Clear Sky Science · es
Adoptar una dieta visual de desarrollo humano produce visión artificial robusta y basada en la forma
Por qué importa enseñar a los ordenadores a ver como los niños
La visión por ordenador moderna puede etiquetar tus fotos y guiar coches autónomos, pero aún ve el mundo de forma muy distinta a la nuestra. Donde las personas comprenden naturalmente la forma global de los objetos y afrontan el desenfoque, el ruido y el desorden, muchos sistemas de inteligencia artificial se fijan en texturas finas y se desmoronan cuando las imágenes están distorsionadas. Este artículo explora una idea novedosa: en lugar de limitarse a hacer los modelos de visión más grandes, ¿y si los criáramos más como niños humanos, mejorando gradualmente lo que ven con el tiempo?

Cómo ven actualmente de forma diferente los ordenadores y las personas
La mayoría de los sistemas de visión populares se entrenan desde el principio con imágenes nítidas, de alto contraste y a todo color. Como resultado, tienden a depender en gran medida de detalles superficiales como patrones de pelaje o texturas de ladrillo. En pruebas cuidadosamente diseñadas donde el contorno de un objeto y su patrón de superficie entran en conflicto, los humanos casi siempre eligen según el contorno, mientras que las redes estándar suelen seguir la textura. Estos modelos también tienen dificultades para detectar formas simples escondidas en escenas ocupadas, y su rendimiento puede colapsar ante el desenfoque, el ruido o pequeños ajustes digitales que nos son invisibles. Todos estos problemas señalan un desajuste básico entre la visión artificial y la humana.
Tomando prestada la infancia visual de los humanos
Los bebés humanos no empiezan la vida con una vista cristalina. Su mundo es inicialmente borroso, de bajo contraste y pobre en color, y solo se vuelve nítido y vívido lentamente a lo largo de muchos años. Los investigadores reunieron décadas de estudios sobre cómo maduran tres aspectos de la visión desde el nacimiento hasta aproximadamente los 25 años: agudeza, sensibilidad al contraste y sensibilidad al color. Convirtieron estas medidas en un "currículum" de procesamiento de imágenes al que llaman dieta visual de desarrollo. Durante el entrenamiento, las imágenes que se alimentan a una red están primero muy desenfocadas, de bajo contraste y casi en gris; paso a paso se vuelven más nítidas, ricas en contraste y totalmente coloreadas, reflejando el crecimiento visual humano.
De seguir texturas a centrarse en la forma
Redes profundas entrenadas con esta dieta visual de desarrollo se compararon con el entrenamiento habitual con imágenes de alta calidad. A través de varios diseños de modelos y colecciones de imágenes, el nuevo enfoque produjo una preferencia por la forma mucho más fuerte, alcanzando el rango observado en observadores humanos sin perder casi nada en la precisión de reconocimiento estándar. Cuando los investigadores examinaron en qué partes de una imagen se basaban los modelos, los sistemas entrenados con el desarrollo se centraban en regiones de objeto completas, mientras que los modelos estándar se fijaban en pequeños parches de textura o en áreas de fondo. Pruebas adicionales mostraron que la mejora gradual del contraste, más que el desenfoque o el color por sí solos, desempeñó un papel clave para empujar a las redes hacia el uso de la estructura amplia del objeto en lugar de detalles locales dispersos.
