Clear Sky Science · fr
Optimisation métaheuristique de CNN profonds pour le diagnostic multiclasse du cancer du col de l'utérus et du lymphome
Des outils plus intelligents pour détecter le cancer tôt
Pour beaucoup, un diagnostic de cancer arrive encore trop tard, quand le traitement est plus difficile et les chances de survie diminuent. Les médecins utilisent déjà des microscopes et des ordinateurs pour examiner les prélèvements tissulaires, mais apprendre aux machines à distinguer des cancers au profil visuel similaire s'avère surprenamment difficile. Cette étude explore comment rendre l'intelligence artificielle bien plus fiable pour repérer deux maladies graves, le cancer du col de l'utérus et le lymphome, en laissant des stratégies de recherche inspirées par la nature affiner automatiquement un puissant réseau d'analyse d'images.
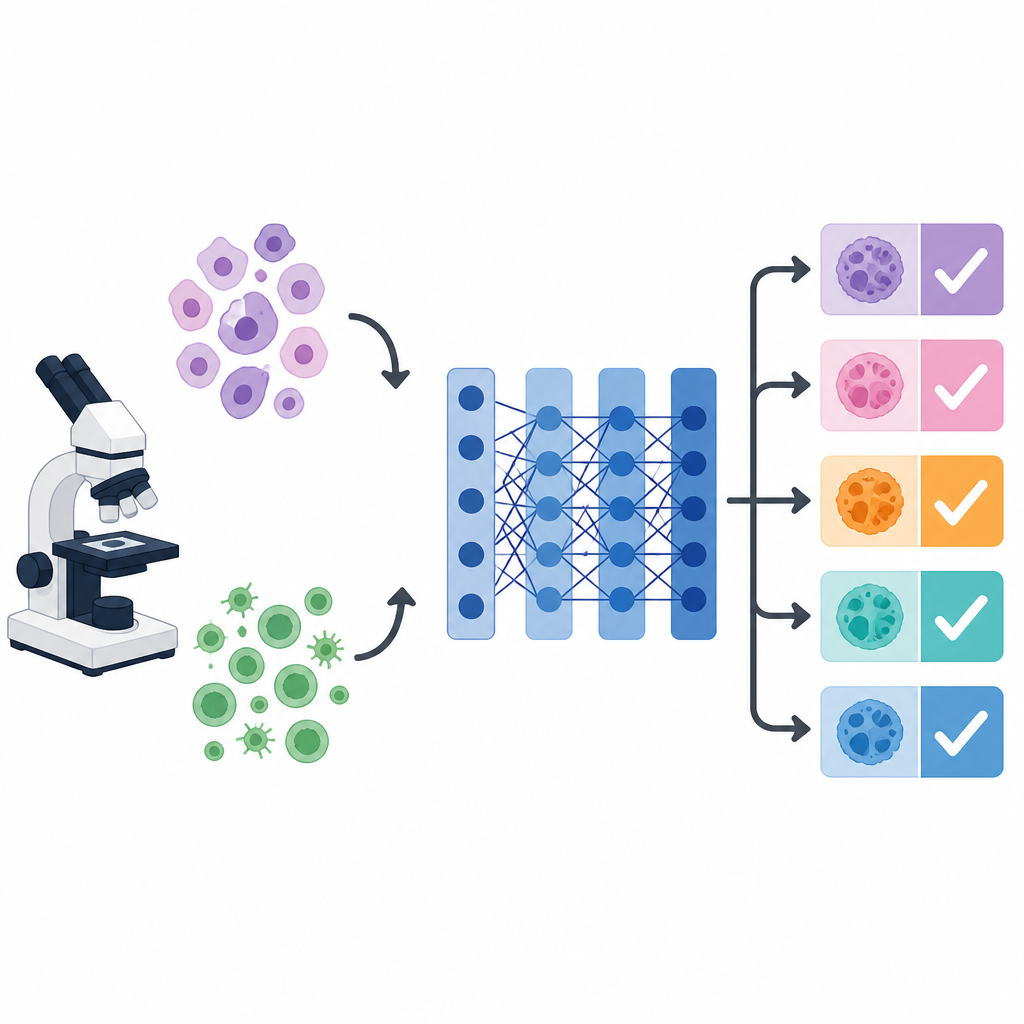
Pourquoi les images de cancer embrouillent les ordinateurs
Au microscope, des cellules de cancers différents peuvent se ressembler, tandis que des cellules d'un même cancer peuvent varier considérablement en forme, couleur et texture. Ce désordre visuel rend difficile la délivrance de diagnostics cohérents pour les humains comme pour les machines. Les systèmes d'apprentissage profond, en particulier un réseau d'images populaire appelé VGG 16, peuvent apprendre à détecter des motifs visuels utiles. Toutefois, leurs performances dépendent fortement de nombreux paramètres cachés, tels que le taux d'apprentissage, la taille des lots et la force de la régularisation. Ces réglages, appelés hyperparamètres, sont généralement choisis manuellement ou laissés par défaut, ce qui peut freiner la précision, surtout lorsque l'objectif est de distinguer plusieurs types de cancer simultanément.
