Clear Sky Science · de
Meta-Learning-basierte Few‑Shot-Ergänzung von Wissensgraphen mit domänen‑selektierter Aggregation
Warum es wichtig ist, Maschinen mit nur wenigen Beispielen zu lehren
Moderne KI‑Systeme stützen sich zunehmend auf umfangreiche „Wissensgraphen“, die Personen, Orte, Dinge und Ideen zu großen Netzen von Fakten verknüpfen. Diese Graphen treiben Suchmaschinen, Empfehlungssysteme und Frage‑Antwort‑Werkzeuge an. In der Praxis sind viele Verbindungen in diesen Graphen jedoch selten, schlecht dokumentiert oder ganz neu. Einer Maschine beizubringen, solche seltenen Verknüpfungen zu erkennen und zu vervollständigen, wenn nur eine Handvoll Beispiele existiert, ist schwierig. Dieses Paper stellt eine Methode vor, die der KI ermöglicht, aus sehr wenigen Proben zu lernen und gleichzeitig ablenkende Informationen herauszufiltern, sodass sie fehlende Fakten in einem Wissensgraphen genauer erraten kann.
Wissenskarten, aufgebaut aus einfachen Fakten
Ein Wissensgraph stellt Informationen als einfache dreiteilige Aussagen dar, wie „Person A arbeitet_für Firma B“ oder „Stadt C liegt_in Land D“. Jede Aussage verbindet zwei Entitäten über eine Relation, und Millionen solcher Verknüpfungen bilden zusammen eine Wissenslandkarte. Traditionelle Techniken wandeln jede Entität und Relation in Zahlen in einem mathematischen Raum um und lernen Regeln, die es dem System erlauben, neue Links vorherzusagen. Diese Verfahren funktionieren gut, wenn für jede Relation viele Beispiele vorhanden sind, wie bei „geboren_in“ oder „befindet_sich_in“, kommen jedoch ins Straucheln, wenn eine Relation nur wenige Male in den Daten auftaucht. In der Praxis sind seltene Relationen häufig — etwa eine spezifische Erkrankung, eine Nischenberufsbezeichnung oder eine neu entstandene Partnerschaft — daher ist die Verbesserung der Leistung in solchen Few‑Shot‑Fällen entscheidend.
Von Nachbarn lernen, ohne im Rauschen unterzugehen
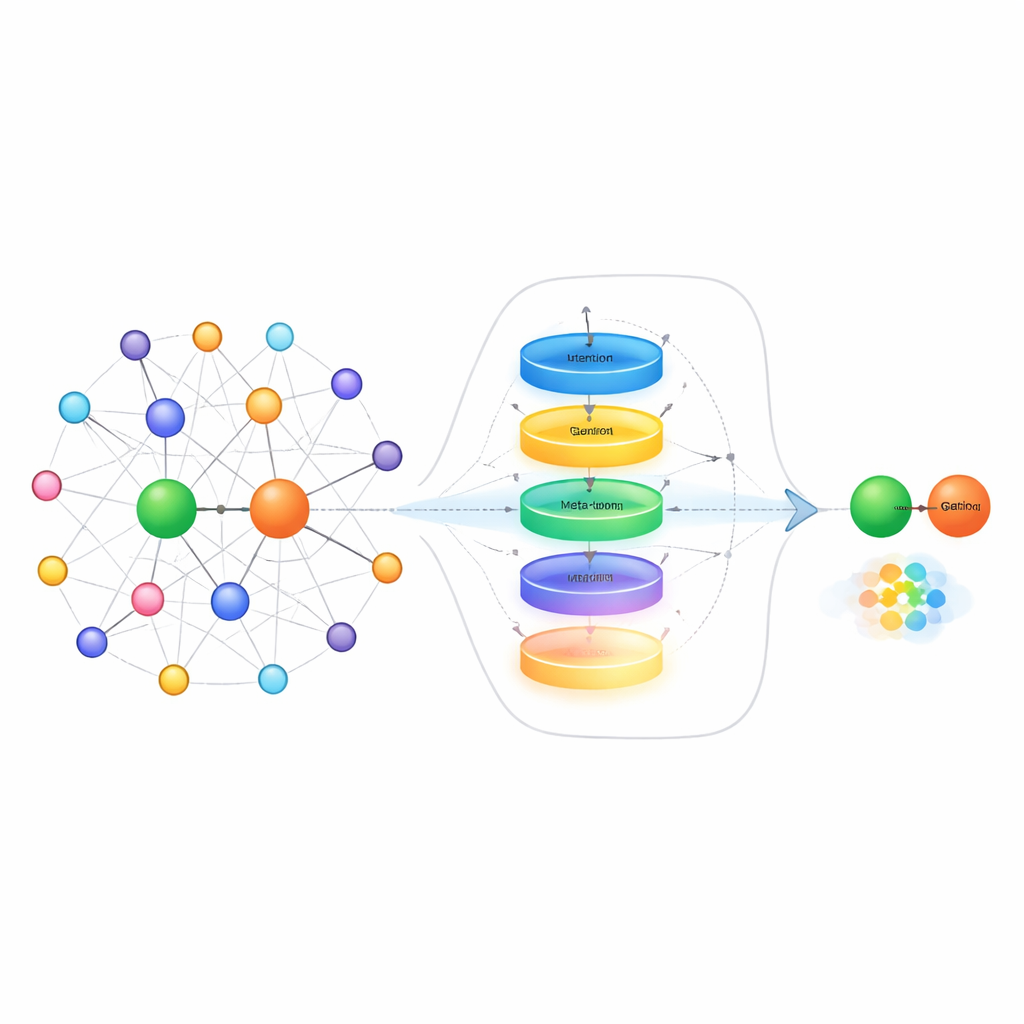
Eine Möglichkeit, mit wenigen Beispielen umzugehen, besteht darin, die „Nachbarn“ jeder Entität im Graphen zu betrachten — also die anderen Fakten, die direkt mit ihr verbunden sind. Beispielsweise hilft bei der Vorhersage des Ehepartners eher das Wissen über Familienmitglieder als über Geschäftspartner. Bestehende Methoden behandeln oft alle nahegelegenen Fakten als gleichermaßen nützlich, wodurch relevante Hinweise im Rauschen untergehen können. Die Autorinnen und Autoren schlagen ein Nachbarschaftsselektionsmodul vor, das zunächst jeden Nachbarn danach bewertet, wie relevant er ist, nur die bestbewerteten behält und dann einen von rekurrenten neuronalen Netzen inspirierten Gate‑Mechanismus nutzt, um zu entscheiden, wie stark diese Nachbarinformation die Repräsentation der Entität tatsächlich aktualisieren soll. Dieser zweistufige Prozess filtert sowohl thematisch unpassende Nachbarn heraus als auch balanciert dynamisch, was erinnert und was ignoriert wird — besonders nützlich, wenn nur wenige Trainingsbeispiele verfügbar sind.
