Clear Sky Science · pt
Transformador de atenção multidimensional para detecção de veículos e pedestres em tempo adverso
Por que ver através de tempo ruim importa
Carros modernos e câmeras urbanas estão aprendendo a “ver” a via por nós, identificando veículos e pedestres tão rapidamente que podem ajudar a evitar acidentes. Mas chuva, neblina e escuridão ainda confundem muitos desses sistemas, ocultando pessoas e carros justamente quando a segurança é mais importante. Este artigo apresenta o MDAT‑YOLO, um novo modelo de visão computacional projetado para continuar detectando usuários da via de forma rápida e confiável, mesmo em neblina densa, chuva forte e pouca luz.
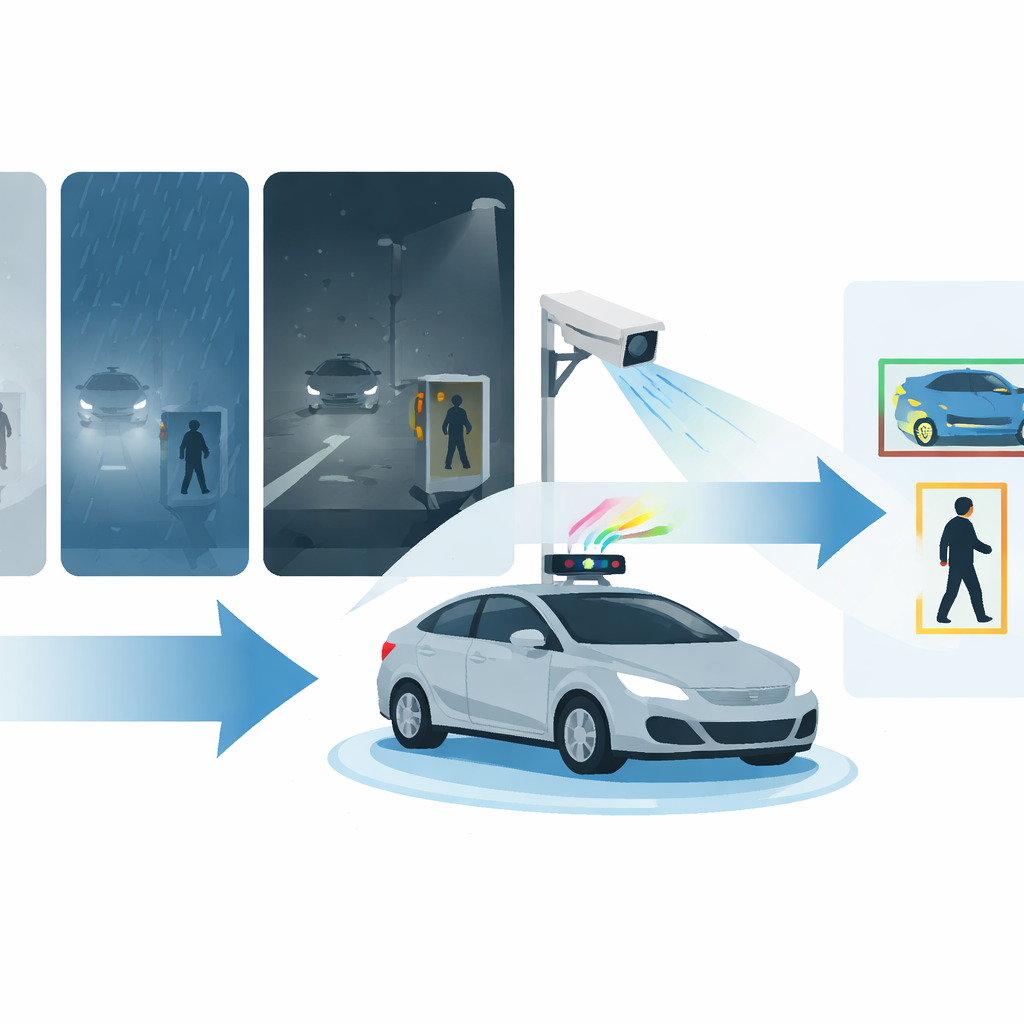
O desafio de dirigir no mundo real
Ao longo dos anos, pesquisadores melhoraram a detecção automática de objetos usando poderosos modelos de aprendizado profundo, como o YOLO, que escaneiam imagens e marcam carros, ônibus, bicicletas e pessoas em tempo real. A maioria desses modelos, porém, é treinada e ajustada em condições claras e diurnas. Quando a visibilidade cai — à noite, na neblina ou durante um temporal — os objetos ficam tênues, borrados ou parcialmente ocultos. Usuários da via pequenos ou distantes são especialmente fáceis de perder. Abordagens existentes frequentemente se especializam em um único tipo de tempo ruim, ou juntam várias redes pesadas que ficam lentas e complexas demais para uso em tempo real na direção e na vigilância.
