Clear Sky Science · fr
Complétion de graphe de connaissances en few-shot basée sur le méta-apprentissage avec agrégation sélectionnée par domaine
Pourquoi enseigner aux machines avec seulement quelques exemples importe
Les systèmes d’intelligence artificielle modernes reposent de plus en plus sur d’immenses « graphes de connaissances » qui relient personnes, lieux, objets et idées en vastes réseaux de faits. Ces graphes alimentent les moteurs de recherche, les systèmes de recommandation et les outils de question‑réponse. Mais dans le monde réel, de nombreuses connexions au sein de ces graphes sont rares, mal documentées ou tout juste apparues. Apprendre à une machine à reconnaître et compléter ces liens rares lorsqu’il n’existe que quelques exemples est difficile. Cet article présente une méthode qui aide l’IA à apprendre à partir d’un très petit nombre d’exemples tout en filtrant les informations distrayantes, afin qu’elle puisse deviner plus précisément les faits manquants dans un graphe de connaissances.
Cartes du savoir construites à partir de faits simples
Un graphe de connaissances représente l’information sous forme d’énoncés simples à trois éléments tels que « personne A travaille_pour entreprise B » ou « ville C est_dans pays D ». Chaque énoncé relie deux entités par une relation, et des millions de ces liens forment ensemble une carte des connaissances. Les techniques traditionnelles transforment chaque entité et relation en nombres dans un espace mathématique, puis apprennent des règles permettant au système de prédire de nouveaux liens. Ces techniques fonctionnent bien lorsqu’il existe de nombreux exemples pour chaque relation, comme « né_dans » ou « situé_dans », mais elles échouent lorsqu’une relation n’apparaît que rarement dans les données. En pratique, les relations rares sont fréquentes — par exemple une pathologie spécifique, un intitulé de poste de niche ou un partenariat émergent — d’où l’importance d’améliorer les performances sur ces cas « few‑shot ».
Apprendre des voisins sans se noyer dans le bruit
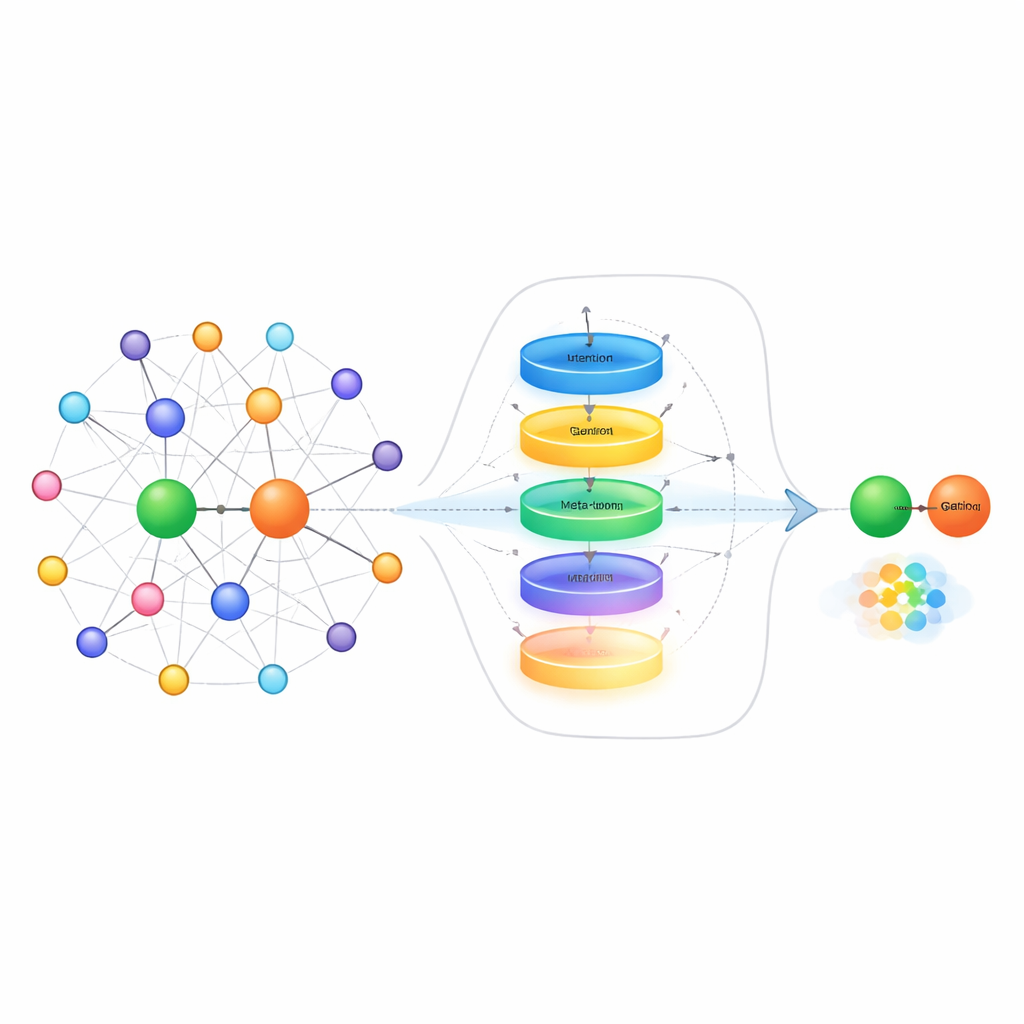
Une façon de faire face au manque d’exemples est d’examiner les « voisins » de chaque entité dans le graphe — les autres faits qui lui sont directement connectés. Par exemple, pour prédire le conjoint d’une personne, il est plus utile de connaître ses membres de la famille que ses partenaires commerciaux. Les méthodes existantes considèrent souvent tous les faits voisins comme également utiles, ce qui peut noyer les indices réellement pertinents dans le bruit. Les auteurs proposent un module de sélection de voisinage qui évalue d’abord la pertinence de chaque voisin, conserve uniquement les mieux notés, puis utilise un mécanisme de gating inspiré des réseaux récurrents pour décider dans quelle mesure ces informations de voisinage doivent réellement mettre à jour la représentation de l’entité. Ce processus en deux étapes filtre à la fois les voisins hors sujet et équilibre dynamiquement ce qu’il faut retenir et oublier, ce qui est particulièrement utile quand il n’y a que quelques exemples d’entraînement.
Apprendre au système à représenter de nouvelles relations
