Clear Sky Science · en
Meta learning based few shot knowledge graph completion with domain selected aggregation
Why teaching machines with just a few examples matters
Modern artificial intelligence systems increasingly rely on vast “knowledge graphs” that link people, places, things and ideas into giant webs of facts. These graphs power search engines, recommendation systems and question‑answering tools. But in the real world, many connections inside these graphs are rare, poorly documented or brand new. Teaching a machine to recognize and complete these rare links when only a handful of examples exist is difficult. This paper introduces a method that helps AI learn from very few samples while filtering out distracting information, so that it can more accurately guess missing facts in a knowledge graph.
Maps of knowledge built from simple facts
A knowledge graph represents information as simple three‑part statements such as “person A works_for company B” or “city C is_in country D.” Each statement links two entities through a relation, and millions of these links together form a map of knowledge. Traditional techniques turn every entity and relation into numbers in a mathematical space, and then learn rules that allow the system to predict new links. These techniques work well when plenty of examples exist for each relation, like “born_in” or “located_in,” but stumble when a relation appears only a few times in the data. In practice, rare relations are common—for instance, a specific medical condition, a niche job title or a newly emerging partnership—so improving performance on these “few‑shot” cases is crucial.
Learning from neighbors without getting lost in noise
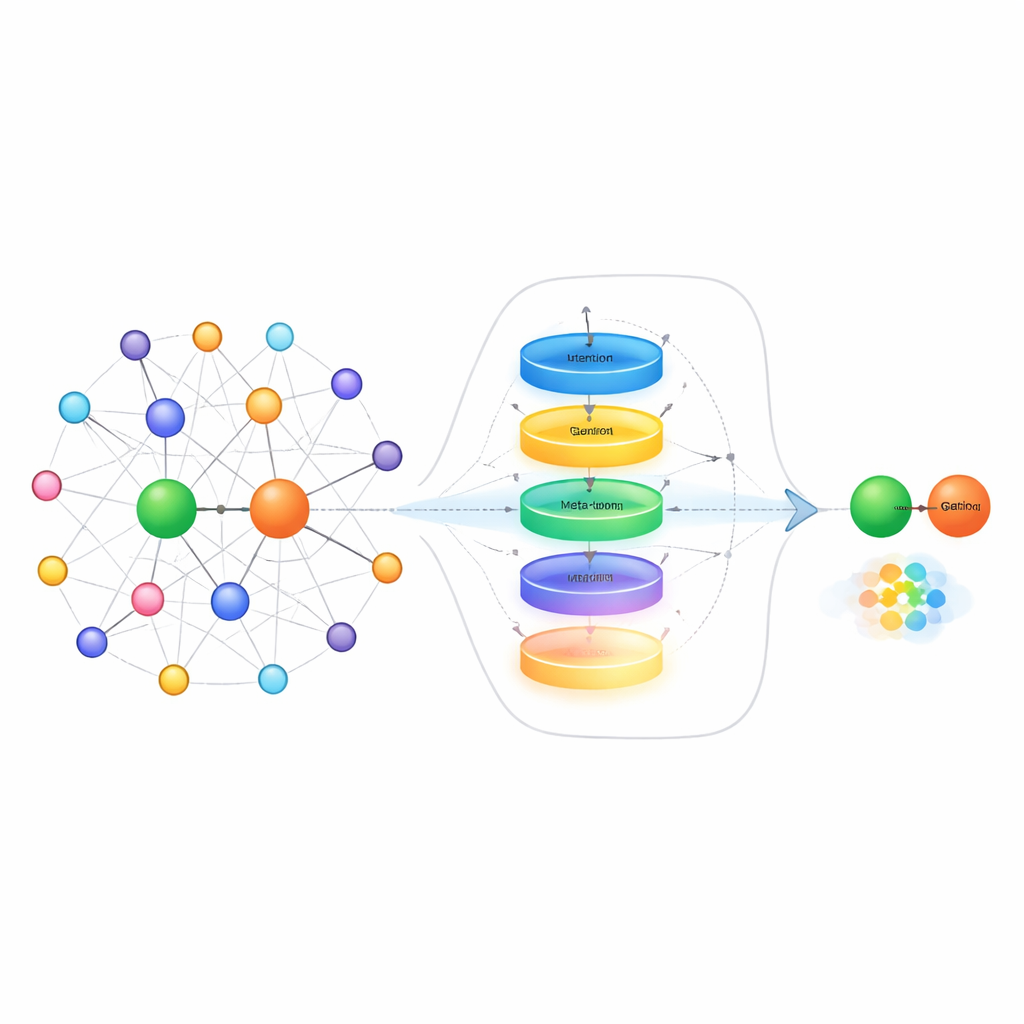
One way to cope with scarce examples is to look at the “neighbors” of each entity in the graph—the other facts directly connected to it. For example, when trying to predict someone’s spouse, it helps to know their family members more than their business partners. Existing methods often treat all nearby facts as equally useful, which can drown out the truly relevant clues with noise. The authors propose a neighborhood selection module that first scores each neighbor by how relevant it is, keeps only the top‑scoring ones, and then uses a gating mechanism inspired by recurrent neural networks to decide how much of this neighbor information should actually update the entity’s representation. This two‑step process both filters out off‑topic neighbors and dynamically balances what to remember and what to ignore, especially helpful when only a few training examples are available.
Teaching the system how to learn new relations
Beyond cleaning up neighborhood information, the method also tackles how the system represents relations themselves when it only sees a handful of example links. Instead of simply averaging those examples, the authors build a relation “meta‑learner.” It treats all example pairs for a given relation as a short sequence and passes them through a gated recurrent unit to capture patterns across the examples. A contextual attention mechanism then lets the model focus more on the most informative pairs, while a small feed‑forward network further refines the combined signal. Residual connections and normalization help stabilize learning. The result is a compact, task‑aware representation of the relation that captures subtle differences in how entities interact, such as direction, strength or type of connection.
Learning how to adapt quickly with meta‑optimization
The final piece of the approach is an embedding learner that uses ideas from meta‑learning—often called “learning to learn.” During training, the system sees many different relations as separate small tasks. For each task, it briefly adapts its parameters using only the few available examples, then checks how well it performs on new queries for that relation. The gradients from this second step update a shared set of parameters so that, over time, the model becomes better at adapting quickly to brand‑new relations it has never seen before. The method builds on an existing technique that places entities on relation‑specific geometric surfaces, and it updates both the relation representation and these surfaces during meta‑learning, further sharpening its predictions.
What the results mean for everyday AI tools
The authors test their method on two widely used benchmark datasets, NELL‑One and Wiki‑One, and compare it with many state‑of‑the‑art systems for few‑shot knowledge graph completion. Across several evaluation measures, their approach consistently performs better, particularly when it has five example links per relation. The gains are most pronounced on a dataset where neighbor information is richer, underscoring the value of careful neighbor selection and relation meta‑learning. For everyday applications, this means AI systems could more reliably fill in missing pieces of knowledge—such as rare relationships, specialized concepts or emerging facts—even when only a small number of examples are available, making downstream tools like search, recommendation and question answering more accurate and robust.
Citation: Yang, B., Peng, M., Liu, S. et al. Meta learning based few shot knowledge graph completion with domain selected aggregation. Sci Rep 16, 12333 (2026). https://doi.org/10.1038/s41598-026-42198-4
Keywords: knowledge graphs, few-shot learning, meta-learning, graph neural networks, link prediction