Clear Sky Science · it
Stima della posa umana con IMU indossabili leggere basata sul design centrato sull’uomo
Perché il tracciamento corporeo più veloce conta
Dai centri di fisioterapia ai visori per realtà virtuale, molte tecnologie moderne dipendono dalla capacità di comprendere come si muovono i nostri corpi in tempo reale. Oggi questo richiede spesso telecamere, marcatori o computer ingombranti difficili da indossare tutto il giorno. Questo studio esplora come piccoli sensori di movimento, simili a quelli presenti in smartphone e smartwatch, possano essere combinati con algoritmi intelligenti per stimare la posa dell’intero corpo quasi istantaneamente, usando pochissima energia. L’obiettivo è semplice: rendere il tracciamento del movimento sufficientemente accurato per usi seri, ma così leggero ed efficiente da poter scomparire negli indossabili di uso quotidiano.
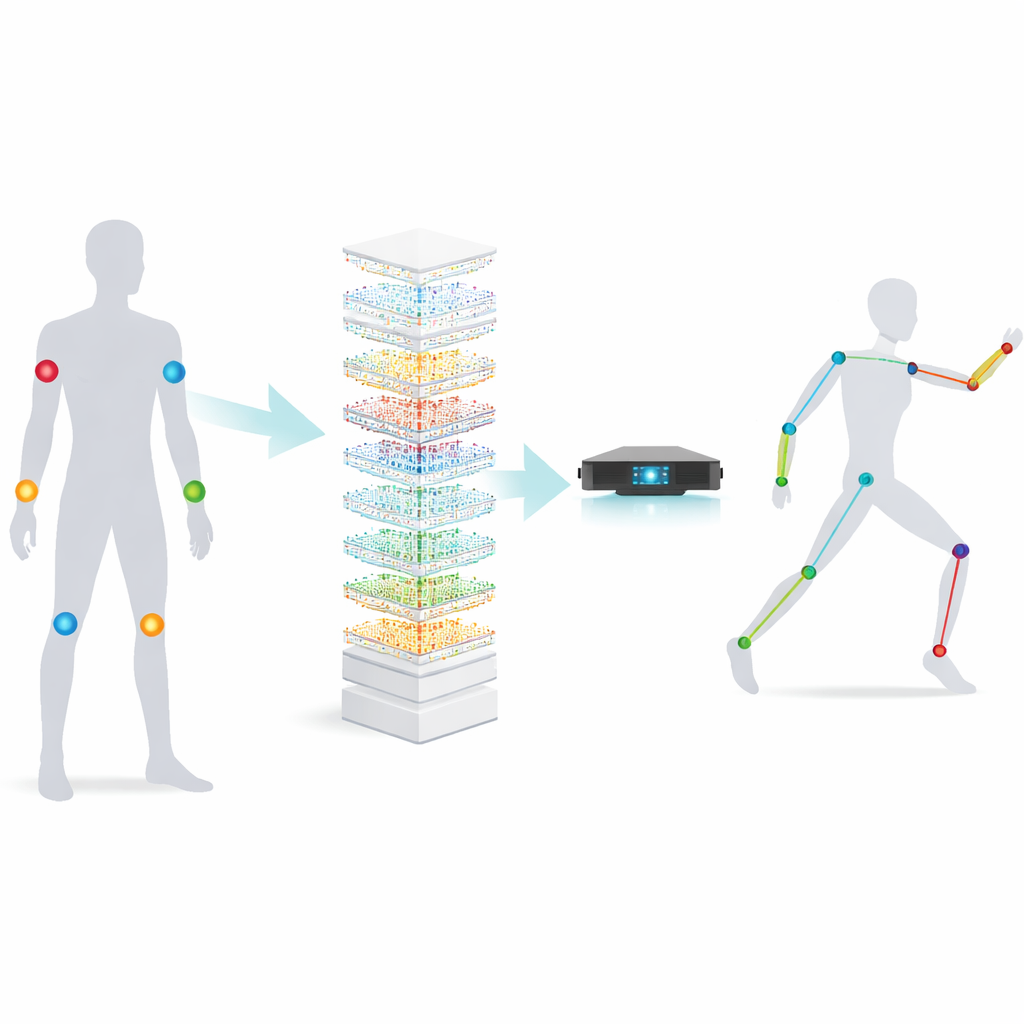
Piccoli sensori, grandi movimenti
Il lavoro si concentra sulle unità di misura inerziale, o IMU—dispositivi grandi come una scatola di fiammiferi che misurano accelerazione e rotazione. Posizionati in alcuni punti chiave del corpo, le IMU possono rilevare come ci muoviamo anche quando le telecamere non ci vedono, ad esempio in ambienti affollati o all’aperto di notte. La sfida è che trasformare queste letture grezze dei sensori in una posa 3D dettagliata è un puzzle complesso: il dispositivo dispone solo di pochi segnali, eppure deve inferire le posizioni di molte articolazioni, in persone diverse e durante attività molto varie. I metodi precedenti usavano grandi reti neurali, come reti ricorrenti profonde e Transformer, che sono accurate ma pesanti—richiedono molta memoria, energia e tempo, rendendole poco adatte a dispositivi indossabili piccoli.
