Clear Sky Science · de
Leichtgewichtige, auf Human-centered Design basierende tragbare IMU-Körperpose-Schätzung
Warum schnellere Körperverfolgung wichtig ist
Von Physiotherapie-Kliniken bis zu Virtual-Reality-Brillen bauen viele neue Technologien darauf, zu verstehen, wie sich unser Körper in Echtzeit bewegt. Heute erfordert das oft Kameras, Marker oder sperrige Computer, die sich nur schwer den ganzen Tag tragen lassen. Diese Studie untersucht, wie winzige Bewegungssensoren, ähnlich denen in Smartphones und Smartwatches, mit schlauen Algorithmen kombiniert werden können, um die vollständige Körperpose nahezu sofort und mit sehr geringem Energieaufwand zu schätzen. Das Ziel ist einfach: Bewegungsverfolgung so genau zu machen, dass sie für ernsthafte Anwendungen taugt, aber so leicht und effizient, dass sie in Alltags-Wearables verschwindet.
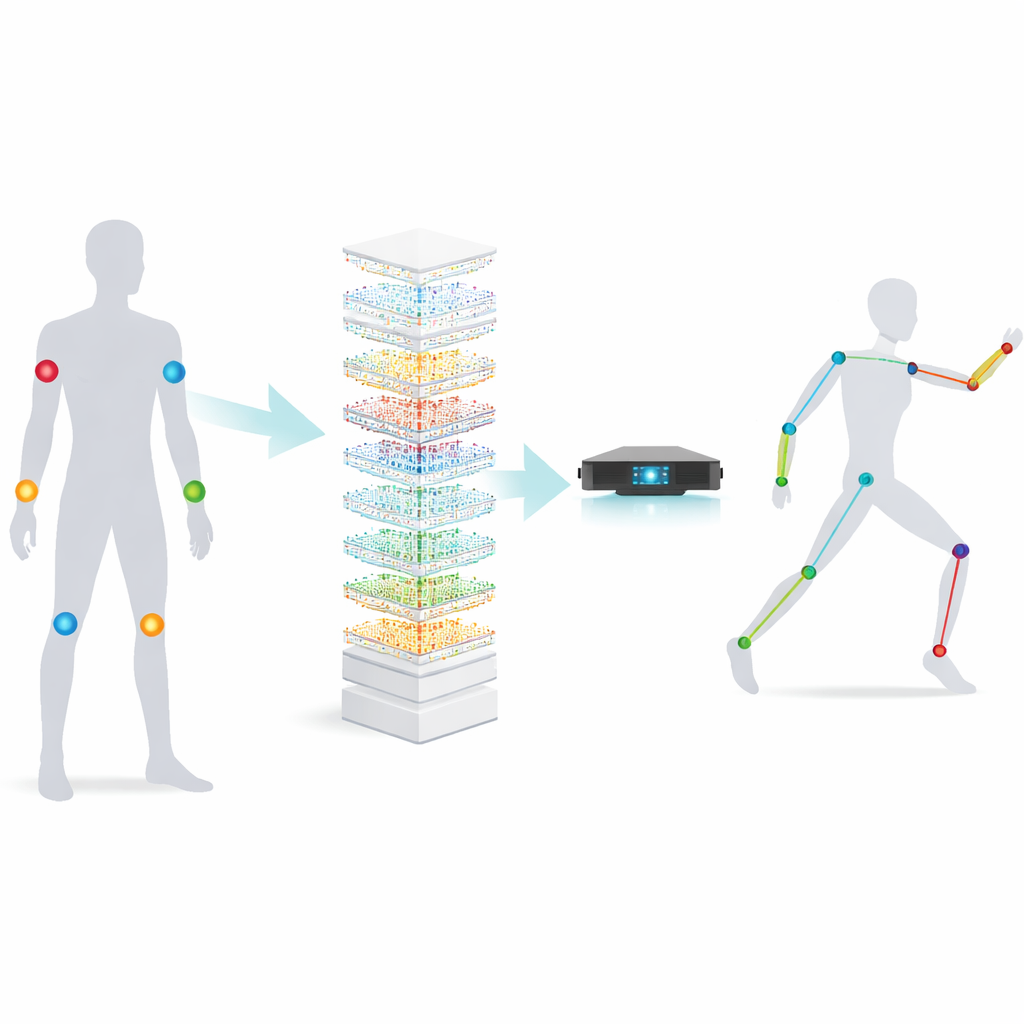
Kleine Sensoren, große Bewegungen
Im Mittelpunkt der Arbeit stehen Trägheitsmesseinheiten, oder IMUs – zündholzschachtelgroße Geräte, die Beschleunigung und Rotation messen. An einigen wenigen Schlüsselstellen am Körper platziert, können IMUs erfassen, wie wir uns bewegen, selbst wenn Kameras uns nicht sehen können, etwa in überfüllten Räumen oder nachts im Freien. Die Herausforderung besteht darin, diese rohen Sensordaten in eine detaillierte 3D-Körperpose zu übersetzen: Das Gerät liefert nur eine Handvoll Signale, muss aber die Position vieler Gelenke bei unterschiedlichen Personen und Aktivitäten erschließen. Frühere Methoden nutzten große neuronale Netze, etwa tiefe rekurrente Netze und Transformer, die zwar präzise sind, aber schwergewichtig – sie benötigen viel Speicher, Energie und Zeit und eignen sich daher nur schlecht für kleine, tragbare Geräte.