Uma maneira mais inteligente de focar no que importa
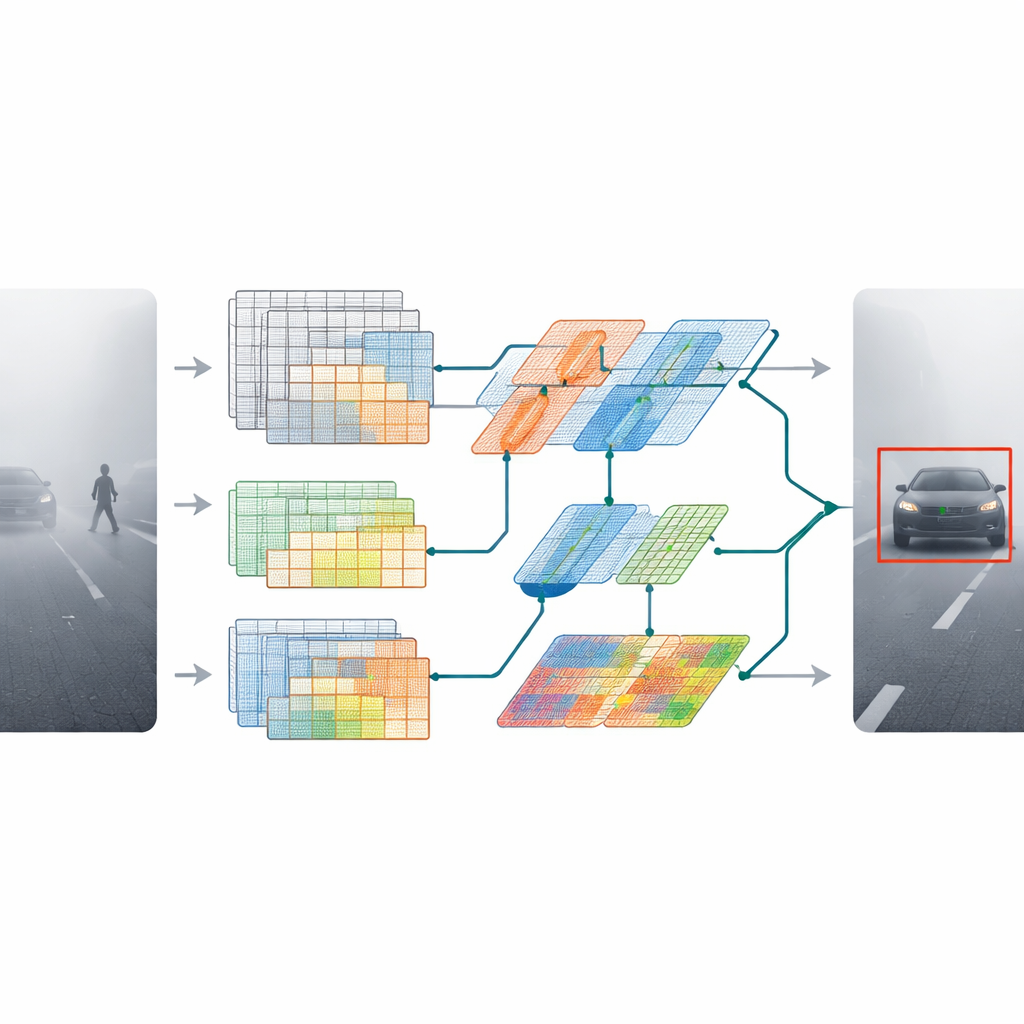
O MDAT‑YOLO parte de uma versão compacta de um detector popular e redesenha seus blocos internos para que ele possa se adaptar a cenas difíceis, em vez de tratar cada imagem da mesma forma rígida. A ideia-chave é permitir que o modelo decida, dinamicamente, onde concentrar sua atenção em uma imagem e como processar diferentes tipos de padrões visuais. Dois novos componentes impulsionam esse comportamento. Uma camada de convolução depthwise otimizada redefine como a informação flui entre os canais de cor, tornando a rede mais leve e ao mesmo tempo mais expressiva. Um segundo módulo, chamado convolução dinâmica omnidimensional, ajusta seus filtros não apenas no espaço, mas também através de diferentes canais de característica e conjuntos alternativos de filtros. Juntos, eles permitem que o modelo responda de forma diferente à neblina densa, ao brilho forte ou às faixas de chuva sem reduzir a velocidade.
Adicionar contexto global sem perder velocidade
Além de aprimorar detalhes locais, os autores deram ao modelo uma melhor noção da cena como um todo. Eles introduziram um bloco transformador leve — comumente usado em modelos de linguagem — que aprende relações de longo alcance na imagem. Em vez de aplicar um transformador grande e caro por toda parte, eles integram uma versão enxuta em estágios chave da rede. Isso ajuda o detector a entender que um contorno tênue ao longe provavelmente é um carro na via, e não ruído aleatório, e que pequenos aglomerados de pixels podem pertencer a um pedestre parcialmente escondido por névoa ou chuva.
Testando o modelo em condições difíceis
