Clear Sky Science · zh
采用人类发育视觉饮食可获得稳健且基于形状的人工智能视觉
为什么教会计算机像孩子一样“看”很重要
现代计算机视觉可以为你的照片加标签并为自动驾驶提供指导,但它看待世界的方式仍与我们大不相同。人类自然而然把握物体的整体形状,并能应对模糊、噪声和杂乱的场景,而许多人工智能系统则依赖细微的纹理,一旦图像被扭曲便容易崩溃。本文探讨了一个新思路:与其单纯把视觉模型做得更大,不如像抚养人类孩子一样逐步“培养”它们,随着时间推移逐渐改善它们所见的内容。

计算机与人类目前视觉的差异
大多数流行的视觉系统从一开始就用清晰、高对比度、全彩的图像进行训练。因此,它们倾向于高度依赖表面细节,例如皮毛花纹或砖块纹理。在那些刻意将物体轮廓与表面图案相互冲突的测试中,人类几乎总是依据轮廓作出选择,而标准网络通常遵循纹理。这些模型也难以在繁杂场景中识别被隐藏的简单形状,并且在模糊、噪声或人眼察觉不到的微小数字修改下性能可能崩溃。所有这些问题都指向人工视觉与人类视觉之间的基本不匹配。
借鉴人类的视觉童年
人类婴儿并非一开始就拥有清晰的视力。他们的世界最初是模糊的、低对比的、颜色信息有限,并且只在许多年中逐步变得清晰和鲜明。研究人员汇总了数十年的研究,描绘了从出生到约25岁期间视觉三方面的成熟:清晰度、对比敏感性和色彩敏感性。他们将这些测量结果转化为一种图像处理“课程”,称为发育性视觉饮食。在训练过程中,输入网络的图像最初被强烈模糊、低对比并接近灰度,然后逐步变得更清晰、对比更强并完全着色,模拟人类视觉的成长过程。
从追随纹理到聚焦形状的视觉
用这种发育性视觉饮食训练的深度网络与通常的高质量训练进行了比较。在多种模型架构和图像集合上,这种新方法显著增强了对形状的偏好,达到了人类观察者的范围,同时在标准识别准确率上几乎没有损失。研究者在检查模型依赖的图像区域时发现,经过发育式训练的系统关注的是整体目标区域,而标准模型更多地注视于小的纹理块或背景区域。进一步测试表明,对比度的逐步提高,比单独的模糊或色彩变化更关键,推动网络从零散的局部细节转向使用广泛的目标结构。
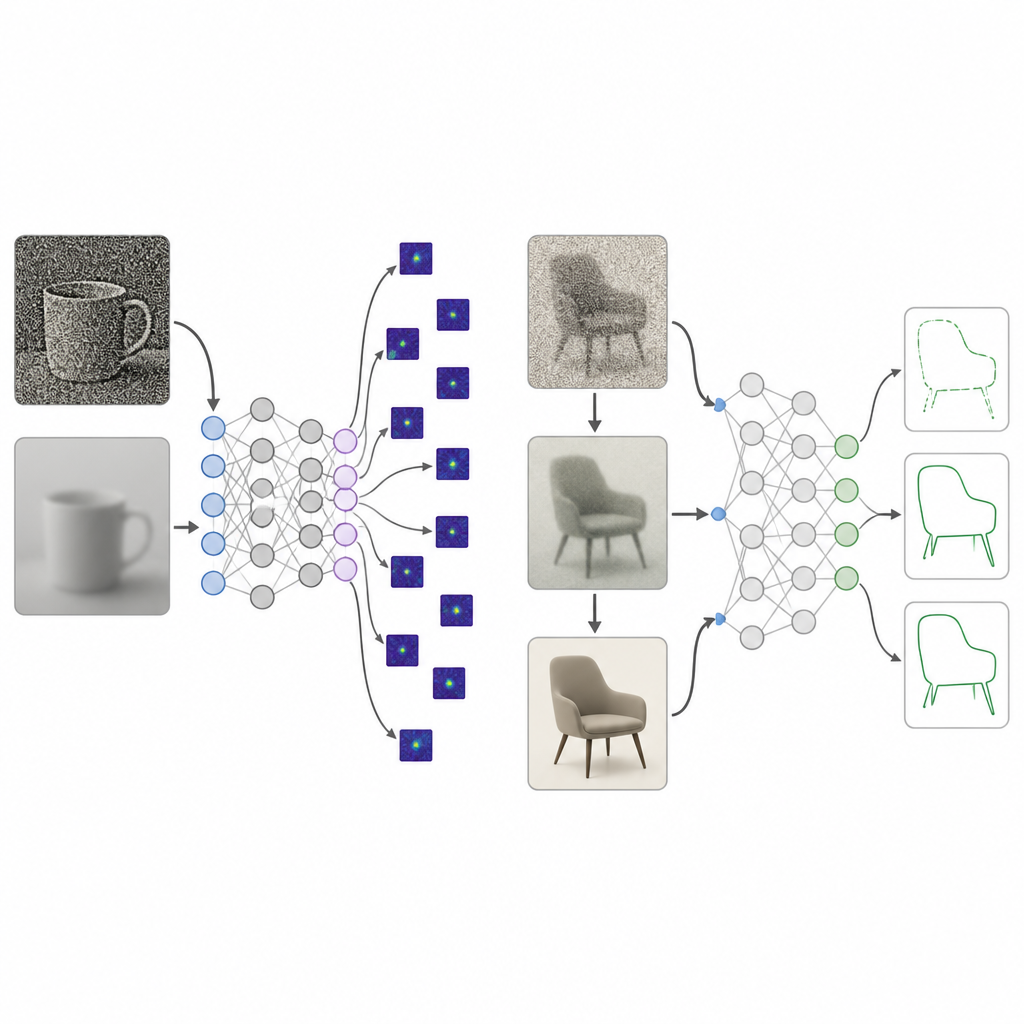
识别隐藏形状与处理混乱图像
团队接着用那些将熟悉形状(如自行车或海豚)巧妙嵌入复杂场景的图片来挑战模型。人类可以轻松发现这些轮廓,但大多数现有系统,包括大型视觉-语言模型,主要对场景的背景作出反应。接受发育性视觉饮食训练的网络在回忆隐藏形状时表现得好得多,并且不容易被场景所分散。当图像受到模糊、噪声、光线不良或类似雨雪的天气效应破坏时,它们也表现得更为稳健,常常与人类的趋势相匹配。即便面对对许多模型有效的敌意攻击——通过微小的数字修改进行欺骗——发育式训练的系统仍显著优于标准或敌意训练的对照模型。
这对更安全、更类人的人工智能意味着什么
通过给予人工智能一种与我们相呼应的视觉童年,这项工作表明训练方式的重要性可以与模型规模同等关键。一种简单且受生物学启发的课程把网络从脆弱的纹理伎俩中拉出,转向对形状的稳健利用,改善了在杂乱中识别抽象形式的能力,并增强了对自然扭曲和恶意攻击的抵抗力。对于非专业读者,核心信息是:从“较差”的视觉开始并让其成熟,实际上可以帮助机器学习到更稳固、更类人的观察方式,为实现更安全的视觉人工智能提供了一条更节约资源的路径。
引用: Lu, Z., Thorat, S., Cichy, R.M. et al. Adopting a human developmental visual diet yields robust and shape-based AI vision. Nat Mach Intell 8, 735–748 (2026). https://doi.org/10.1038/s42256-026-01228-6
关键词: 人工智能视觉, 视觉发育, 形状偏好, 鲁棒感知, 深度学习