Clear Sky Science · pt
Estimativa de postura humana com IMUs vestíveis leves baseada em design centrado no humano
Por que rastreamento corporal mais rápido importa
De clínicas de fisioterapia a headsets de realidade virtual, muitas tecnologias modernas dependem de entender como nossos corpos se movem em tempo real. Hoje isso muitas vezes exige câmeras, marcadores ou computadores volumosos que são difíceis de usar o dia todo. Este estudo explora como pequenos sensores de movimento, semelhantes aos de smartphones e smartwatches, podem ser combinados com algoritmos inteligentes para estimar a pose corporal completa quase instantaneamente, consumindo pouquíssima energia. O objetivo é simples: tornar o rastreamento de movimento suficientemente preciso para uso sério, mas leve e eficiente o bastante para desaparecer em dispositivos vestíveis do dia a dia.
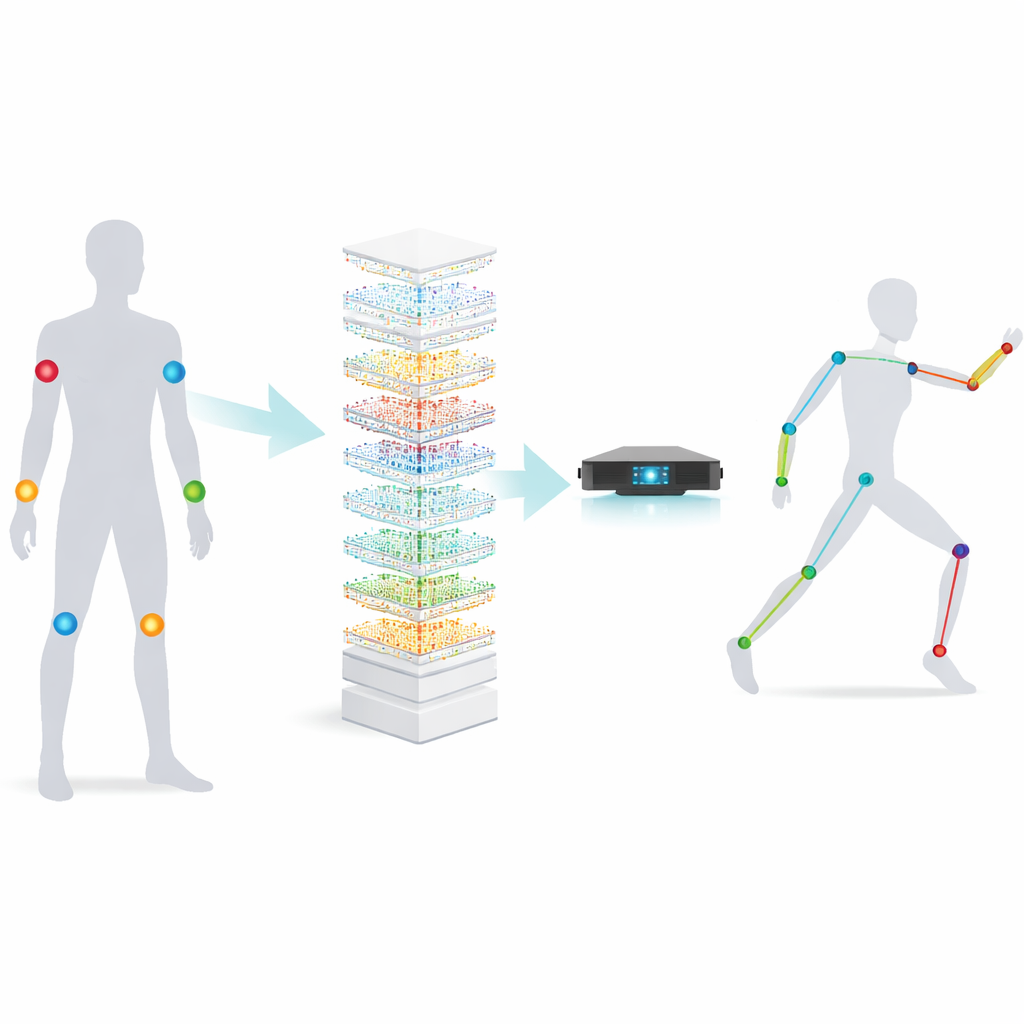
Pequenos sensores, grandes movimentos
O trabalho foca em unidades de medição inercial, ou IMUs — aparelhos do tamanho de uma caixa de fósforos que medem aceleração e rotação. Colocadas em alguns pontos-chave do corpo, as IMUs conseguem detectar como nos movemos mesmo quando câmeras não conseguem nos ver, como em ambientes lotados ou ao ar livre à noite. O desafio é transformar essas leituras brutas dos sensores em uma pose corporal 3D detalhada: o dispositivo tem apenas alguns sinais, mas precisa inferir as posições de muitas articulações, em muitas pessoas diferentes, executando ações variadas. Métodos anteriores usavam redes neurais grandes, como redes recorrentes profundas e Transformers, que são precisas, mas pesadas — exigem muita memória, energia e tempo, tornando-as inadequadas para dispositivos vestíveis pequenos.
