Clear Sky Science · nl
Meta‑leren voor few‑shot voltooiing van kennisgrafen met domeingecontroleerde aggregatie
Waarom het ertoe doet machines met slechts een paar voorbeelden te onderwijzen
Moderne kunstmatige intelligentiesystemen vertrouwen steeds vaker op omvangrijke "kennisgrafen" die mensen, plaatsen, dingen en ideeën koppelen in gigantische netwerken van feiten. Deze grafen versterken zoekmachines, aanbevelingssystemen en vraag‑en‑antwoordtools. In de echte wereld zijn veel verbindingen binnen deze grafen echter zeldzaam, slecht gedocumenteerd of gloednieuw. Een machine leren zulke zeldzame links te herkennen en aan te vullen wanneer slechts een handvol voorbeelden beschikbaar is, is lastig. Dit artikel introduceert een methode die AI helpt te leren van zeer weinig voorbeelden terwijl afleidende informatie wordt weggefilterd, zodat ontbrekende feiten in een kennisgraaf nauwkeuriger kunnen worden geraden.
Kaarten van kennis opgebouwd uit eenvoudige feiten
Een kennisgraaf representeert informatie als eenvoudige drie‑delige uitspraken zoals "persoon A werkt_voor bedrijf B" of "stad C is_in land D." Elke uitspraak koppelt twee entiteiten via een relatie, en miljoenen van deze koppelingen vormen samen een kenniskaart. Traditionele technieken zetten elke entiteit en relatie om in getallen in een wiskundige ruimte en leren vervolgens regels waarmee het systeem nieuwe links kan voorspellen. Deze technieken werken goed wanneer er veel voorbeelden bestaan voor elke relatie, zoals "geboren_in" of "gelegen_in", maar hebben moeite wanneer een relatie slechts een paar keer in de data voorkomt. In de praktijk komen zeldzame relaties veel voor—bijvoorbeeld een specifieke medische aandoening, een niche functietitel of een recent ontstane samenwerking—dus het verbeteren van prestaties op deze "few‑shot" gevallen is cruciaal.
Leren van buren zonder in ruis te verdwalen
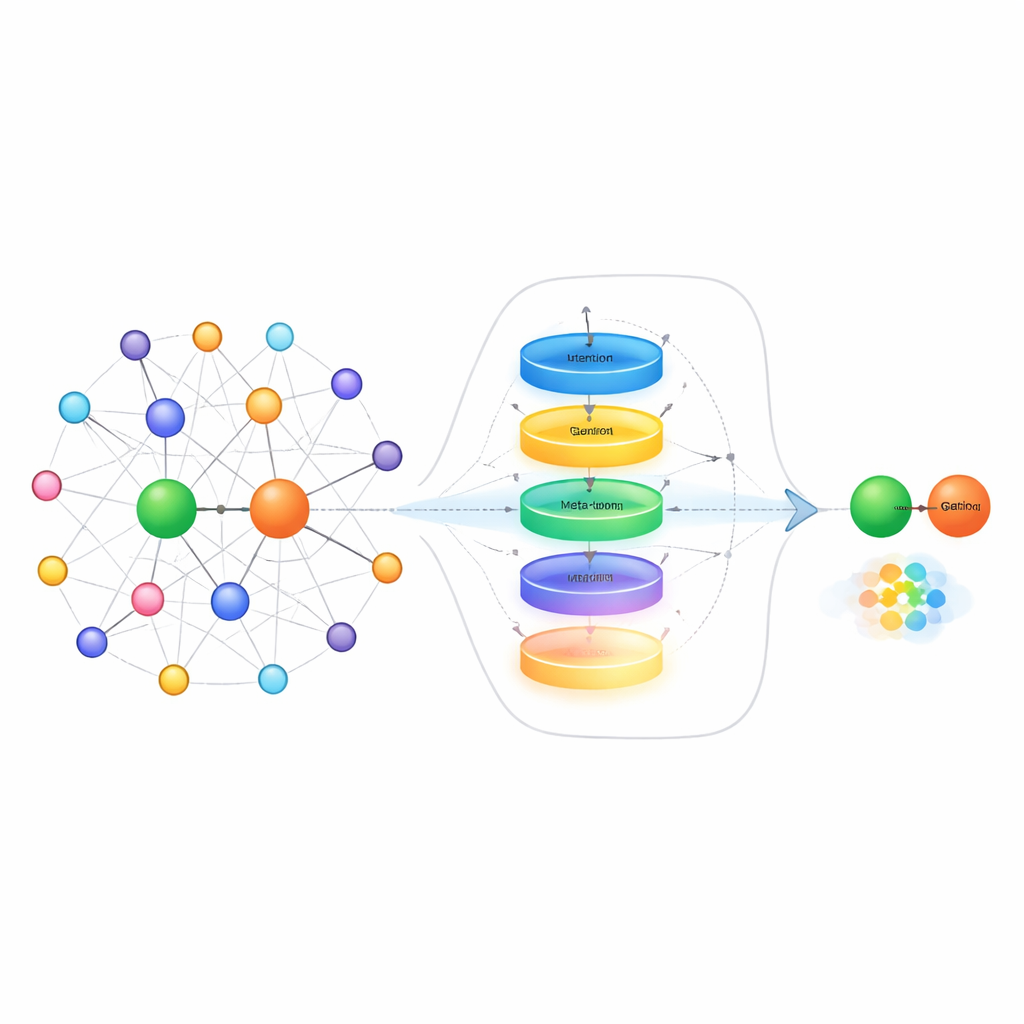
Een manier om met schaarse voorbeelden om te gaan is te kijken naar de "buren" van elke entiteit in de graaf—de andere feiten die direct met die entiteit verbonden zijn. Bijvoorbeeld, bij het voorspellen van iemands echtgenoot helpt het meer om familierelaties te kennen dan zakelijke partners. Bestaande methoden behandelen vaak alle nabijgelegen feiten als even nuttig, wat de echt relevante aanwijzingen kan overschaduwen met ruis. De auteurs stellen een buurtselectiemodule voor die eerst elke buur een score geeft op relevantie, alleen de hoogst scorende behoudt, en vervolgens een gating‑mechanisme gebruikt geïnspireerd door recurrente neurale netwerken om te bepalen hoeveel van deze buurinformatie daadwerkelijk de representatie van de entiteit moet bijwerken. Dit twee‑stappenproces filtert zowel off‑topic buren weg als balanceert dynamisch wat te onthouden en wat te negeren, wat vooral nuttig is wanneer slechts een paar trainingsvoorbeelden beschikbaar zijn.
Het systeem leren hoe het nieuwe relaties moet leren
