Clear Sky Science · it
Completamento di grafi di conoscenza few‑shot basato su meta‑learning con aggregazione selezionata per dominio
Perché insegnare alle macchine con pochi esempi è importante
I moderni sistemi di intelligenza artificiale si basano sempre più su vasti “grafi di conoscenza” che collegano persone, luoghi, cose e idee in enormi reti di fatti. Questi grafi alimentano motori di ricerca, sistemi di raccomandazione e strumenti di domanda‑risposta. Ma nel mondo reale molte connessioni all’interno di questi grafi sono rare, poco documentate o del tutto nuove. Insegnare a una macchina a riconoscere e completare questi link rari quando esistono solo pochissimi esempi è difficile. Questo articolo propone un metodo che aiuta l’IA a imparare da pochissimi esempi filtrando le informazioni distraenti, così da poter indovinare con maggiore precisione i fatti mancanti in un grafo di conoscenza.
Mappe della conoscenza costruite da fatti elementari
Un grafo di conoscenza rappresenta l’informazione come semplici enunciati in tre parti, ad esempio “persona A lavora_per azienda B” o “città C è_in paese D.” Ogni enunciato collega due entità tramite una relazione, e milioni di questi collegamenti insieme formano una mappa della conoscenza. Le tecniche tradizionali trasformano ogni entità e relazione in numeri in uno spazio matematico, e poi apprendono regole che permettono al sistema di predire nuovi link. Queste tecniche funzionano bene quando esistono molti esempi per ciascuna relazione, come “nato_in” o “situato_in”, ma falliscono quando una relazione appare poche volte nei dati. Nella pratica, le relazioni rare sono comuni — per esempio una specifica condizione medica, un titolo professionale di nicchia o una partnership emergente — quindi migliorare le prestazioni su questi casi “few‑shot” è cruciale.
Imparare dai vicini senza perdersi nel rumore
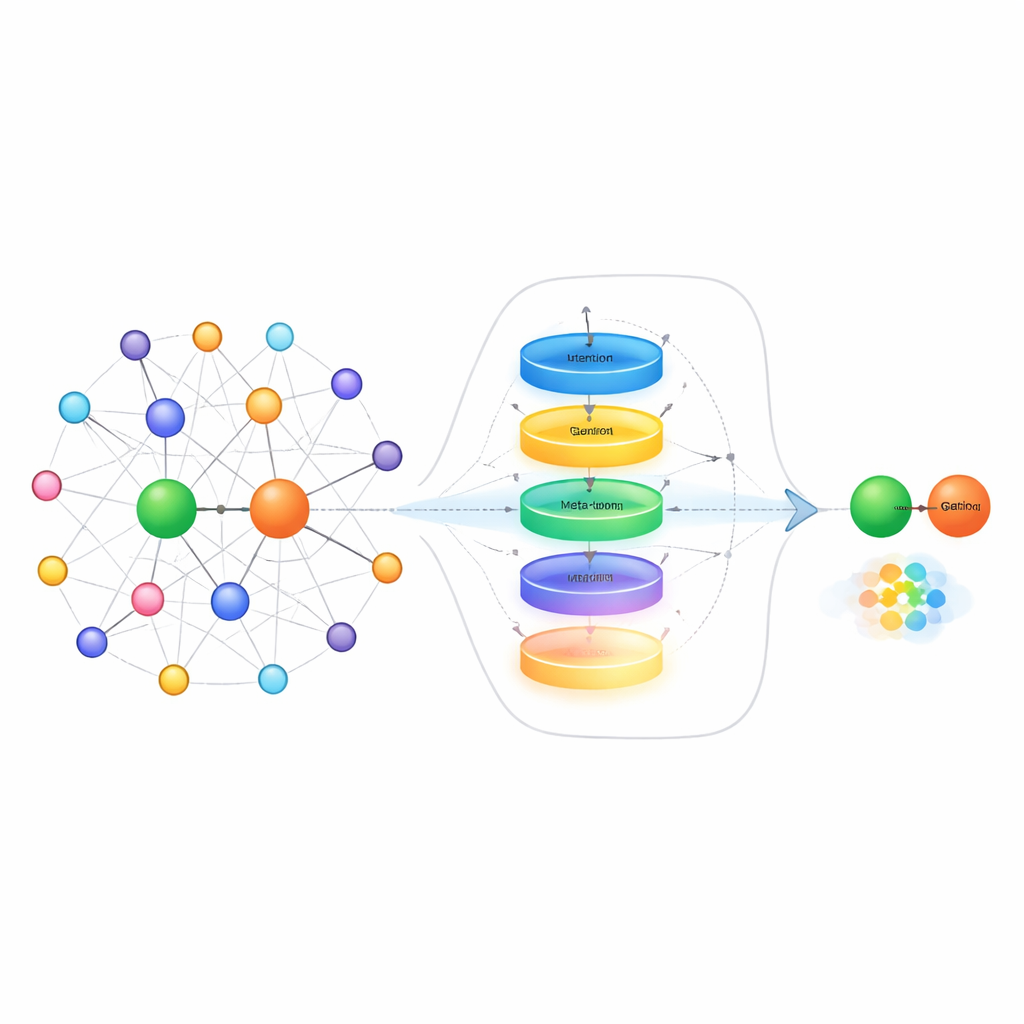
Un modo per gestire gli esempi scarsi è osservare i “vicini” di ogni entità nel grafo — gli altri fatti direttamente collegati a essa. Per esempio, quando si cerca di predire il coniuge di una persona, aiuta conoscere i membri della sua famiglia più che i suoi partner commerciali. I metodi esistenti spesso trattano tutti i fatti vicini come ugualmente utili, il che può soffocare gli indizi davvero rilevanti con rumore. Gli autori propongono un modulo di selezione del vicinato che prima valuta ciascun vicino in base alla sua rilevanza, mantiene solo i più votati e poi usa un meccanismo di gating ispirato alle reti ricorrenti per decidere quanto di queste informazioni debba effettivamente aggiornare la rappresentazione dell’entità. Questo processo in due fasi sia filtra i vicini fuori tema sia bilancia dinamicamente cosa ricordare e cosa ignorare, particolarmente utile quando sono disponibili solo pochi esempi di addestramento.
Insegnare al sistema come rappresentare nuove relazioni