Au‑delà du nettoyage des informations de voisinage, la méthode s’attaque aussi à la manière dont le système représente les relations elles‑mêmes lorsqu’il ne voit qu’un petit nombre d’exemples. Plutôt que de se contenter de moyenniser ces exemples, les auteurs construisent un « méta‑apprenant » de relation. Il traite tous les paires d’exemples pour une relation donnée comme une courte séquence et les fait passer par une unité récurrente à portes (GRU) pour capturer des motifs à travers les exemples. Un mécanisme d’attention contextuelle permet ensuite au modèle de se concentrer davantage sur les paires les plus informatives, tandis qu’un petit réseau feed‑forward affine encore le signal combiné. Des connexions résiduelles et une normalisation stabilisent l’apprentissage. Le résultat est une représentation compacte et adaptée à la tâche de la relation qui capture des différences subtiles dans l’interaction des entités, comme la direction, l’intensité ou le type de connexion.
Apprendre à s’adapter rapidement par méta‑optimisation
La dernière pièce de l’approche est un apprenant d’embeddings qui utilise des idées du méta‑apprentissage — souvent appelé « apprendre à apprendre ». Pendant l’entraînement, le système considère de nombreuses relations différentes comme autant de petites tâches séparées. Pour chaque tâche, il adapte brièvement ses paramètres en n’utilisant que les quelques exemples disponibles, puis évalue ses performances sur de nouvelles requêtes pour cette relation. Les gradients issus de cette seconde étape mettent à jour un ensemble de paramètres partagé de sorte qu’avec le temps, le modèle devient meilleur pour s’adapter rapidement à des relations entièrement nouvelles qu’il n’a jamais vues. La méthode s’appuie sur une technique existante qui positionne les entités sur des surfaces géométriques spécifiques à la relation, et elle met à jour à la fois la représentation de la relation et ces surfaces durant le méta‑apprentissage, affinant encore ses prédictions.
Ce que signifient les résultats pour les outils d’IA du quotidien
Les auteurs testent leur méthode sur deux jeux de référence largement utilisés, NELL‑One et Wiki‑One, et la comparent à de nombreux systèmes à la pointe pour la complétion de graphes de connaissances en few‑shot. Selon plusieurs mesures d’évaluation, leur approche obtient systématiquement de meilleurs résultats, en particulier lorsqu’elle dispose de cinq exemples par relation. Les gains sont les plus marqués sur un jeu de données où l’information sur les voisins est plus riche, soulignant la valeur d’une sélection soignée des voisins et du méta‑apprentissage des relations. Pour les applications courantes, cela signifie que les systèmes d’IA pourraient combler plus fiablement les lacunes de connaissance — comme des relations rares, des concepts spécialisés ou des faits émergents — même lorsque seul un petit nombre d’exemples est disponible, rendant des outils en aval comme la recherche, la recommandation et la réponse aux questions plus précis et robustes.
Citation: Yang, B., Peng, M., Liu, S. et al. Meta learning based few shot knowledge graph completion with domain selected aggregation. Sci Rep 16, 12333 (2026). https://doi.org/10.1038/s41598-026-42198-4
Mots-clés: graphes de connaissances, apprentissage par peu d’exemples, méta-apprentissage, réseaux de neurones sur graphes, prédiction de liens