Dem System beibringen, neue Relationen zu lernen
Über die Bereinigung der Nachbarschaftsinformation hinaus adressiert die Methode auch, wie das System Relationen selbst repräsentiert, wenn es nur wenige Beispiel‑Links sieht. Statt diese Beispiele einfach zu mitteln, bauen die Autorinnen und Autoren einen Relation‑Meta‑Learner auf. Dieser behandelt alle Beispielpaare einer Relation als kurze Sequenz und führt sie durch eine Gated Recurrent Unit, um Muster in den Beispielen zu erfassen. Ein kontextuelles Aufmerksamkeitsmechanismus erlaubt es dem Modell anschließend, sich stärker auf die informativsten Paare zu konzentrieren, während ein kleines Feed‑Forward‑Netz das kombinierte Signal weiter verfeinert. Residualverbindungen und Normalisierung stabilisieren das Lernen. Das Ergebnis ist eine kompakte, auf die Aufgabe abgestimmte Repräsentation der Relation, die subtile Unterschiede in der Interaktion von Entitäten einfängt, etwa Richtung, Stärke oder Typ der Verbindung.
Schnell anpassen lernen durch Meta‑Optimierung
Das abschließende Element des Ansatzes ist ein Embedding‑Learner, der Ideen aus dem Meta‑Lernen — oft „Lernen zu lernen“ genannt — nutzt. Während des Trainings sieht das System viele verschiedene Relationen als separate kleine Aufgaben. Für jede Aufgabe passt es seine Parameter kurz mit nur den wenigen verfügbaren Beispielen an und prüft dann, wie gut es auf neuen Abfragen für diese Relation abschneidet. Die Gradienten aus diesem zweiten Schritt aktualisieren einen gemeinsamen Parametersatz, sodass das Modell im Laufe der Zeit besser darin wird, sich schnell an völlig neue, zuvor unbekannte Relationen anzupassen. Die Methode baut auf einer bestehenden Technik auf, die Entitäten auf relationsspezifischen geometrischen Flächen anordnet, und aktualisiert sowohl die Repräsentation der Relation als auch diese Flächen während des Meta‑Learnings, was die Vorhersagen weiter schärft.
Was die Ergebnisse für alltägliche KI‑Werkzeuge bedeuten
Die Autorinnen und Autoren testen ihre Methode auf zwei weit verbreiteten Benchmark‑Datensätzen, NELL‑One und Wiki‑One, und vergleichen sie mit vielen aktuellen State‑of‑the‑Art‑Systemen für Few‑Shot‑Wissensgraph‑Ergänzung. Über mehrere Bewertungsmaße schneidet ihr Ansatz durchweg besser ab, besonders wenn er fünf Beispiels‑Links pro Relation hat. Die Verbesserungen sind am deutlichsten bei einem Datensatz ausgeprägt, in dem Nachbarinformationen reicher sind, was den Wert sorgfältiger Nachbarschaftsselektion und Relation‑Meta‑Learning unterstreicht. Für Alltagsanwendungen bedeutet dies, dass KI‑Systeme fehlende Wissensstücke — etwa seltene Beziehungen, spezialisierte Konzepte oder neue Fakten — zuverlässiger ergänzen können, selbst wenn nur wenige Beispiele vorliegen, und dadurch nachgelagerte Werkzeuge wie Suche, Empfehlung und Fragebeantwortung genauer und robuster werden.
Zitation: Yang, B., Peng, M., Liu, S. et al. Meta learning based few shot knowledge graph completion with domain selected aggregation. Sci Rep 16, 12333 (2026). https://doi.org/10.1038/s41598-026-42198-4
Schlüsselwörter: Wissensgraphen, Few‑Shot‑Lernen, Meta‑Lernen, Graph‑Neuronale Netze, Link‑Vorhersage