafos, predição de links