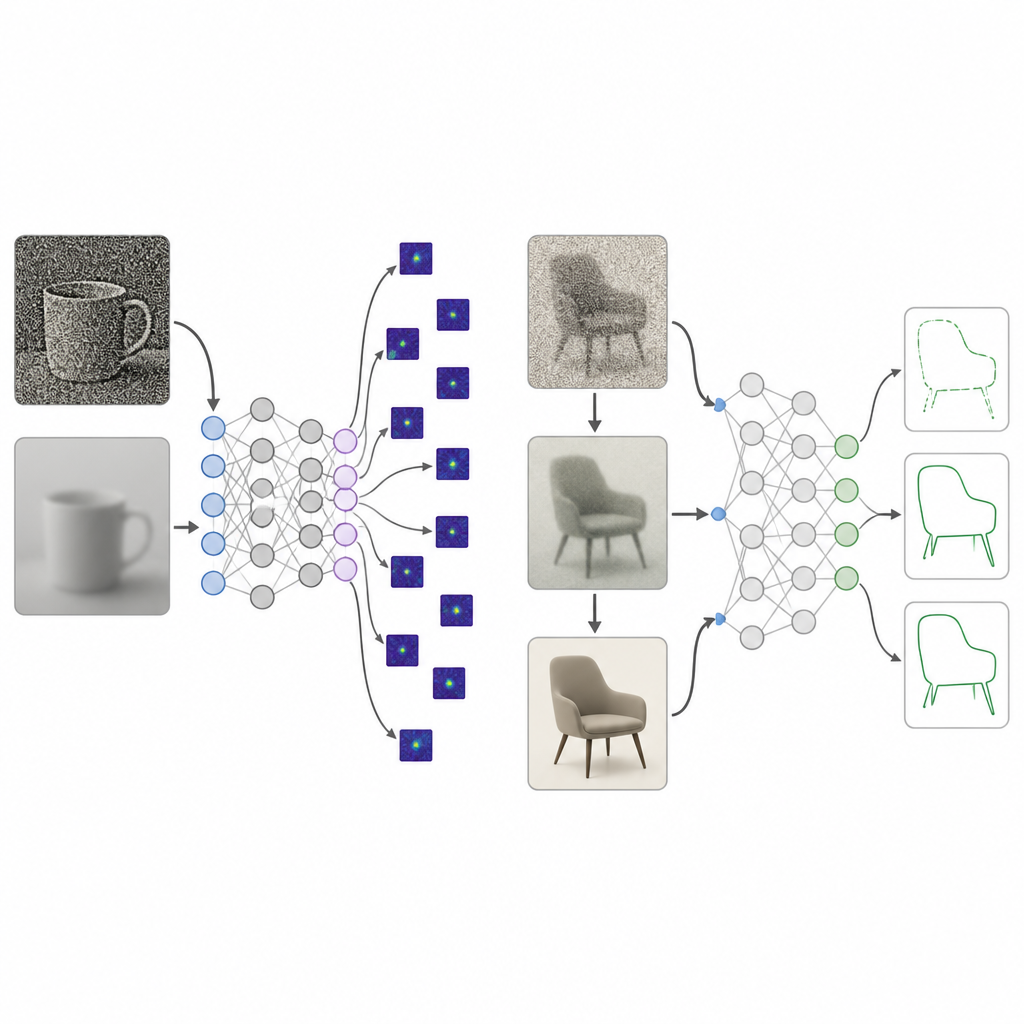
Reconocer formas ocultas y manejar imágenes desordenadas
El equipo desafió luego a los modelos con imágenes donde formas familiares como una bicicleta o un delfín estaban sutilmente entretejidas en escenas complejas. Las personas detectan fácilmente esos contornos, pero la mayoría de los sistemas existentes, incluidos grandes modelos de visión y lenguaje, responden principalmente al fondo de la escena. Las redes criadas con la dieta visual de desarrollo fueron mucho mejores recordando las formas ocultas y menos distraídas por la escena. También se mantuvieron con mucha más elegancia cuando las imágenes se corrompían por desenfoque, ruido, mala iluminación o efectos tipo meteorológicos como lluvia y nieve, igualando a menudo las tendencias humanas. Incluso frente a ataques adversarios, donde pequeños cambios digitales engañan a muchos modelos, los sistemas entrenados con el enfoque de desarrollo siguieron siendo sustancialmente más precisos que sus homólogos estándar o entrenados adversarialmente.
Qué significa esto para una IA más segura y parecida a la humana
Al alimentar a la IA con una infancia visual que hace eco de la nuestra, este trabajo muestra que cómo se entrena un modelo puede importar tanto como su tamaño. Un currículum simple, inspirado en la biología, alejó a las redes de trucos frágiles basados en texturas y las orientó hacia el uso robusto de la forma, mejoró el reconocimiento de formas abstractas en el desorden y aumentó la resistencia tanto a distorsiones naturales como a ataques hostiles. Para los no especialistas, el mensaje clave es que comenzar con una visión “pobre” y dejarla madurar puede ayudar a las máquinas a aprender maneras de ver más sólidas y humanas, ofreciendo una vía más eficiente en recursos hacia una visión artificial más segura.
Cita: Lu, Z., Thorat, S., Cichy, R.M. et al. Adopting a human developmental visual diet yields robust and shape-based AI vision. Nat Mach Intell 8, 735–748 (2026). https://doi.org/10.1038/s42256-026-01228-6
Palabras clave: visión por IA, desarrollo visual, sesgo hacia la forma, percepción robusta, aprendizaje profundo