Clear Sky Science · fr
Transformateur d'attention multidimensionnelle pour la détection de véhicules et de piétons par mauvais temps
Pourquoi voir à travers le mauvais temps est important
Les voitures modernes et les caméras urbaines apprennent à « voir » la route pour nous, repérant véhicules et piétons si rapidement qu'elles peuvent aider à éviter des accidents. Mais la pluie, le brouillard et l'obscurité perturbent encore beaucoup de ces systèmes, masquant des personnes et des voitures précisément quand la sécurité est la plus critique. Cet article présente MDAT‑YOLO, un nouveau modèle de vision par ordinateur conçu pour continuer à détecter rapidement et de manière fiable les usagers de la route, même dans un brouillard épais, une pluie battante ou en faible luminosité.
Le défi de conduire dans le monde réel
Depuis des années, les chercheurs améliorent la détection automatique d'objets avec des modèles profonds puissants comme YOLO, qui analysent les images et marquent en temps réel voitures, bus, vélos et personnes. La plupart de ces modèles, toutefois, sont entraînés et optimisés en conditions claires et diurnes. Quand la visibilité diminue — la nuit, dans le brouillard ou sous une forte averse — les objets deviennent pâles, flous ou partiellement cachés. Les usagers de la route petits ou éloignés sont particulièrement faciles à manquer. Les approches existantes se spécialisent souvent dans un seul type de mauvais temps, ou assemblent plusieurs réseaux lourds qui sont trop lents et complexes pour la conduite et la surveillance en temps réel.
Une façon plus intelligente de se concentrer sur l'essentiel
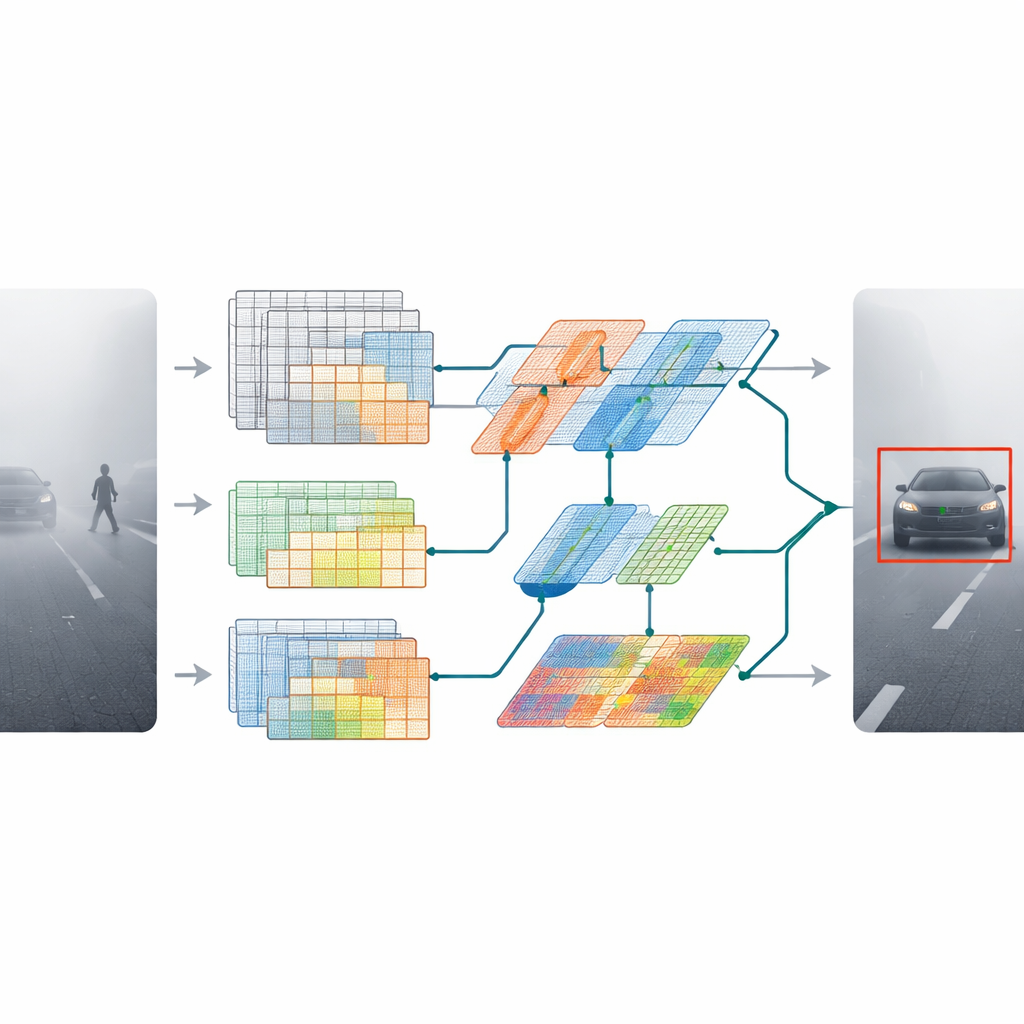
MDAT‑YOLO part d'une version compacte d'un détecteur populaire et repense ses blocs internes pour qu'il puisse s'adapter aux scènes difficiles au lieu de traiter chaque image de manière rigide et identique. L'idée clé est de laisser le modèle décider, à la volée, où concentrer son attention dans une image et comment traiter différents types de motifs visuels. Deux nouveaux composants pilotent ce comportement. Une couche de convolution depthwise optimisée remodèle la façon dont l'information circule entre les canaux de couleur, rendant le réseau plus léger tout en le rendant plus expressif. Un second module, appelé convolution dynamique omni‑dimensionnelle, ajuste ses filtres non seulement à travers l'espace, mais aussi à travers différents canaux de features et jeux de filtres alternatifs. Ensemble, ils permettent au modèle de réagir différemment au brouillard dense, à l'éblouissement intense ou aux éclaboussures de pluie sans ralentir.
Ajouter du contexte global sans ralentir