Para avaliar se essas mudanças de projeto realmente ajudam, os pesquisadores testaram o MDAT‑YOLO em várias coleções de imagens exigentes. Estas incluem um conjunto real de neblina, névoa e chuva; um conjunto noturno de baixa luminosidade; uma versão nebulosa recém-criada de um benchmark bem conhecido; e um conjunto de cenas de chuva reais. Em todas elas, o novo modelo detectou carros, ônibus, motocicletas, bicicletas e pessoas com mais precisão do que muitas variantes recentes do YOLO e outros métodos avançados. Foi especialmente eficaz na detecção de veículos em neblina intensa e de pessoas em cenas escuras. Igualmente importante, o modelo manteve velocidades em tempo real, processando até cerca de 145 imagens por segundo em hardware moderno — rápido o suficiente para uso em veículos em movimento e monitoramento de tráfego ao vivo.
O que isso significa para a segurança do dia a dia
Em termos simples, o MDAT‑YOLO é um avanço rumo a câmeras e computadores embarcados que continuam a funcionar de forma confiável quando o tempo piora. Ao combinar blocos eficientes com atenção flexível e contexto global, o sistema “olha mais de perto” objetos tênues, pequenos ou parcialmente ocultos sem se tornar volumoso ou lento. Embora sejam necessários mais testes em dados reais mais amplos, os resultados sugerem que futuros sistemas de assistência ao motorista, carros autônomos e câmeras de via podem deixar de perder menos usuários da via na névoa, chuva e escuridão — ajudando a tornar as ruas mais seguras mesmo nos piores dias.
Citação: Biswas, S., Kumar, J., Mitra, A. et al. Multi-dimensional attention transformer for vehicle and pedestrian detection in adverse weather. Sci Rep 16, 12624 (2026). https://doi.org/10.1038/s41598-026-40319-7
Palavras-chave: condução autônoma, detecção de objetos, condições adversas, visão computacional, segurança no trânsito