Clear Sky Science · en
Multi-dimensional attention transformer for vehicle and pedestrian detection in adverse weather
Why seeing through bad weather matters
Modern cars and city cameras are learning to “see” the road for us, spotting vehicles and pedestrians so fast that they can help avoid accidents. But rain, fog, and darkness still confuse many of these systems, hiding people and cars right when safety matters most. This paper introduces MDAT‑YOLO, a new computer-vision model designed to keep detecting road users quickly and reliably even in thick fog, heavy rain, and low light.
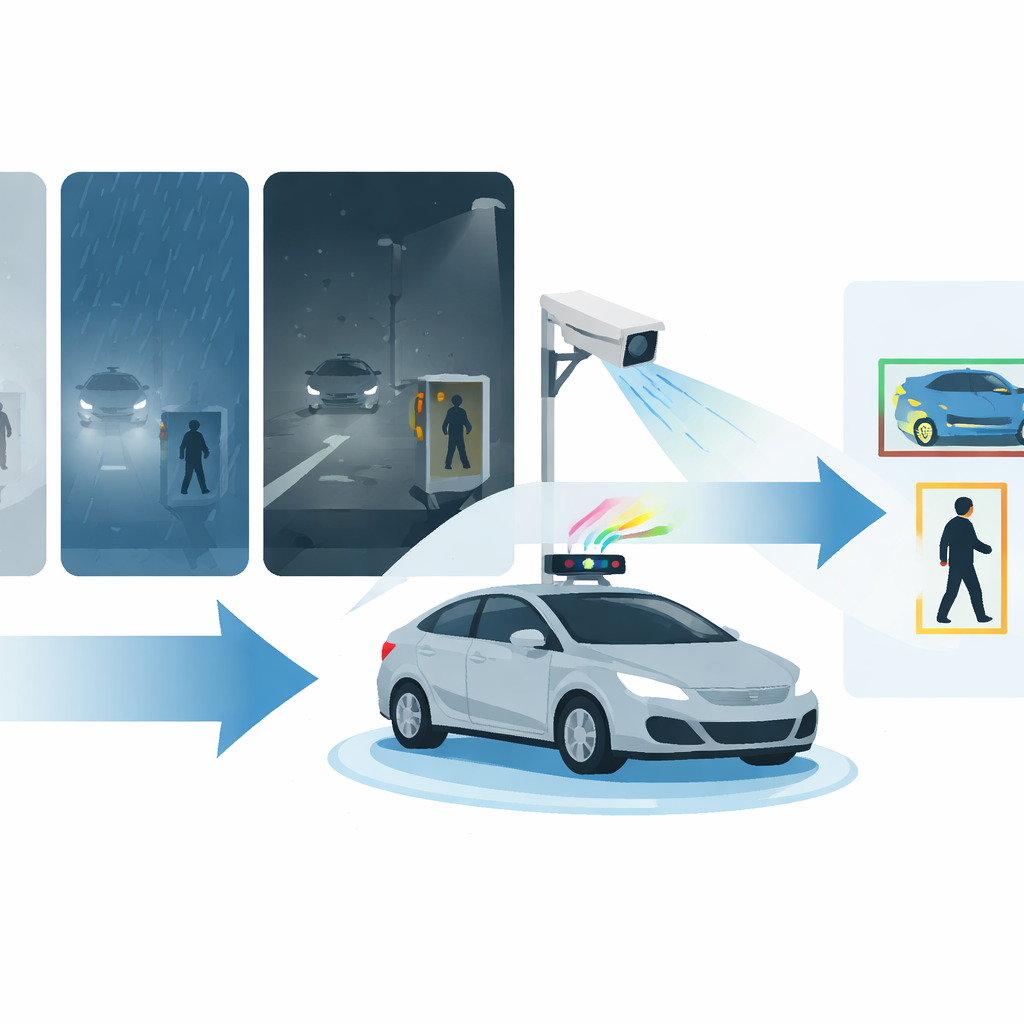
The challenge of driving in the real world
For years, researchers have improved automatic object detection using powerful deep‑learning models such as YOLO, which scan images and mark cars, buses, bikes, and people in real time. Most of these models, however, are trained and tuned under clear, daytime conditions. When visibility drops—at night, in fog, or during a downpour—objects become faint, blurred, or partially hidden. Small or far‑away road users are especially easy to miss. Existing approaches often specialize in a single type of bad weather, or they bolt together multiple heavy networks that are too slow and complex for real‑time driving and surveillance.
A smarter way to focus on what matters
MDAT‑YOLO starts from a compact version of a popular detector and redesigns its inner building blocks so that it can adapt to difficult scenes instead of treating every image in the same rigid way. The key idea is to let the model decide, on the fly, where to focus its attention in an image and how to process different kinds of visual patterns. Two new components drive this behavior. An optimized depthwise convolution layer reshapes how information flows between color channels, making the network lighter yet more expressive. A second module, called omni‑dimensional dynamic convolution, adjusts its filters not just across space, but also across different feature channels and alternative filter sets. Together, they allow the model to respond differently to thick fog, harsh glare, or noisy rain streaks without slowing down.
