Clear Sky Science · pl
Uzupełnianie grafów wiedzy przy małej liczbie przykładów oparte na meta‑uczeniu z agregacją wybraną według domeny
Dlaczego nauczanie maszyn na zaledwie kilku przykładach ma znaczenie
Nowoczesne systemy sztucznej inteligencji coraz częściej opierają się na rozległych „grafach wiedzy”, które łączą ludzi, miejsca, przedmioty i pojęcia w ogromne sieci faktów. Grafy te napędzają wyszukiwarki, systemy rekomendacyjne oraz narzędzia do odpowiadania na pytania. W praktyce wiele powiązań w tych grafach jest jednak rzadkich, słabo udokumentowanych lub zupełnie nowych. Nauczenie maszyny rozpoznawania i uzupełniania takich rzadkich łączy, gdy dostępnych jest tylko kilka przykładów, jest trudne. Artykuł przedstawia metodę, która pomaga AI uczyć się z bardzo niewielu próbek, jednocześnie filtrować rozpraszające informacje, dzięki czemu może dokładniej wnioskować brakujące fakty w grafie wiedzy.
Mapy wiedzy zbudowane z prostych faktów
Graf wiedzy reprezentuje informacje jako proste trójskładnikowe stwierdzenia, takie jak „osoba A pracuje_dla firmy B” lub „miasto C jest_w kraju D”. Każde stwierdzenie łączy dwie jednostki (byty) przez relację, a miliony takich połączeń tworzą mapę wiedzy. Tradycyjne techniki zamieniają każde wystąpienie jednostki i relacji na liczby w przestrzeni matematycznej, a następnie uczą reguł pozwalających systemowi przewidywać nowe połączenia. Metody te działają dobrze, gdy dla każdej relacji istnieje wiele przykładów, na przykład „urodzony_w” lub „zlokalizowany_w”, ale zawodzą, gdy relacja pojawia się tylko kilka razy w danych. W praktyce rzadkie relacje są powszechne — na przykład konkretne schorzenie, niszowy tytuł zawodowy lub nowo powstałe partnerstwo — więc poprawa wydajności w tych przypadkach „few‑shot” jest kluczowa.
Uczenie się od sąsiadów bez gubienia się w szumie
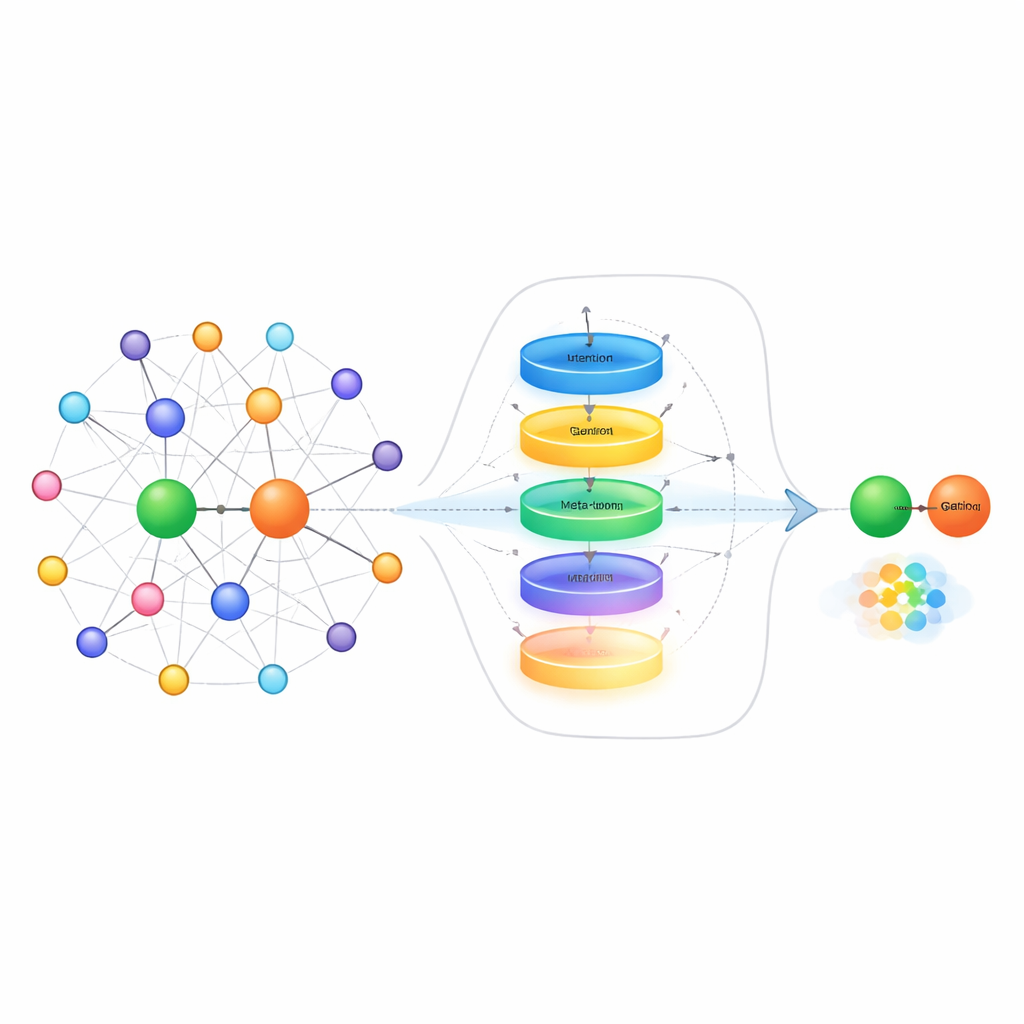
Jednym ze sposobów radzenia sobie z niewielką liczbą przykładów jest spojrzenie na „sąsiadów” każdej jednostki w grafie — innych faktów bezpośrednio z nią powiązanych. Na przykład przy przewidywaniu małżonka danej osoby bardziej pomocna jest wiedza o członkach rodziny niż o partnerach biznesowych. Istniejące metody często traktują wszystkie pobliskie fakty jako jednakowo użyteczne, co może zagłuszyć istotne wskazówki szumem. Autorzy proponują moduł wyboru sąsiedztwa, który najpierw ocenia każdego sąsiada pod kątem relewantności, zachowuje tylko najwyżej ocenione, a następnie używa mechanizmu bramkowania inspirowanego rekurencyjnymi sieciami neuronowymi, aby zdecydować, w jakim stopniu informacje od tych sąsiadów powinny faktycznie aktualizować reprezentację jednostki. Ten dwuetapowy proces zarówno filtruje nieistotnych sąsiadów, jak i dynamicznie równoważy to, co zapamiętać, a co zignorować — szczególnie przydatne, gdy dostępnych jest tylko kilka przykładów treningowych.
Nauczanie systemu, jak poznawać nowe relacje
