Clear Sky Science · he
השלמת גרפים של ידע בלומד־מטא על בסיס מספר מועט של דוגמאות עם אגגרגציה נבחרת לפי תחום
מדוע חשוב ללמד מכונות עם רק מעט דוגמאות
מערכות בינה מלאכותית מודרניות נשענות יותר ויותר על "גרפי ידע" גדולים שמקשרים אנשים, מקומות, פריטים ורעיונות לתוך רשת רחבה של עובדות. גרפים אלה מניעים מנועי חיפוש, מערכות המלצה וכלים למענה על שאלות. אבל במציאות, רבות מהקישורים בגרפים אלה נדירים, מתועדים באופן לקוי או חדשים לגמרי. ללמד מכונה לזהות ולהשלים קישורים נדירים כאשר קיימות רק מספר מועט של דוגמאות הוא אתגר. מאמר זה מציע שיטה המסייעת ל‑AI ללמוד ממעט דוגמאות תוך סינון מידע מבלבל, כך שתוכל לנחש באופן מדויק יותר עובדות חסרות בגרף הידע.
מפות ידע הבנויות מעובדות פשוטות
גרף ידע מייצג מידע כתביעות פשוטות בעלות שלושה חלקים, כגון "אדם A עובד_למען חברה B" או "עיר C נמצאת_ב מדינה D." כל תביעה מקשרת בין שתי ישויות באמצעות יחס, ומיליוני הקישורים האלה יחד יוצרים מפה של ידע. שיטות מסורתיות ממירות כל ישות וכל יחס למספרים במרחב מתמטי, ואז לומדות חוקים המאפשרים למערכת לחזות קישורים חדשים. טכניקות אלה עובדות היטב כשיש די דוגמאות לכל יחס, כמו "נולד_ב" או "ממוקם_ב", אך מתקשות כאשר יחס מופיע רק מספר מועט של פעמים בנתונים. במציאות יחס נדיר הוא תופעה שכיחה — למשל מצב רפואי ספציפי, תואר עבודה נישתי או שותפות חדשה — ולכן שיפור ביצועים במקרים של "מעט דוגמאות" הוא קריטי.
ללמוד מהשכנים בלי להיטרף מהרעש
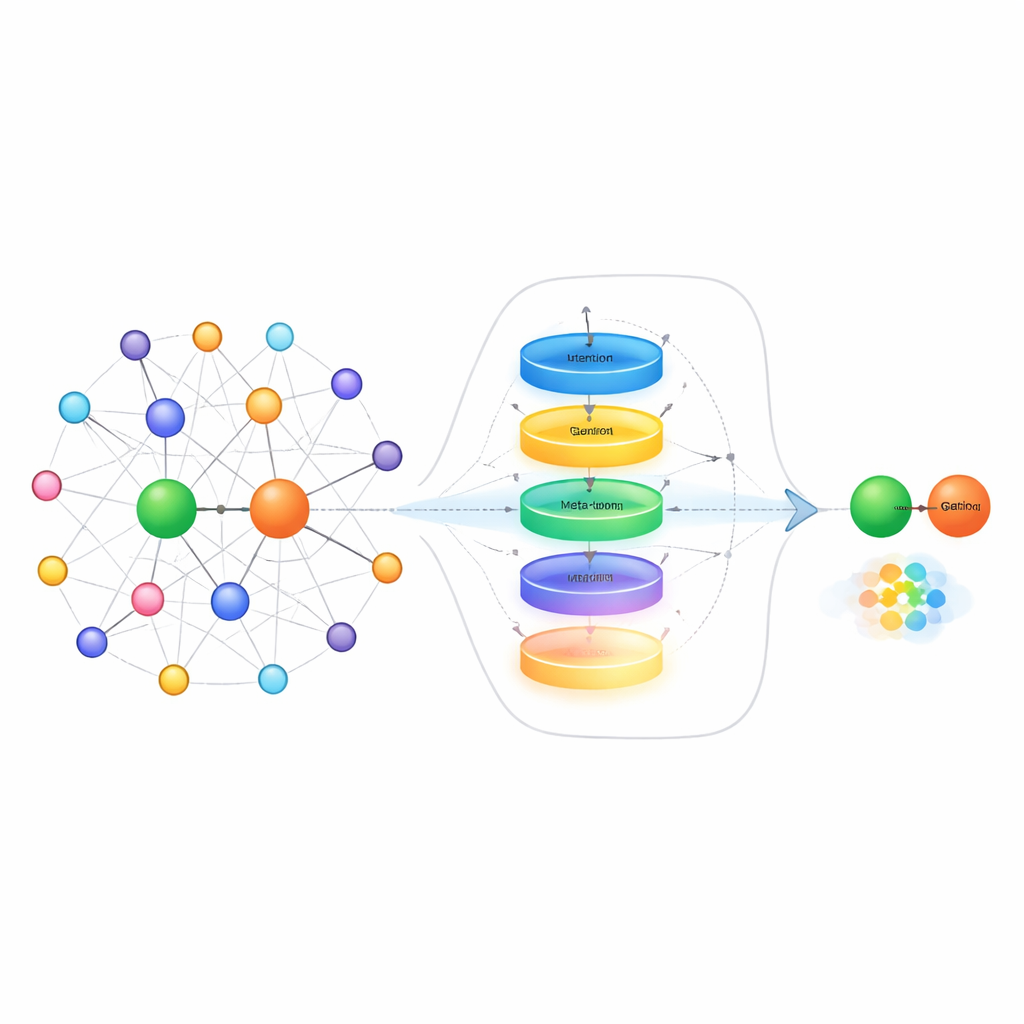
דרך אחת להתמודד עם מחסור בדוגמאות היא לבחון את "השכנים" של כל ישות בגרף — שאר העובדות שמחוברות אליה ישירות. למשל, כשמנסים לחזות את בן/בת הזוג של מישהו, עוזר לדעת את בני המשפחה שלו יותר מאשר שותפי העסק שלו. שיטות קיימות לעיתים מתייחסות לכל העובדות הסמוכות כאילו הן מועילות באותה מידה, מה שעלול לטבוע את הרמזים הרלוונטיים ברעש. המחברים מציעים מודול בחירת שכונה שמדרג תחילה כל שכן לפי רלוונטיות, שומר רק את המדורגים הגבוהים ביותר, ואז משתמש במנגנון סינון בהשראת רשתות חוזרות כדי להחליט כמה ממידע השכנים הזה באמת יעדכן את הייצוג של הישות. תהליך דו‑שלבי זה גם מסנן שכנים לא קשורים ודינמית מאזין למה לזכור ומה להתעלם ממנו — דבר מועיל במיוחד כשיש רק מעט דוגמאות אימון.
