Clear Sky Science · es
Completado de grafos de conocimiento en pocos disparos basado en meta‑aprendizaje con agregación seleccionada por dominio
Por qué importa enseñar a las máquinas con solo unos pocos ejemplos
Los sistemas modernos de inteligencia artificial dependen cada vez más de vastos “grafos de conocimiento” que conectan personas, lugares, objetos e ideas en enormes redes de hechos. Estos grafos alimentan motores de búsqueda, sistemas de recomendación y herramientas de respuesta a preguntas. Pero en el mundo real, muchas conexiones dentro de estos grafos son raras, están mal documentadas o son completamente nuevas. Enseñar a una máquina a reconocer y completar estos enlaces poco frecuentes cuando solo existen unos pocos ejemplos es difícil. Este artículo presenta un método que ayuda a la IA a aprender a partir de muy pocas muestras al mismo tiempo que filtra la información distractora, de modo que pueda inferir con mayor precisión los hechos faltantes en un grafo de conocimiento.
Mapas de conocimiento construidos a partir de hechos simples
Un grafo de conocimiento representa la información como declaraciones simples de tres partes, por ejemplo “persona A trabaja_en empresa B” o “ciudad C está_en país D.” Cada declaración enlaza dos entidades mediante una relación, y millones de estos enlaces forman un mapa del conocimiento. Las técnicas tradicionales convierten cada entidad y relación en números dentro de un espacio matemático y luego aprenden reglas que permiten al sistema predecir nuevos enlaces. Estas técnicas funcionan bien cuando existen muchos ejemplos para cada relación, como “nacido_en” o “ubicado_en,” pero fallan cuando una relación aparece solo unas pocas veces en los datos. En la práctica, las relaciones raras son comunes —por ejemplo, una condición médica específica, un título de trabajo especializado o una asociación emergente— por lo que mejorar el rendimiento en estos casos de “pocos ejemplos” es crucial.
Aprender de los vecinos sin perderse en el ruido
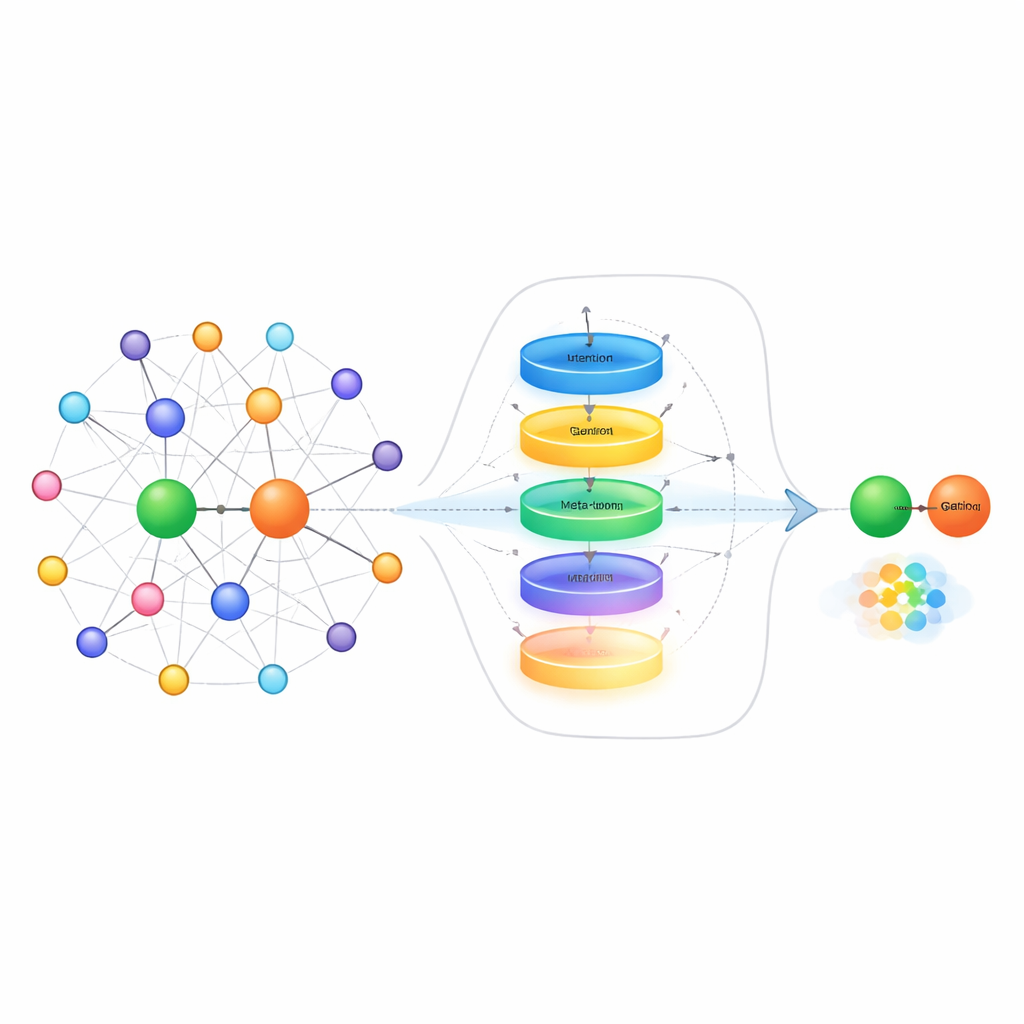
Una forma de afrontar la escasez de ejemplos es examinar los “vecinos” de cada entidad en el grafo —los otros hechos directamente conectados a ella—. Por ejemplo, al intentar predecir la pareja de alguien, es más útil conocer a sus familiares que a sus socios comerciales. Los métodos existentes a menudo tratan todos los hechos cercanos como igualmente útiles, lo que puede ahogar las pistas realmente relevantes con ruido. Los autores proponen un módulo de selección de vecinos que primero puntúa cada vecino según su relevancia, conserva solo los de mayor puntuación y luego utiliza un mecanismo de compuertas inspirado en redes neuronales recurrentes para decidir cuánto de la información vecina debe realmente actualizar la representación de la entidad. Este proceso en dos pasos filtra tanto los vecinos fuera de tema como equilibra dinámicamente qué recordar y qué ignorar, lo que resulta especialmente útil cuando solo hay unos pocos ejemplos de entrenamiento disponibles.
Enseñar al sistema cómo aprender nuevas relaciones