Oltre a ripulire le informazioni sul vicinato, il metodo affronta anche il modo in cui il sistema rappresenta le relazioni stesse quando vede solo pochi esempi di link. Invece di limitarsi a fare una media di quegli esempi, gli autori costruiscono un “meta‑learner” per le relazioni. Trattano tutte le coppie di esempio per una data relazione come una breve sequenza e le fanno passare attraverso un’unità ricorrente a gating (GRU) per catturare i pattern tra gli esempi. Un meccanismo di attenzione contestuale permette quindi al modello di concentrarsi maggiormente sulle coppie più informative, mentre una piccola rete feed‑forward affina ulteriormente il segnale combinato. Connessioni residuali e normalizzazione aiutano a stabilizzare l’apprendimento. Il risultato è una rappresentazione compatta e sensibile al compito della relazione che cattura differenze sottili nell’interazione tra entità, come direzione, intensità o tipo di collegamento.
Imparare ad adattarsi rapidamente con la meta‑ottimizzazione
L’ultimo elemento dell’approccio è un apprenditore di embedding che usa idee del meta‑learning — spesso chiamato “imparare a imparare.” Durante l’addestramento, il sistema vede molte relazioni diverse come piccoli compiti separati. Per ciascun compito si adatta brevemente ai parametri usando solo i pochi esempi disponibili, poi verifica quanto bene si comporta su nuove query per quella relazione. I gradienti di questo secondo passo aggiornano un insieme condiviso di parametri in modo che, nel tempo, il modello migliori nella capacità di adattarsi rapidamente a relazioni completamente nuove mai viste prima. Il metodo si basa su una tecnica esistente che colloca le entità su superfici geometriche specifiche per relazione, e aggiorna sia la rappresentazione della relazione sia queste superfici durante il meta‑learning, affinando ulteriormente le predizioni.
Cosa significano i risultati per gli strumenti AI di uso quotidiano
Gli autori testano il loro metodo su due dataset di riferimento ampiamente usati, NELL‑One e Wiki‑One, e lo confrontano con molti sistemi all’avanguardia per il completamento few‑shot di grafi di conoscenza. In diverse misure di valutazione, il loro approccio performa costantemente meglio, in particolare quando sono disponibili cinque link di esempio per relazione. I guadagni sono più marcati su un dataset dove le informazioni sui vicini sono più ricche, sottolineando il valore della selezione accurata dei vicini e del meta‑learning delle relazioni. Per le applicazioni quotidiane, questo significa che i sistemi di IA potrebbero riempire in modo più affidabile i pezzi mancanti della conoscenza — come relazioni rare, concetti specializzati o fatti emergenti — anche quando sono disponibili solo pochi esempi, rendendo strumenti downstream come ricerca, raccomandazione e domanda‑risposta più accurati e robusti.
Citazione: Yang, B., Peng, M., Liu, S. et al. Meta learning based few shot knowledge graph completion with domain selected aggregation. Sci Rep 16, 12333 (2026). https://doi.org/10.1038/s41598-026-42198-4
Parole chiave: grafi di conoscenza, few-shot learning, meta-learning, reti neurali su grafi, predizione di link