Insegnare a un modello piccolo a pensare come uno grande
Gli autori propongono una strategia in due fasi ispirata a come uno studente impara da un insegnante. Durante l’addestramento in laboratorio, usano un grande e potente modello Transformer come “insegnante” per analizzare a fondo i dati dei sensori nel tempo e tra le diverse posizioni corporee. In parallelo progettano un modello “studente” più piccolo costruito su un’operazione chiamata involution, che può adattarsi in modo flessibile ai pattern locali nei dati pur impiegando molti meno parametri rispetto alla convoluzione standard. Attraverso un processo noto come distillazione della conoscenza, lo studente non si limita a riprodurre le pose finali; viene anche spinto a imitare i pattern di feature interni dell’insegnante. In questo modo lo studente apprende gradualmente trucchi di alto livello per leggere il movimento dai sensori senza necessitare della dimensione e della complessità dell’insegnante una volta distribuito.
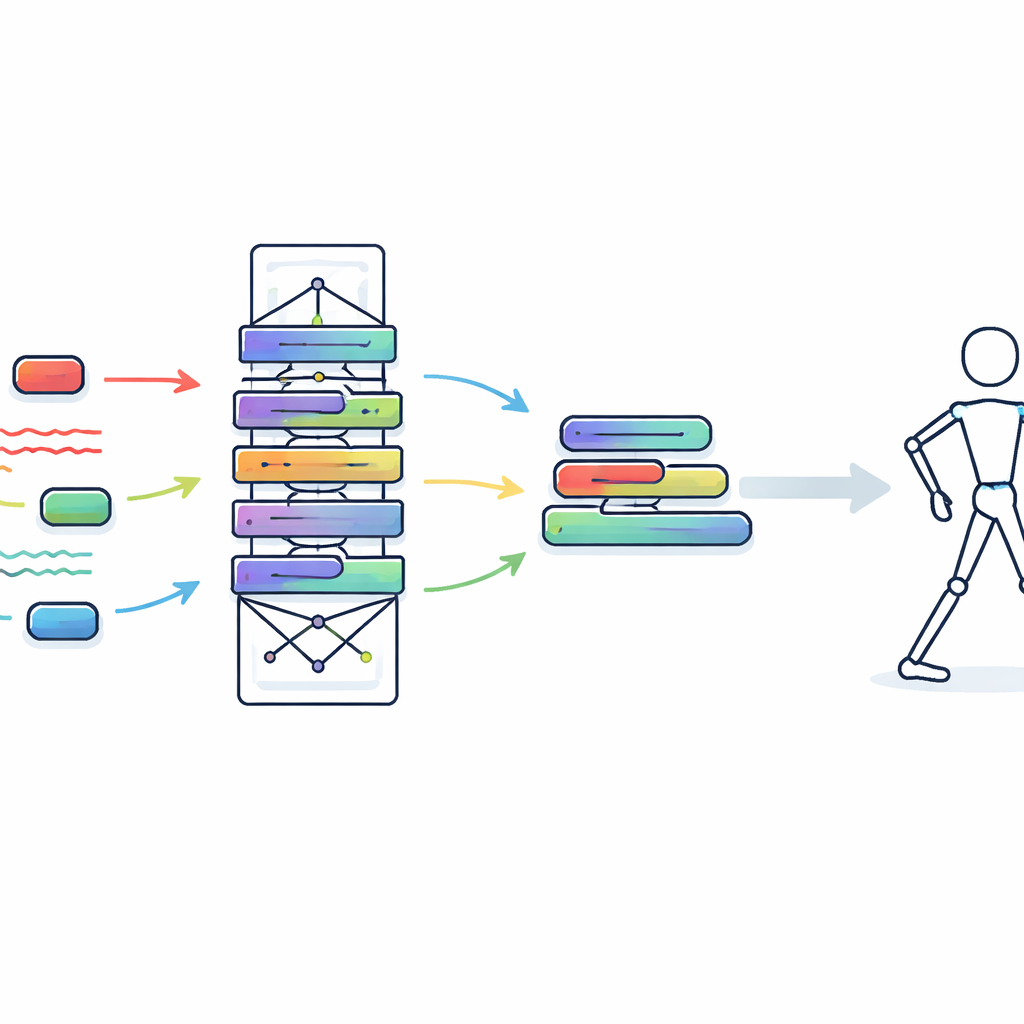
Trasformare una rete di addestramento in un motore di runtime minuscolo
Per rendere il modello studente realmente adatto agli indossabili, i ricercatori fanno un passo ulteriore con una procedura chiamata ri-parametrizzazione strutturale. Durante l’addestramento, il blocco studente include diverse diramazioni, passaggi di normalizzazione e kernel adattivi per massimizzare la flessibilità di apprendimento. Prima della distribuzione, tutti questi elementi vengono matematicamente fusi in un unico calcolo semplificato che si comporta come due semplici convoluzioni unidimensionali. Questo processo di piegatura preserva il comportamento del modello ma elimina strati e operazioni extra. Poiché la convoluzione standard è fortemente ottimizzata sull’hardware moderno, questa trasformazione riduce drasticamente il tempo e l’energia necessari per processare ogni frame, senza sacrificare ciò che la rete ha appreso.
Quanto funziona bene nella pratica?