Ensinar um modelo pequeno a pensar como um grande
Os autores propõem uma estratégia em duas etapas inspirada em como um aluno aprende com um professor. Durante o treinamento em laboratório, eles usam um modelo Transformer grande e poderoso como “professor” para analisar profundamente os dados dos sensores ao longo do tempo e entre locais do corpo. Em paralelo, projetam um modelo menor, o “aluno”, construído a partir de uma operação chamada involution, que pode se adaptar flexivelmente a padrões locais nos dados enquanto usa bem menos parâmetros que a convolução padrão. Por meio de um processo conhecido como destilação de conhecimento, o aluno não apenas iguala as saídas finais de pose; ele também é orientado a imitar os padrões internos de características do professor. Assim, o aluno gradualmente absorve truques de alto nível para interpretar movimento a partir dos sensores sem precisar do tamanho e da complexidade do professor quando implantado.
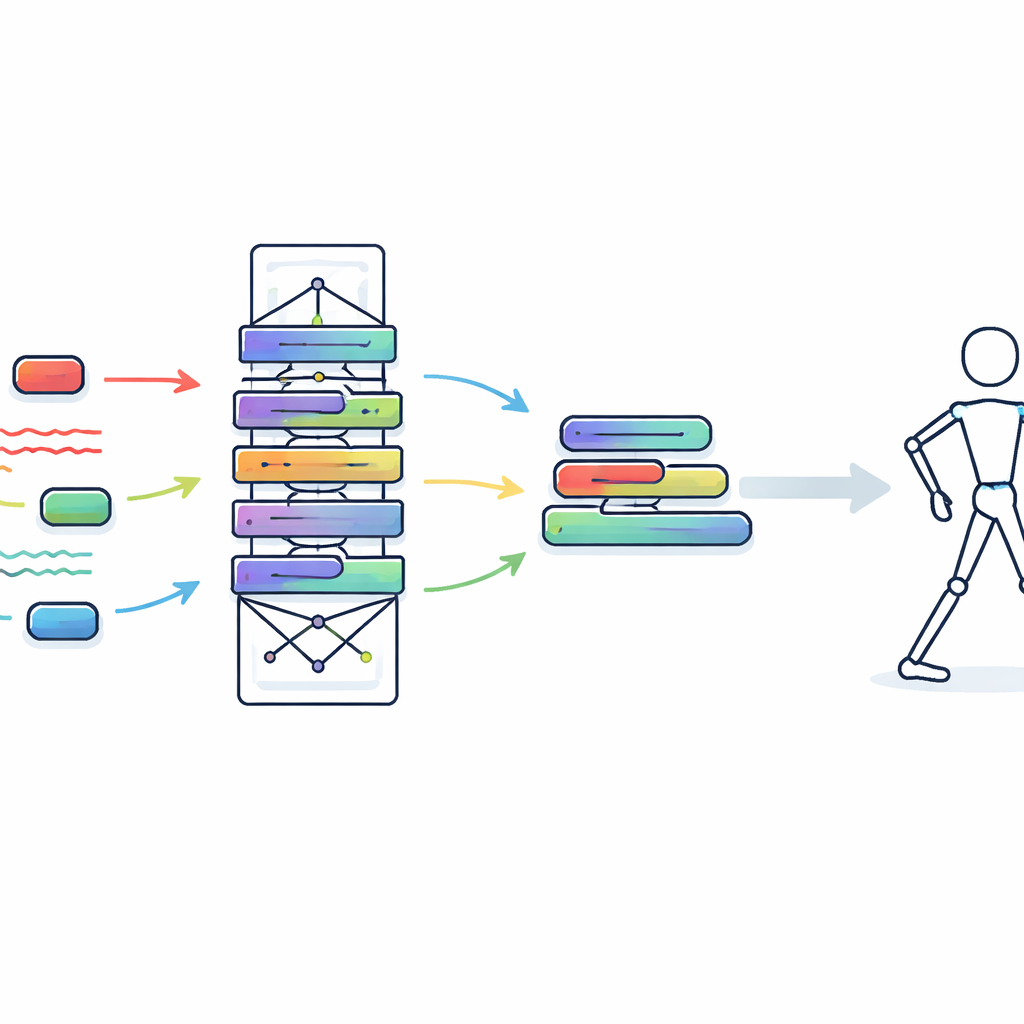
Transformando uma rede de treinamento em um motor de execução minúsculo
Para tornar o modelo aluno realmente adequado a vestíveis, os pesquisadores vão além com um procedimento chamado reparametrização estrutural. Durante o treinamento, o bloco do aluno inclui vários ramos, etapas de normalização e kernels adaptativos para maximizar a flexibilidade de aprendizagem. Antes da implantação, todas essas peças são matematicamente fundidas em uma única computação simplificada que se comporta como duas convoluções unidimensionais simples. Esse processo de dobramento preserva o comportamento do modelo, mas elimina camadas e operações extras. Como a convolução padrão é fortemente otimizada em hardware moderno, essa transformação reduz drasticamente o tempo e a energia necessários para processar cada quadro, sem sacrificar o que a rede aprendeu.
Quão bem isso funciona na prática?