Ein kleines Modell so lehren, dass es wie ein großes denkt
Die Autoren schlagen eine zweistufige Strategie vor, inspiriert davon, wie ein Schüler von einem Lehrer lernt. Während des Trainings im Labor verwenden sie ein großes, leistungsfähiges Transformer-Modell als „Lehrer“, das die Sensordaten zeitlich und über Körperpositionen hinweg tiefgehend analysiert. Parallel dazu entwerfen sie ein kleineres „Schüler“-Modell, das aus einer Operation namens Involution aufgebaut ist und sich flexibel an lokale Muster in den Daten anpassen kann, dabei aber deutlich weniger Parameter als Standardkonvolutionen benötigt. Durch Knowledge Distillation wird der Schüler nicht nur darauf trainiert, die finalen Pose-Ausgaben nachzubilden; er wird auch dazu angeleitet, die internen Merkmalsmuster des Lehrers zu imitieren. Auf diese Weise übernimmt der Schüler schrittweise fortgeschrittene Tricks zum Lesen von Bewegungen aus Sensoren, ohne nach der Bereitstellung die Größe und Komplexität des Lehrers zu benötigen.
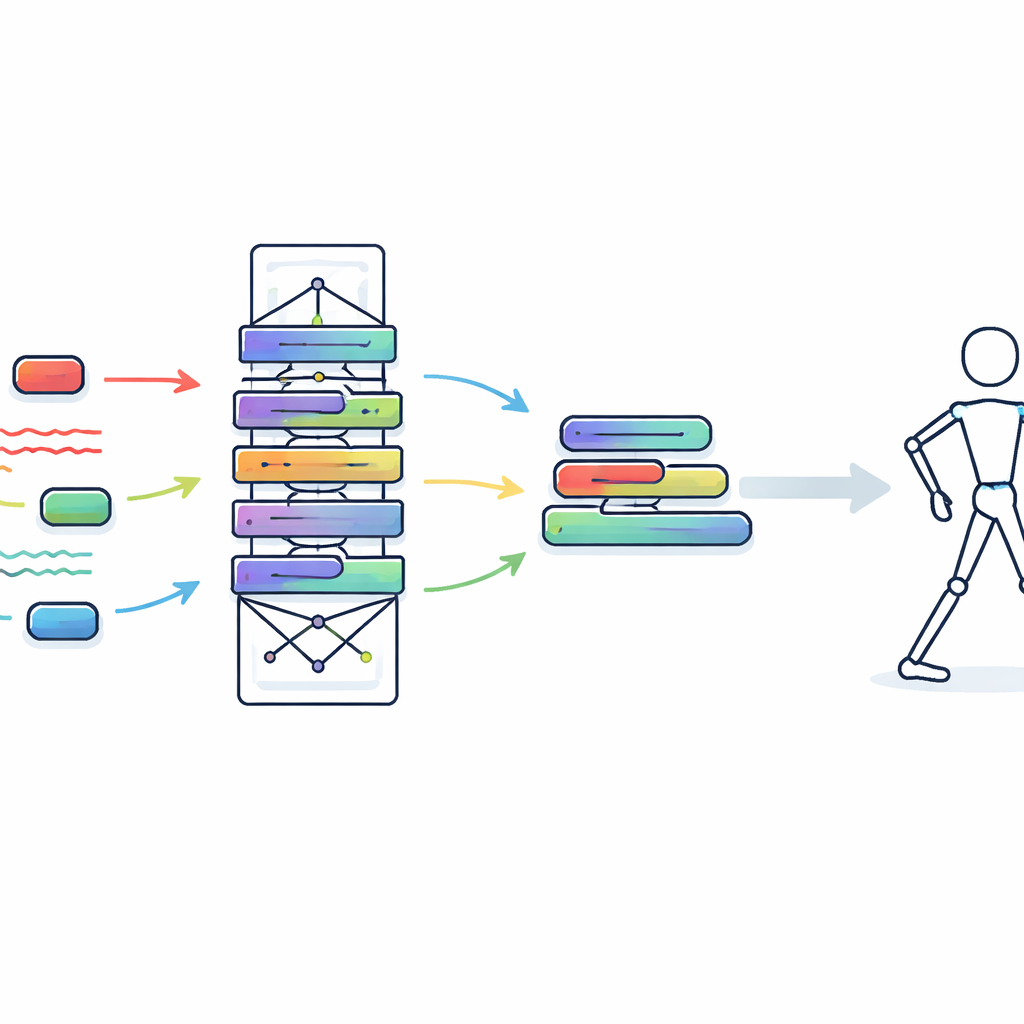
Aus einem Trainingsnetzwerk eine winzige Laufzeit-Engine machen
Um das Schüler-Modell wirklich tragbar-freundlich zu machen, gehen die Forscher einen Schritt weiter mit einem Verfahren namens strukturelle Re-Parameterisierung. Während des Trainings enthält der Schüler-Block mehrere Zweige, Normalisierungsschritte und adaptive Kernel, um maximale Lernflexibilität zu gewährleisten. Vor der Bereitstellung werden all diese Teile mathematisch in eine einzige, gestraffte Berechnung zusammengeführt, die sich wie zwei einfache eindimensionale Faltungen verhält. Dieser Faltungsprozess erhält das Verhalten des Modells, beseitigt aber zusätzliche Schichten und Operationen. Da Standardfaltung auf moderner Hardware stark optimiert ist, reduziert diese Transformation drastisch die Zeit und Energie, die zur Verarbeitung jedes Frames benötigt werden, ohne das Gelernte zu opfern.
Wie gut funktioniert das in der Praxis?