Buiten het opschonen van buurtinformatie pakt de methode ook aan hoe het systeem relaties zelf representeert wanneer het slechts een paar voorbeeldkoppelingen ziet. In plaats van die voorbeelden simpelweg te middelen, bouwen de auteurs een relatie‑"meta‑learner". Die behandelt alle voorbeeldparen voor een gegeven relatie als een korte reeks en voert ze door een gated recurrent unit om patronen over de voorbeelden vast te leggen. Een contextuele attentie‑mechanisme laat het model vervolgens meer focussen op de meest informatieve paren, terwijl een klein feedforward‑netwerk het gecombineerde signaal verder verfijnt. Residuele verbindingen en normalisatie helpen het leren te stabiliseren. Het resultaat is een compacte, taakbewuste representatie van de relatie die subtiele verschillen in hoe entiteiten interageren vastlegt, zoals richting, sterkte of type verbinding.
Leren zich snel aan te passen met meta‑optimalisatie
Het laatste deel van de aanpak is een embedding‑learner die ideeën uit meta‑leren gebruikt—vaak aangeduid als "leren om te leren." Tijdens training ziet het systeem veel verschillende relaties als afzonderlijke kleine taken. Voor elke taak past het kort zijn parameters aan met alleen de weinige beschikbare voorbeelden, en controleert vervolgens hoe goed het presteert op nieuwe queries voor die relatie. De gradiënten van deze tweede stap updaten een gedeelde set parameters zodat het model in de loop van de tijd beter wordt in snel aanpassen aan gloednieuwe relaties die het nog nooit eerder heeft gezien. De methode bouwt voort op een bestaande techniek die entiteiten op relatie‑specifieke geometrische oppervlakken plaatst, en het werkt zowel de relatieweergave als deze oppervlakken bij tijdens meta‑leren, waarmee de voorspellingen verder worden aangescherpt.
Wat de resultaten betekenen voor alledaagse AI‑tools
De auteurs testen hun methode op twee veelgebruikte benchmarkdatasets, NELL‑One en Wiki‑One, en vergelijken deze met vele state‑of‑the‑art systemen voor few‑shot voltooiing van kennisgrafen. Over meerdere evaluatiematen presteert hun benadering consequent beter, met name wanneer er vijf voorbeeldkoppelingen per relatie beschikbaar zijn. De winst is het duidelijkst op een dataset waar buurinformatie rijker is, wat het belang onderstreept van zorgvuldige buurselectie en relationele meta‑learning. Voor alledaagse toepassingen betekent dit dat AI‑systemen betrouwbaarder ontbrekende kennisstukken kunnen invullen—zoals zeldzame relaties, gespecialiseerde concepten of opkomende feiten—zelfs wanneer slechts een klein aantal voorbeelden beschikbaar is, waardoor downstream‑tools zoals zoeken, aanbevelen en vraag‑en‑antwoord nauwkeuriger en robuuster worden.
Bronvermelding: Yang, B., Peng, M., Liu, S. et al. Meta learning based few shot knowledge graph completion with domain selected aggregation. Sci Rep 16, 12333 (2026). https://doi.org/10.1038/s41598-026-42198-4
Trefwoorden: kennisgrafen, few‑shot leren, meta‑leren, graph neural networks, linkvoorspelling