Más allá de limpiar la información de los vecinos, el método también aborda cómo el sistema representa las relaciones cuando solo observa un puñado de enlaces de ejemplo. En lugar de limitarse a promediar esos ejemplos, los autores construyen un “meta‑aprendiz” de relaciones. Trata todos los pares de ejemplo para una relación dada como una secuencia corta y los pasa por una unidad recurrente con compuertas (GRU) para capturar patrones entre los ejemplos. Un mecanismo de atención contextual permite luego al modelo centrarse más en los pares más informativos, mientras que una pequeña red feed‑forward refina adicionalmente la señal combinada. Conexiones residuales y normalización ayudan a estabilizar el aprendizaje. El resultado es una representación compacta y sensible a la tarea de la relación que captura diferencias sutiles en cómo interactúan las entidades, como la dirección, la intensidad o el tipo de conexión.
Aprender a adaptarse rápidamente con meta‑optimización
La pieza final del enfoque es un aprendiz de incrustaciones que utiliza ideas de meta‑aprendizaje —a menudo llamado “aprender a aprender.” Durante el entrenamiento, el sistema ve muchas relaciones diferentes como tareas pequeñas separadas. Para cada tarea, adapta brevemente sus parámetros usando solo los pocos ejemplos disponibles y luego comprueba qué tan bien funciona en nuevas consultas para esa relación. Los gradientes de este segundo paso actualizan un conjunto compartido de parámetros de modo que, con el tiempo, el modelo mejore en adaptarse rápidamente a relaciones completamente nuevas que nunca ha visto antes. El método se apoya en una técnica existente que sitúa entidades en superficies geométricas específicas de cada relación, y actualiza tanto la representación de la relación como estas superficies durante el meta‑aprendizaje, afinando aún más sus predicciones.
Qué significan los resultados para las herramientas de IA del día a día
Los autores prueban su método en dos conjuntos de datos de referencia muy usados, NELL‑One y Wiki‑One, y lo comparan con muchos sistemas de vanguardia para completado de grafos de conocimiento con pocos ejemplos. En varias medidas de evaluación, su enfoque rinde consistentemente mejor, especialmente cuando dispone de cinco enlaces de ejemplo por relación. Las mejoras son más notables en un conjunto de datos donde la información de los vecinos es más rica, lo que subraya el valor de la selección cuidadosa de vecinos y del meta‑aprendizaje de relaciones. Para aplicaciones cotidianas, esto significa que los sistemas de IA podrían completar con más fiabilidad piezas faltantes del conocimiento —como relaciones raras, conceptos especializados o hechos emergentes— incluso cuando solo hay un pequeño número de ejemplos disponibles, haciendo que herramientas posteriores como búsqueda, recomendación y respuesta a preguntas sean más precisas y robustas.
Cita: Yang, B., Peng, M., Liu, S. et al. Meta learning based few shot knowledge graph completion with domain selected aggregation. Sci Rep 16, 12333 (2026). https://doi.org/10.1038/s41598-026-42198-4
Palabras clave: grafos de conocimiento, aprendizaje con pocos ejemplos, meta‑aprendizaje, redes neuronales de grafos, predicción de enlaces