A equipe avalia sua abordagem em dois conjuntos de dados públicos de movimento, DIP-IMU e IMUPoser, que contêm milhões de quadros de pessoas realizando atividades cotidianas e atléticas, capturadas simultaneamente com IMUs e sistemas de captura de movimento de alta precisão. Seu modelo leve iguala ou aproxima-se dos melhores métodos existentes em erro médio por articulação — 81 milímetros no DIP-IMU e 94 milímetros no IMUPoser, dentro de cerca de 1% das linhas de base mais fortes. Ao mesmo tempo, ele é de uma a duas ordens de magnitude mais rápido: cada quadro é processado em aproximadamente 0,011–0,012 milissegundos, comparado com várias décimas de milissegundo até quase um milissegundo para sistemas concorrentes. Essa velocidade se traduz em dezenas de milhares de quadros por segundo em uma GPU, muito além do que qualquer dispositivo vestível realmente precisa, deixando ampla margem para economia de bateria e outras tarefas no dispositivo.
O que isso significa para vestíveis do dia a dia
Para o público em geral, a conclusão principal é que os autores encontraram uma maneira de separar “pensar profundamente” de “agir rapidamente”. Um modelo grande pode pensar profundamente durante o treinamento para entender o movimento humano em detalhe, enquanto um modelo muito menor — cuidadosamente ensinado e então simplificado — lida com o trabalho em tempo real no seu relógio, headset ou órtese de reabilitação. O resultado é um rastreamento corporal quase tão preciso quanto sistemas de laboratório pesados, mas enxuto o bastante para dispositivos de baixa potência e sempre ligados. Isso abre caminho para vestíveis que podem fornecer feedback em tempo hábil durante exercícios, alertar sobre movimentos inseguros no trabalho ou fazer mundos virtuais responderem de forma mais natural aos nossos corpos, tudo isso sem hardware volumoso ou consumo rápido de bateria.
Citação: Wang, L., Liu, J., Xue, J. et al. Human-centered design-based lightweight wearable IMU human pose estimation. Sci Rep 16, 11420 (2026). https://doi.org/10.1038/s41598-026-41004-5
Palavras-chave: sensores vestíveis, estimativa de postura humana, unidades de medição inercial, redes neurais leves, rastreamento de movimento em tempo real