Il team valuta il proprio approccio su due dataset pubblici di movimento, DIP-IMU e IMUPoser, che contengono milioni di frame di persone che eseguono attività quotidiane e atletiche, catturate simultaneamente con IMU e sistemi di motion capture ad alta precisione. Il loro modello leggero eguaglia o si avvicina molto ai migliori metodi esistenti nell’errore medio per articolazione—81 millimetri su DIP-IMU e 94 millimetri su IMUPoser, entro circa l’1% delle baseline più forti. Allo stesso tempo, gira con una velocità da uno a due ordini di grandezza superiore: ogni frame viene processato in circa 0,011–0,012 millisecondi, rispetto a diverse decine di millesimi fino quasi a un millisecondo per i sistemi concorrenti. Questa velocità si traduce in decine di migliaia di frame al secondo su una GPU, ben oltre quanto un dispositivo indossabile debba realmente supportare, lasciando ampio margine per risparmio della batteria e altri compiti on-device.
Cosa significa questo per gli indossabili di tutti i giorni
Per i non specialisti, la conclusione chiave è che gli autori hanno trovato un modo per separare il “pensare intensamente” dall’“agire rapidamente”. Un modello grande può pensare intensamente durante l’addestramento per comprendere il movimento umano in dettaglio, mentre un modello molto più piccolo—accuratamente istruito e poi semplificato—gestisce il lavoro in tempo reale sul tuo braccialetto, visore o tutore riabilitativo. Il risultato è un tracciamento corporeo quasi altrettanto accurato quanto i sistemi di laboratorio pesanti ma sufficientemente snello per dispositivi a basso consumo, sempre attivi. Questo apre la strada a indossabili in grado di fornire feedback tempestivi durante l’esercizio, avvertire di movimenti pericolosi sul lavoro o far rispondere i mondi virtuali in modo più naturale ai nostri corpi, il tutto senza hardware ingombrante o rapido consumo della batteria.
Citazione: Wang, L., Liu, J., Xue, J. et al. Human-centered design-based lightweight wearable IMU human pose estimation. Sci Rep 16, 11420 (2026). https://doi.org/10.1038/s41598-026-41004-5
Parole chiave: sensori indossabili, stima della posa umana, unità di misura inerziale, reti neurali leggere, tracciamento del movimento in tempo reale