Clear Sky Science · de
YOLO-MFD: ein Multi-Skalen-Feature- und dynamisches-Head-Framework zur Erkennung vorgefertigter Ufer-Unterwasserobjekte
Klügere Augen unter städtischen Ufern
Wenn Städte mehr Mauern, Stege und vorgefertigte Uferbefestigungen entlang von Flüssen und Seen bauen, liegt ein großer Teil der kritischen Infrastruktur unter Wasser verborgen. Zu prüfen, ob diese Blöcke stabil sind, Risse aufweisen oder mit Trümmern verunreinigt sind, ist schwierig — besonders in trübem, flachem Wasser mit schlechter Sicht. Dieses Paper stellt YOLO-MFD vor, ein neues Computer-Vision-System, das Unterwasserrobotern hilft, kleine, schwache Objekte entlang von Ufern zuverlässiger und schneller zu erkennen, selbst wenn das Wasser trüb ist und die Szene überfüllt wirkt.
Warum Unterwasserbilder so schwer zu lesen sind
Flüsse, Seen und städtische Ufergewässer sind selten glasklar. Licht wird absorbiert und gestreut, Farben verschieben sich ins Grüne oder Blaue, und suspendierte Partikel verwischen Kanten. Kleine Lebewesen, Meeresmüll oder Schäden an vorgefertigten Uferblöcken können winzig, kontrastarm und dicht beieinander liegen. Standard-Objekterkennungssysteme, die ursprünglich für klare Straßenszenen entwickelt wurden, übersehen diese Ziele oder verwechseln sie mit Hintergrundstörungen. Gleichzeitig haben Inspektionsroboter und eingebettete Geräte in Ufernähe begrenzte Rechenleistung, sodass eine Lösung sowohl genau als auch effizient sein muss.
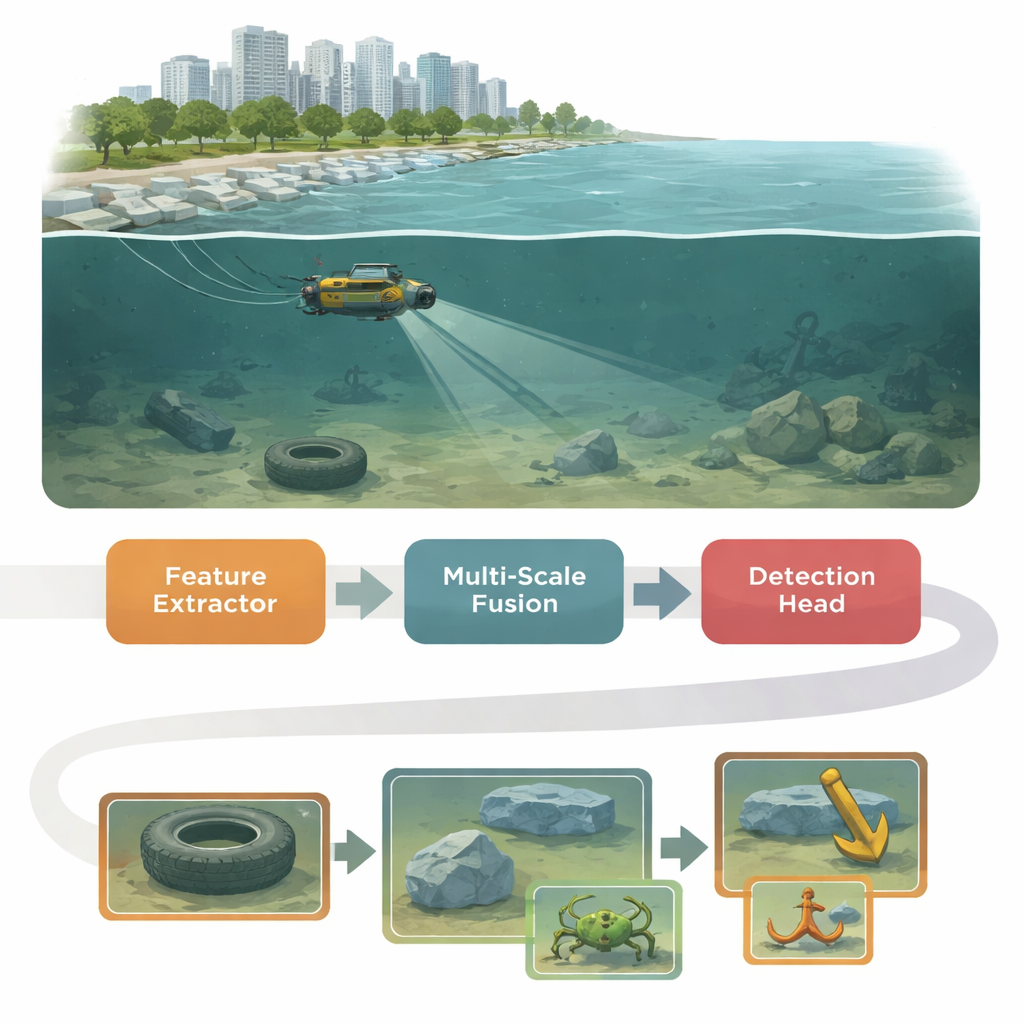
Ein dreiteiliges Gehirn für trübes Wasser
YOLO-MFD baut auf der populären YOLO-Familie von Echtzeit-Detektoren auf, formt ihr internes „Gehirn“ aber in drei koordinierten Stufen um. Zuerst lernt ein neuer Backbone namens CUMANet (Cross-scale Unified Multi-scale Attention Network), Merkmale aus Bildern zu extrahieren und gleichzeitig auf den weiten Kontext zu achten. Er verwendet parallele Zweige und eine spezialisierte Faltung, die sich während des Trainings wie ein Multi-Branch-Modul verhält, sich aber für den Einsatz zu einer einzelnen, effizienten Operation vereinfacht. Das hilft dem Netzwerk, über lokalen Rausch zu blicken, langreichweitige Hinweise zu erfassen und wichtige Details zu bewahren, die durch Trübung und Farbverzerrung sonst verwischt würden.