Ponad oczyszczaniem informacji o sąsiadach, metoda zajmuje się także sposobem reprezentowania samych relacji, gdy widzi tylko garstkę przykładowych łączy. Zamiast prostego uśredniania przykładów, autorzy budują „meta‑ucznik” relacji. Traktuje on wszystkie pary przykładowe dla danej relacji jako krótką sekwencję i przetwarza je przez bramkowaną jednostkę rekurencyjną (GRU), aby wychwycić wzorce między przykładami. Kontekstowy mechanizm uwagi pozwala modelowi skupić się bardziej na najbardziej informatywnych parach, a niewielka sieć w pełni połączona dodatkowo wyostrza skumulowany sygnał. Połączenia resztkowe i normalizacja pomagają ustabilizować uczenie. Efektem jest zwarta, świadoma zadania reprezentacja relacji, która wychwytuje subtelne różnice w interakcji jednostek, takie jak kierunek, siła czy typ połączenia.
Nauka szybkiej adaptacji dzięki meta‑optymalizacji
Ostatnim elementem podejścia jest uczący się osadzania moduł, który wykorzystuje pomysły z meta‑uczenia — często określanego jako „uczenie się uczenia”. Podczas treningu system widzi wiele różnych relacji jako osobne małe zadania. Dla każdego zadania krótko dopasowuje swoje parametry używając tylko dostępnych kilku przykładów, a następnie sprawdza, jak dobrze radzi sobie z nowymi zapytaniami dotyczącymi tej relacji. Gradienty z tego drugiego kroku aktualizują wspólny zestaw parametrów tak, że z upływem czasu model staje się lepszy w szybkim dostosowywaniu się do zupełnie nowych relacji, których wcześniej nie widział. Metoda opiera się na istniejącej technice umieszczania jednostek na relacyjnie specyficznych powierzchniach geometrycznych i aktualizuje zarówno reprezentację relacji, jak i te powierzchnie podczas meta‑uczenia, co dodatkowo wyostrza przewidywania.
Co wyniki oznaczają dla codziennych narzędzi AI
Autorzy testują metodę na dwóch powszechnie używanych zbiorach odniesienia, NELL‑One i Wiki‑One, i porównują ją z wieloma najnowocześniejszymi systemami do uzupełniania grafów wiedzy w trybie few‑shot. W różnych miarach oceny ich podejście konsekwentnie osiąga lepsze wyniki, szczególnie gdy ma do dyspozycji pięć przykładów na relację. Zyski są najbardziej widoczne w zbiorze, w którym informacje o sąsiadach są bogatsze, co podkreśla wartość starannego doboru sąsiadów i meta‑uczenia relacji. Dla zastosowań codziennych oznacza to, że systemy AI mogłyby bardziej niezawodnie wypełniać brakujące elementy wiedzy — takie jak rzadkie relacje, wyspecjalizowane pojęcia czy nowe fakty — nawet gdy dostępna jest tylko niewielka liczba przykładów, co czyni narzędzia takie jak wyszukiwanie, rekomendacje i odpowiadanie na pytania bardziej dokładnymi i odpornymi.
Cytowanie: Yang, B., Peng, M., Liu, S. et al. Meta learning based few shot knowledge graph completion with domain selected aggregation. Sci Rep 16, 12333 (2026). https://doi.org/10.1038/s41598-026-42198-4
Słowa kluczowe: grafy wiedzy, uczenie przy małej liczbie przykładów, meta‑uczenie, sieć neuronowa grafowa, predykcja powiązań