ללמד את המערכת כיצד ללמוד יחסים חדשים
בנוסף לניקוי מידע השכונה, השיטה מתמודדת גם עם האופן שבו המערכת מייצגת יחסים עצמם כאשר נראים רק מספר מועט של קישורים לדוגמה. במקום פשוט לקחת ממוצע של הדוגמאות, המחברים בונים "מטא‑לומד" לייצוג היחס. הוא מתייחס לכל זוגות הדוגמא עבור יחס נתון כסדרה קצרה ומעביר אותם דרך יחידת זיכרון חוזרת ממוכנת (GRU) כדי לתפוס דפוסים החוצים את הדוגמאות. מנגנון קשב קונטקסטואלי מאפשר למודל להתמקד יותר בזוגות המידעיים ביותר, בעוד רשת זורמת קטנה (feed‑forward) מלטשת עוד את האות המשולב. חיבורים שאריתיים ונרמול עוזרים לייצב את הלמידה. התוצאה היא ייצוג קומפקטי ותואם למשימה של היחס, שתופס הבדלים עדינים באופן שבו ישויות מתקשרות — כגון כיוון, חוזק או סוג הקשר.
ללמוד להסתגל במהירות באמצעות מטא‑אופטימיזציה
החלק הסופי בגישה הוא לומד הטמעה (embedding learner) שמשתמש ברעיונות ממטא‑למידה — לעתים נקראת "לימוד ללמוד". במהלך האימון המערכת נתקלה בהרבה יחסים שונים כמשימות קטנות נפרדות. עבור כל משימה היא מתאימה בקצרה את הפרמטרים שלה באמצעות הדוגמאות המועטות הזמינות, ואז בודקת עד כמה היא מתפקדת על שאילתות חדשות עבור אותו יחס. הגרדיאנטים מהצעד השני מעדכנים סט פרמטרים משותף כך שבעתיד המודל משתפר ביכולתו להסתגל במהירות ליחסים חדשים שמעולם לא נראו קודם. השיטה בונה על טכניקה קיימת שממקמת ישויות על משטחים גיאומטריים ספציפיים ליחס, והיא מעדכנת גם את ייצוג היחס וגם את המשטחים הללו במהלך המטא‑למידה, מה שמחדד עוד יותר את החיזויים.
מה המשמעות של התוצאות לכלי ה‑AI היומיומיים
המחברים בוחנים את שיבתם על שני מערכי נתונים תקניים ונפוצים, NELL‑One ו‑Wiki‑One, ומשווים אותה עם מערכות רבות מהמתקדמות בתחום השלמת גרפי הידע במצב של מעט דוגמאות. על פני מדדי הערכה שונים, הגישה שלהם מבצעת בעקביות טוב יותר, במיוחד כשהיא מקבלת חמש דוגמאות קישור לכל יחס. השיפורים בולטים יותר במערכים שבהם מידע השכנים עשיר יותר, מה שמדגיש את חשיבות בחירת השכנים בקפידה ואת מטא‑למידת היחסים. עבור יישומים יומיומיים, משמעות הדבר היא שמערכות AI עשויות להשלים באופן אמין יותר חתיכות חסרות של ידע — כגון יחסים נדירים, מושגים מומחים או עובדות חדשות — גם כאשר זמינות רק מעט דוגמאות, מה שהופך כלים כמו חיפוש, המלצה ומענה על שאלות ליותר מדויקים ועמידים.
ציטוט: Yang, B., Peng, M., Liu, S. et al. Meta learning based few shot knowledge graph completion with domain selected aggregation. Sci Rep 16, 12333 (2026). https://doi.org/10.1038/s41598-026-42198-4
מילות מפתח: גרפי ידע, למידה במיעוט דוגמאות, מטא‑למידה, רשתות עצביות גרפיות, חיזוי קישורים