Clear Sky Science · ja
モデルとタスクを横断したタンパク質表現の不確かさを定量化する
タンパク質AIにおける信頼性が重要な理由
人工知能はタンパク質という目に見えない世界を覗く強力な顕微鏡になってきました。最新の「タンパク質言語モデル」は、アミノ酸配列だけからタンパク質の立体構造や振る舞いを推測できます。これらのモデルは新薬設計や病的変異の解明に既に役立っています。しかし隠れた問題があり、モデルが内部で作る表現を我々がどれだけ信頼してよいかを示す情報はほとんど提供されません。本稿はそのギャップに取り組み、単純だが重大な問いを投げかけます:モデルがタンパク質を数値の雲に変換するとき、その雲が実際の生物学を反映しているのか、それとも単なるノイズなのかをどう判断するか?
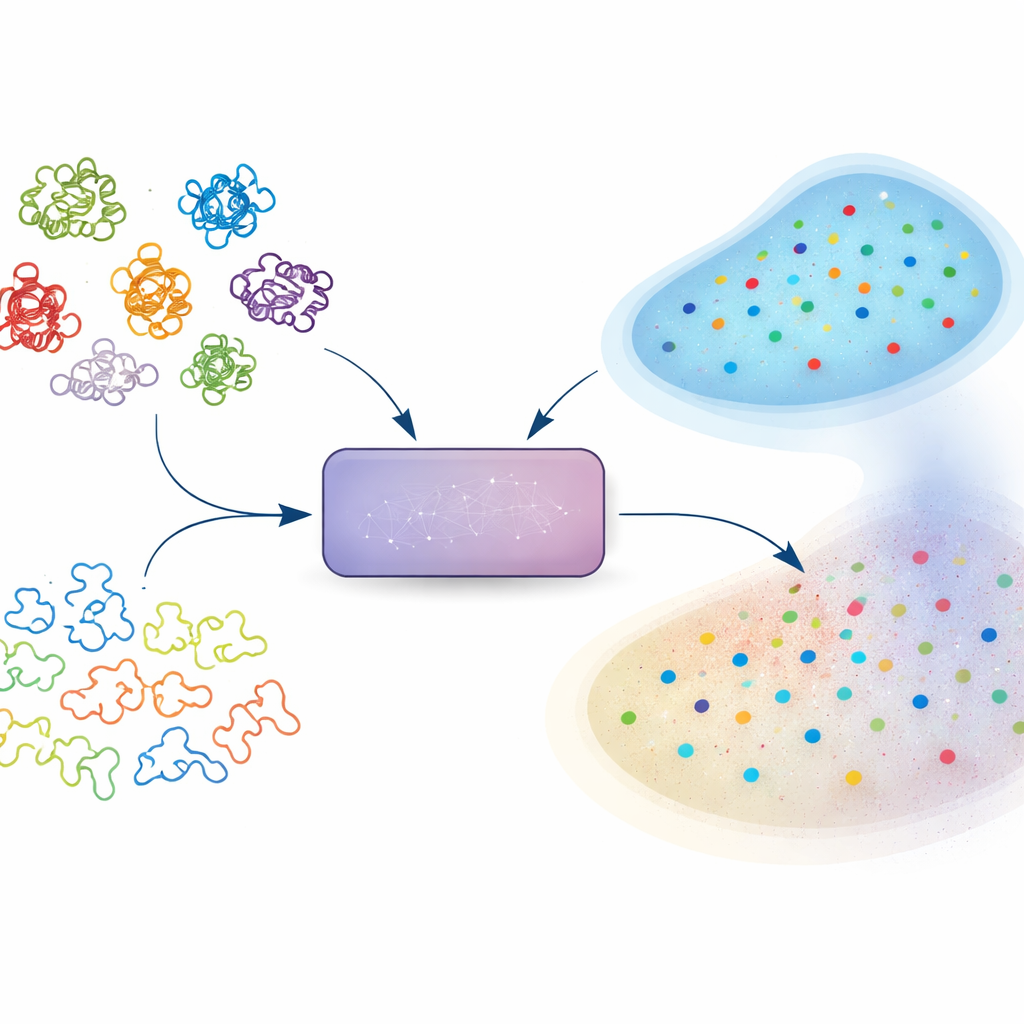
文章からタンパク質へ
言語モデルはもともと人間のテキスト処理のために開発され、単語同士の関係を学び文章の次を予測します。同じ考え方がタンパク質やDNAの配列を長い「語」として読むモデルにも応用されています。各タンパク質について、モデルは「埋め込み」を生成します—これは高次元空間上の点で、モデルがそのタンパク質について学んだことを要約するものです。これらの埋め込みは構造、機能、変異の影響など多くの下流タスクに入力されます。しかし、通常の予測スコアや信頼度指標とは異なり、埋め込みはそのまま受け取られがちです:モデルがベクトルを出力すれば、ユーザーは訓練でほとんど見ていないタンパク質領域でもそれを信用してしまいます。
モデルが推測しているときを見抜く
著者らは基礎モデルを改変せずに埋め込みの信頼性を推定する実用的な方法を提案します。キーとなる発想は、同じ基本的なアミノ酸組成を保ちながら生物学的に意味あるパターンを失わせた、意図的にスクランブルした配列群をモデルに与えることです。これらの合成配列は「ジャンクヤード(廃棄場)」として機能し、モデルにとって信号が存在しないときに生成される出力の参照になります。任意の実際のタンパク質について、この手法はモデルの内部空間で近傍にある点の中でどれだけがジャンクヤード由来かを調べます。近傍の多くがスクランブル配列なら、そのタンパク質の表現は十分に学習されていないかあいまいである可能性が高い。著者らはこのジャンクヤード近傍の割合をRandom Neighbor Score(RNS)と呼びます。
不確かさを実世界の性能に結びつける
RNSが生物学的に重要な何かを反映しているかを確かめるため、研究チームはESM-2やProtT5を含む最先端モデルを用いて大量のタンパク質構造と配列を解析しました。構造予測が正確だったタンパク質は低いRNSを示す傾向があり、つまりそれらの埋め込みはジャンクヤードから離れていました。これに対して構造予測が不十分なタンパク質は、実配列とスクランブル配列が重なり合う領域に存在していました。このパターンはモデルやタスクを通じて一貫して観察されました。残基間の接触予測や二次構造割り当てなどの応用的な問題に目を向けると、RNSが増加するにつれて精度が明確に低下しました。言い換えれば、埋め込みが不確か(RNSが高い)ほど、下流の予測は信頼できなくなるということです。