Das Team bewertet seinen Ansatz an zwei öffentlichen Bewegungsdatensätzen, DIP-IMU und IMUPoser, die Millionen von Frames von Personen enthalten, die Alltags- und Sportaktivitäten ausführen, simultan mit IMUs und hochpräzisen Motion-Capture-Systemen erfasst. Ihr leichtes Modell erreicht oder kommt den besten bestehenden Methoden beim durchschnittlichen Gelenkfehler nahe – 81 Millimeter auf DIP-IMU und 94 Millimeter auf IMUPoser, innerhalb von etwa 1 % der stärksten Baselines. Gleichzeitig ist es ein bis zwei Größenordnungen schneller: Jedes Frame wird in etwa 0,011–0,012 Millisekunden verarbeitet, verglichen mit mehreren Zehnteln einer Millisekunde bis zu nahezu einer Millisekunde bei konkurrierenden Systemen. Diese Geschwindigkeit entspricht Zehntausenden von Frames pro Sekunde auf einer GPU, deutlich mehr als ein Wearable tatsächlich benötigt, und bietet damit Spielraum für Akkueinsparungen und andere On-Device-Aufgaben.
Was das für alltägliche Wearables bedeutet
Für Nicht-Spezialisten ist die wichtigste Erkenntnis, dass die Autoren einen Weg gefunden haben, „hartes Denken“ von „schnellem Handeln“ zu trennen. Ein großes Modell kann während des Trainings intensiv analysieren, um menschliche Bewegung detailliert zu erfassen, während ein viel kleineres Modell – sorgfältig unterrichtet und anschließend vereinfacht – die Echtzeitaufgaben an deinem Armband, Headset oder Rehabilitationsorthese übernimmt. Das Ergebnis ist eine Körperverfolgung, die fast so genau ist wie schwere Laborsysteme, aber schlank genug für energiearme, immer eingeschaltete Geräte. Das ebnet den Weg für Wearables, die beim Training zeitnahe Rückmeldungen geben, vor unsicheren Bewegungen am Arbeitsplatz warnen oder virtuelle Welten natürlicher auf unseren Körper reagieren lassen – und das ohne sperrige Hardware oder schnellen Akkuverbrauch.
Zitation: Wang, L., Liu, J., Xue, J. et al. Human-centered design-based lightweight wearable IMU human pose estimation. Sci Rep 16, 11420 (2026). https://doi.org/10.1038/s41598-026-41004-5
Schlüsselwörter: tragbare Sensoren, Körperpose-Schätzung, Trägheitsmesseinheiten, leichte neuronale Netze, Echtzeit-Bewegungsverfolgung