Au‑delà d'aiguiser les détails locaux, les auteurs donnent au modèle une meilleure compréhension de l'ensemble de la scène. Ils introduisent un bloc transformeur léger — couramment utilisé dans les modèles de langage — qui apprend les relations à longue portée dans l'image. Plutôt que d'appliquer un transformeur lourd et coûteux partout, ils intègrent une version affinée dans des étapes clés du réseau. Cela aide le détecteur à comprendre qu'une silhouette faible au loin est probablement une voiture sur la route, et que de petits groupements de pixels peuvent appartenir à un piéton partiellement caché par la brume ou la pluie.
Mettre le modèle à l'épreuve par mauvais temps
Pour juger si ces modifications de conception apportent réellement un bénéfice, les chercheurs ont testé MDAT‑YOLO sur plusieurs jeux d'images exigeants. Ceux‑ci incluent un ensemble réel de brouillard, de brume et de pluie ; un jeu de nuit en faible luminosité ; une version brumeuse nouvellement créée d'un benchmark bien connu ; et un ensemble de scènes pluvieuses réelles. Sur l'ensemble de ces tests, le nouveau modèle a détecté voitures, bus, motos, bicyclettes et personnes avec plus de précision que de nombreuses variantes récentes de YOLO et d'autres méthodes avancées. Il s'est montré particulièrement performant pour repérer les véhicules dans un brouillard épais et les personnes dans des scènes sombres. Autre point important : le modèle a conservé des vitesses en temps réel, traitant jusqu'à environ 145 images par seconde sur du matériel moderne — assez rapide pour une utilisation dans des véhicules en mouvement et la surveillance du trafic en direct.
Ce que cela signifie pour la sécurité quotidienne
Concrètement, MDAT‑YOLO est un pas vers des caméras et des ordinateurs embarqués qui restent fiables quand le temps se gâte. En combinant des blocs de construction efficaces avec une attention flexible et du contexte global, le système « regarde plus attentivement » les objets faibles, petits ou partiellement cachés sans devenir encombrant ou lent. Bien que des tests supplémentaires sur des données du monde réel plus larges soient encore nécessaires, les résultats suggèrent que les futurs systèmes d'assistance à la conduite, les véhicules autonomes et les caméras routières pourraient manquer moins d'usagers de la route dans le brouillard, la pluie et l'obscurité — contribuant à rendre les rues plus sûres même les jours les plus difficiles.
Citation: Biswas, S., Kumar, J., Mitra, A. et al. Multi-dimensional attention transformer for vehicle and pedestrian detection in adverse weather. Sci Rep 16, 12624 (2026). https://doi.org/10.1038/s41598-026-40319-7
Mots-clés: conduite autonome, détection d'objets, mauvaises conditions météorologiques, vision par ordinateur, sécurité routière