タンパク質空間の盲点
RNSはまた、モデルがタンパク質宇宙の異なる領域をどのように表現するかにおける系統的な盲点を明らかにしました。本質的に無秩序な領域—安定した立体構造を欠く柔軟な伸長領域—は、よく折り畳まれたドメインより一貫して高いRNSを示し、モデルがこうした扱いにくい配列で苦労していることを示しています。よく研究されたヒトプロテオームでさえ、かなりの割合のタンパク質がゼロでないRNSを持ち、人気のあるモデルで十分に捉えられていないことが示されました。驚くべきことに、大きなモデルが常に優れているわけではありません:構造重視の大規模モデルが、より小さくより汎用的なモデルよりも多くのヒトタンパク質について不確かである場合がありました。新たに発見されたメタゲノム由来のタンパク質や、現実的に見えるよう設計されたコンピュータ生成の「ハルシネート」タンパク質では、低いRNSが示され、パターンが一貫していればモデルが訓練データの外側にも自信を持って汎化できることを示唆しています。
より良いフィルタでより良い生物学的知見を
著者らは次に、RNSに基づくスクリーニングが臨床に関連するタスクにどのように影響するかを検証しました:ヒトタンパク質の一文字の置換(アミノ酸変化)が機能を損なったり病気を引き起こしたりする可能性を予測する場合です。埋め込みが信頼できる低RNSのタンパク質に解析を限定すると、モデルの性能は著しく改善し、有害変異と中立的な変異を強く区別できることが多くありました。高RNSのタンパク質では予測性能はコイントスに近づきました。これは、信頼できない埋め込みが下流ツールの最高精度を静かに制限してしまう、という見方を支持します。巧妙な訓練手法を用いても、元の埋め込みが不確かなら限界があるということです。
生物学でAIを使う際の意味
専門外の読者への要点は、AI由来のタンパク質表現がすべて同じように信頼できるわけではなく、その信頼性を定量化できるようになったということです。Random Neighbor Scoreは埋め込みに対する単純でモデル非依存の健康診断のように機能します:低いスコアは対象タンパク質が他の生物学的に意味のある配列の中に位置していることを示し、高いスコアはランダムな類似配列の廃棄場に近づいていることを示唆します。構造予測、機能注釈、病変候補の優先付けを行う前にRNSでタンパク質をフィルタリングまたは重み付けすることで、研究者はモデルが本当にデータを「理解」している領域に集中できます。ぼやけた顕微鏡を気づかずに使う科学者はいないのと同様に、この研究はすべてのタンパク質言語モデルに内部の生物学的視界の鮮明さを測る組み込み手段が備わるべきだと主張します。
引用: Prabakaran, R., Bromberg, Y. Quantifying uncertainty in protein representations across models and tasks. Nat Methods 23, 796–804 (2026). https://doi.org/10.1038/s41592-026-03028-7
キーワード: タンパク質言語モデル, 埋め込みの信頼性, 表現の不確実性, 変異効果予測, 本質的に無秩序なタンパク質