Adding global context without slowing down
Beyond sharpening local details, the authors give the model a better sense of the whole scene. They introduce a lightweight transformer block—commonly used in language models—that learns long‑range relationships in the image. Instead of applying a large, expensive transformer everywhere, they weave a slimmed‑down version into key stages of the network. This helps the detector understand that a faint outline in the distance is likely a car on the road, not random noise, and that small clusters of pixels may belong to a pedestrian partly hidden by mist or rain.
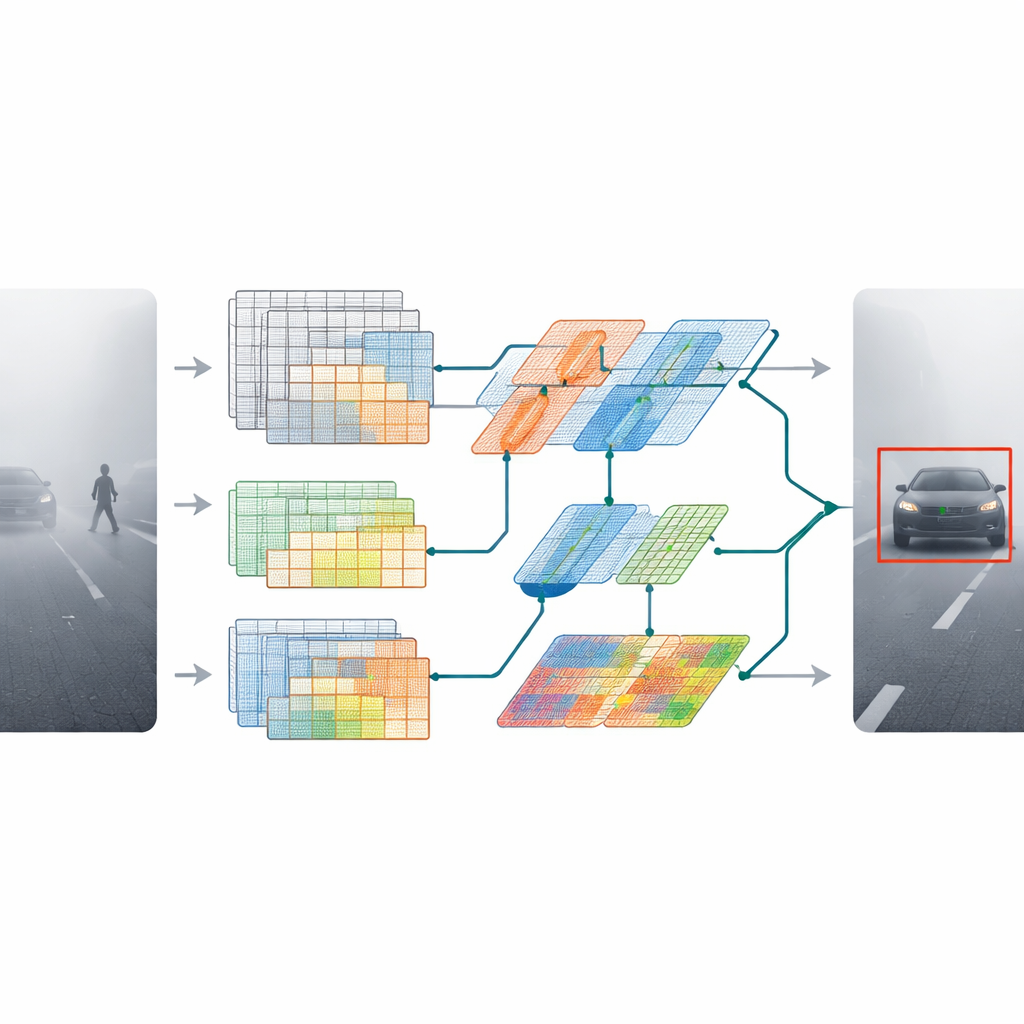
Putting the model to the test in tough weather
To judge whether these design changes truly help, the researchers tested MDAT‑YOLO on several demanding image collections. These include a real‑world fog, haze, and rain set; a low‑light night‑time set; a newly created foggy version of a well‑known benchmark; and a real rainy‑scene set. Across all of them, the new model detected cars, buses, motorbikes, bicycles, and people more accurately than many recent YOLO variants and other advanced methods. It was especially strong at finding vehicles in heavy fog and people in dark scenes. Just as important, the model kept up real‑time speeds, processing up to about 145 images per second on modern hardware—fast enough for use in moving vehicles and live traffic monitoring.
What this means for everyday safety
In plain terms, MDAT‑YOLO is a step toward cameras and onboard computers that keep working reliably when the weather turns bad. By combining efficient building blocks with flexible attention and global context, the system “looks harder” at dim, small, or partially hidden objects without becoming bulky or slow. While more tests on broader, fully real‑world data are still needed, the results suggest that future driver‑assistance systems, autonomous cars, and roadside cameras could miss fewer road users in fog, rain, and darkness—helping make streets safer even on the worst days.
Citation: Biswas, S., Kumar, J., Mitra, A. et al. Multi-dimensional attention transformer for vehicle and pedestrian detection in adverse weather. Sci Rep 16, 12624 (2026). https://doi.org/10.1038/s41598-026-40319-7
Keywords: autonomous driving, object detection, adverse weather, computer vision, traffic safety