Kleine Hinweise in verschiedenen Skalen verfolgen
Die zweite Stufe, Adaptive Feature Modulation (AFM), adressiert eine häufige Schwäche von Vision-Systemen: Beim Zusammenführen von Informationen aus groben und feinen Auflösungen gehen oft kleinskalige Details verloren. AFM bringt zwei Feature-Maps zusammen, indem es zuerst ihre Größen und Kanäle anpasst und dann sanfte, unabhängige Gates für jeden Zweig berechnet. Anstatt eine Skala zu dominant werden zu lassen, erlaubt AFM beiden, beizutragen, wann immer sie nützliche Signale enthalten, und fügt eine Residualverbindung hinzu, um schwache, aber wichtige Muster nicht zu verlieren. Diese ausgewogene Multi-Skalen-Fusion ist besonders hilfreich, um kleine Seegurken, Seesterne oder Risse im Beton zu erkennen, die kaum vom Hintergrund abstehen.
Ein flexiblerer Entscheidungsgeber am Ende
Die finale Stufe, DPNDyHead (Dual-Pooling and Normalized Dynamic Head), verfeinert Merkmale kurz bevor das System entscheidet, was und wo Objekte sind. Sie übernimmt die Idee deformierbarer Faltungen, die ihre Abtastpunkte verschieben, um besser verschwommenen oder verzerrten Formen unter Wasser zu folgen. Um mit Objekten sehr unterschiedlicher Größe umzugehen, verwendet DPNDyHead sowohl Average- als auch Max-Pooling über Skalen und verbindet so globalen Kontext mit scharfen lokalen Reaktionen wie Kanten oder Texturen. Ein Normalisierungsschritt stabilisiert die Feature-Statistiken, bevor aufgabenspezifische Aktivierungen erzeugt werden, und verringert so die Auswirkungen von Farbverschiebungen und ungleichmäßiger Beleuchtung. Diese Tricks helfen zusammen, die Zuversicht in die Klassifizierung (was das Objekt ist) mit der Präzision der Lokalisation (wo es ist) besser in Einklang zu bringen.

Wie gut funktioniert es in der Praxis?
Die Autoren testeten YOLO-MFD auf zwei öffentlichen Unterwasser-Datensätzen aus Aquakultur- und Offshore-Farmen, die viele kleine, dichte Ziele und starke Bildverschlechterungen enthalten. Sowohl auf DUO als auch auf UDD übertraf das neue Framework klassische Zwei-Stufen-Detektoren, anchorfreie Methoden, moderne Transformer-basierte Modelle und neuere YOLO-Varianten. Es erzielte höhere mean Average Precision und Recall — das heißt, es fand mehr echte Objekte und machte weniger Fehler — und das bei nur wenigen Millionen Parametern und moderatem Rechenaufwand. Detaillierte Experimente zeigten, dass jede der drei Module (CUMANet, AFM und DPNDyHead) messbare Verbesserungen beigetragen hat und ihre Kombination das beste Gesamtverhältnis von Genauigkeit, Robustheit und Geschwindigkeit lieferte.
Klarere Einsichten für sicherere Ufer
Praktisch bietet diese Arbeit Unterwasserrobotern und Überwachungssystemen eine schärfere, zuverlässigere Sicht darauf, was entlang städtischer Ufer und technischer Flussbefestigungen liegt. Indem ein Objektdetektor entwickelt wurde, der explizit Trübungsbedingungen, Skalenungleichgewicht und fehlangepasste Vorhersagen entgegenwirkt, liefern die Autoren ein Werkzeug, das den Zustand von Infrastruktur besser verfolgen, ökologische Erhebungen unterstützen und die intelligente Verwaltung vorgefertigter Uferstrukturen leiten kann. Während zukünftige Arbeiten breitere Umgebungen und noch leichtere Modellvarianten untersuchen, könnten Methoden wie YOLO-MFD ein zentraler Bestandteil routinemäßiger Unterwasserinspektionen werden und so Küstenstädte und Binnenwasserstraßen sicherer und besser instand gehalten helfen.
Zitation: Gang, Y., Li, T., Li, S. et al. YOLO-MFD: a multi-scale feature and dynamic head framework for prefabricated shoreline underwater object detection. Sci Rep 16, 10971 (2026). https://doi.org/10.1038/s41598-026-45591-1
Schlüsselwörter: Erkennung von Unterwasserobjekten, Uferinfrastruktur, Computer Vision, autonome Unterwasserfahrzeuge, Deep Learning