Profiter de la puissance des grands jeux de données sans en avoir besoin
Les jeux de données d'images médicales sont souvent petits, car des échantillons annotés de haute qualité sont difficiles et coûteux à obtenir. Pour contourner cette limite, les chercheurs s'appuient sur l'apprentissage par transfert. Ils partent d'un réseau VGG 16 entraîné sur une vaste collection d'images générales et réutilisent ses premières couches comme extracteur de caractéristiques pour les images cellulaires. Ils ajoutent ensuite des couches personnalisées adaptées à la nouvelle tâche. L'équipe travaille avec deux collections publiques : un ensemble pour le cancer du col contenant cinq catégories cellulaires et un ensemble pour le lymphome avec trois sous-types. Chaque jeu de données initial comptait moins d'un millier d'images, aussi les auteurs les ont-ils étendus par une augmentation soignée, telle que de petites rotations, translations, zooms, variations de luminosité et retournements, pour créer des dizaines de milliers d'exemples d'entraînement variés.
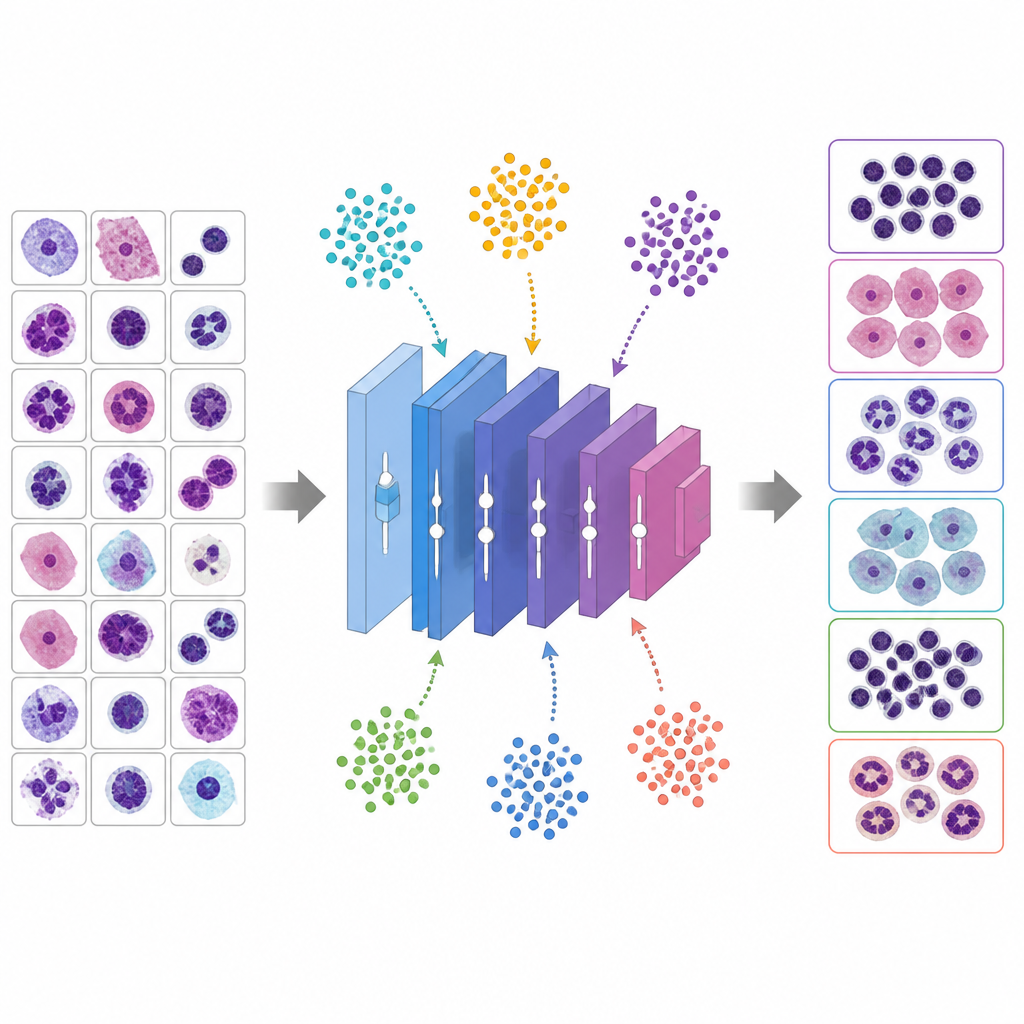
Laisser des animaux virtuels régler les boutons
Plutôt que de deviner de bons hyperparamètres, l'étude utilise six algorithmes métaheuristiques inspirés du comportement animal et de l'évolution pour rechercher les meilleurs réglages. Dans ces méthodes, chaque solution candidate agit comme une créature explorant un paysage de possibilités. L'algorithme d'optimisation par les baleines (Whale Optimization Algorithm) imite la spirale des baleines à bosse autour de leurs proies, le Grey Wolf Optimizer modélise des loups encerclant et traquant une cible, le Particle Swarm Optimization traite les solutions comme des oiseaux en vol, l'algorithme génétique recombine et mute les solutions comme des gènes, l'Ant Colony Optimization suit des traces de phéromones virtuelles, et une variante modifiée de PSO vise à éviter un piégeage prématuré. Chaque candidat définit une recette complète d'entraînement pour VGG 16 ; le réseau est entraîné brièvement, sa précision de validation est mesurée, puis la métaheuristique ajuste sa population pour favoriser les meilleures recettes sur plusieurs itérations.
Du réglage des recettes au polissage fin du réseau
Le cadre fonctionne en deux phases. D'abord, le VGG 16 préentraîné est utilisé comme extracteur de caractéristiques figé pendant que les algorithmes recherchent de solides jeux d'hyperparamètres. Ensuite, une fois le meilleur ensemble trouvé, les couches supérieures de VGG 16 sont débloquées et affinées sur les données cancéreuses en utilisant ces réglages optimisés, permettant au réseau d'adapter ses filtres internes aux motifs tissulaires spécifiques. Malgré des budgets de recherche très limités — seulement cinq agents et trois itérations — et un nombre modeste d'époques d'entraînement, cette stratégie en deux étapes a produit des gains remarquables. Sur le jeu de données de lymphome, par exemple, un VGG 16 de référence sans optimisation atteignait environ 83 % de précision, tandis que les modèles optimisés montaient dans les hauts 90 %. Des sauts similaires ont été observés pour le cancer du col, où les systèmes ajustés ont dépassé 99 % de précision même avec seulement cinq époques d'entraînement.
Quelle stratégie a le mieux fonctionné et pourquoi cela compte
Sur les deux types de cancer et dans des répétitions, l'algorithme d'optimisation par les baleines s'est distingué. Associé au VGG 16 préentraîné, il a atteint des scores parfaits sur les jeux de test pour la précision, la précision positive, le rappel et la spécificité, et il a convergé de manière fiable en quelques étapes seulement. D'autres algorithmes, comme l'Ant Colony Optimization et le Particle Swarm Optimization, ont montré leur efficacité surtout une fois le réglage fin des couches profondes activé, s'approchant eux aussi ou dépassant 99 % de précision. Des tests statistiques ont confirmé que les gains obtenus par le réglage basé sur les baleines par rapport aux autres méthodes n'étaient pas dus au hasard. Bien que de tels résultats quasi parfaits doivent encore être validés sur des jeux de données plus larges et plus variés, l'étude montre que des stratégies de recherche soigneusement choisies peuvent libérer bien plus de performance des réseaux existants que les paramètres par défaut.
Ce que cela signifie pour les soins futurs contre le cancer
Pour les non-spécialistes, la principale conclusion est que l'étude propose une manière plus intelligente d'ajuster un système d'apprentissage profond existant afin qu'il puisse séparer plusieurs cancers visuellement similaires avec une très grande fiabilité, en utilisant des données d'entraînement limitées et des ressources informatiques raisonnables. Plutôt que de remplacer les médecins, de tels systèmes pourraient servir d'assistants cohérents, signalant des lames suspectes et aidant à réduire les diagnostics manqués ou erronés. Les auteurs notent que des jeux de données plus vastes et diversifiés, des architectures de réseau plus légères et des outils expliquant ce que le modèle voit seront nécessaires avant un déploiement en clinique. Néanmoins, ce travail suggère que laisser des baleines, des loups et des essaims virtuels régler nos réseaux détecteurs de cancer peut rendre le diagnostic automatisé plus précis, plus rapide et plus digne de confiance.
Citation: Abdelhay, E.H., Elgamily, K.M. & Badr, W.O.EF. Metaheuristic optimization of deep CNNs for multi-class diagnosis of cervical cancer and lymphoma. Sci Rep 16, 15110 (2026). https://doi.org/10.1038/s41598-026-51619-3
Mots-clés: imagerie du cancer du col, classification du lymphome, diagnostic par apprentissage profond, optimisation des hyperparamètres, algorithmes métaheuristiques