Clear Sky Science · it
Adottare una dieta visiva di sviluppo umana genera visione AI robusta e basata sulla forma
Perché insegnare ai computer a vedere come i bambini è importante
La visione artificiale moderna può etichettare le tue foto e guidare le auto a guida autonoma, eppure vede ancora il mondo in modo molto diverso da noi. Dove le persone afferrano naturalmente la forma complessiva degli oggetti e affrontano sfocature, rumore e ingombro, molti sistemi di intelligenza artificiale si aggrappano a texture fini e collassano quando le immagini sono distorte. Questo articolo esplora un’idea nuova: invece di limitarsi a rendere i modelli visivi più grandi, e se li allevassimo più come bambini umani, migliorando gradualmente ciò che vedono nel tempo?

Come computer e persone vedono attualmente in modo diverso
La maggior parte dei sistemi di visione più diffusi viene addestrata fin dall’inizio su immagini nitide, ad alto contrasto e a colori vividi. Di conseguenza, tende a dipendere molto dai dettagli superficiali come i motivi del pelo o la trama dei mattoni. In test accuratamente progettati in cui il contorno di un oggetto e il suo motivo superficiale sono messi in conflitto, gli esseri umani quasi sempre scelgono in base al contorno, mentre le reti standard seguono di solito la texture. Questi modelli fanno anche fatica a scorgere forme semplici nascoste in scene affollate e le loro prestazioni possono crollare sotto sfocature, rumore o piccole modifiche digitali invisibili a noi. Tutti questi problemi indicano una dissonanza di fondo tra la visione artificiale e quella umana.
Prendere in prestito l’infanzia visiva degli esseri umani
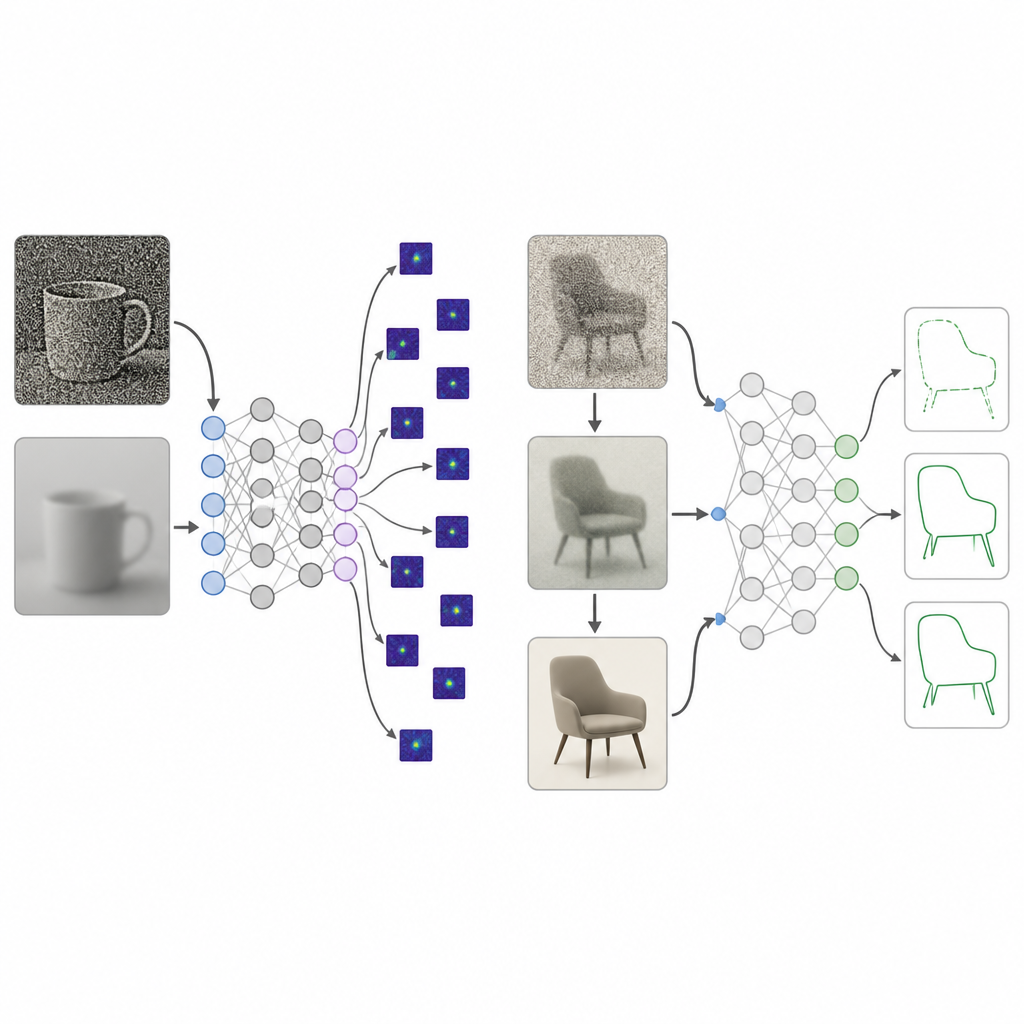
I neonati umani non iniziano la vita con una vista cristallina. Il loro mondo è inizialmente sfocato, a basso contrasto e povero di colore, e soltanto lentamente diventa nitido e vivido nel corso di molti anni. I ricercatori hanno raccolto decenni di studi su come tre aspetti della visione maturano dalla nascita fino a circa 25 anni: nitidezza, sensibilità al contrasto e sensibilità al colore. Hanno trasformato queste misurazioni in un “curriculum” di elaborazione delle immagini che chiamano dieta visiva di sviluppo. Durante l’addestramento, le immagini somministrate a una rete sono prima fortemente sfocate, a basso contrasto e vicine al grigio, poi gradualmente diventano più chiare, ricche di contrasto e completamente colorate, rispecchiando la crescita visiva umana.
Da una visione guidata dalla texture a una focalizzata sulla forma
Le reti profonde addestrate con questa dieta visiva di sviluppo sono state confrontate con l’addestramento classico su immagini di alta qualità. Attraverso diversi progetti di modello e collezioni di immagini, il nuovo approccio ha prodotto una preferenza per la forma molto più marcata, raggiungendo la gamma osservata negli osservatori umani senza perdere molto in termini di accuratezza di riconoscimento standard. Quando i ricercatori hanno esaminato su quali parti dell’immagine i modelli si affidassero, i sistemi addestrati con il curriculum di sviluppo si concentravano sulle regioni dell’oggetto intero, mentre i modelli standard fissavano piccole patch di texture o aree di sfondo. Test aggiuntivi hanno mostrato che il miglioramento graduale del contrasto, più che la sola sfocatura o il colore, ha giocato un ruolo chiave nel spingere le reti a usare la struttura ampia dell’oggetto invece di dettagli locali sparsi.
Riconoscere forme nascoste e gestire immagini disordinate
Il team ha poi sfidato i modelli con immagini in cui forme familiari come una bicicletta o un delfino erano sottilmente intrecciate in scene complesse. Le persone individuano facilmente questi contorni, ma la maggior parte dei sistemi esistenti, compresi i grandi modelli visione–linguaggio, risponde principalmente allo sfondo della scena. Le reti cresciute con la dieta visiva di sviluppo erano molto più brave a richiamare le forme nascoste e meno distratte dalla scena. Reggevano inoltre molto meglio quando le immagini venivano corrotte da sfocatura, rumore, scarsa illuminazione o effetti simili al maltempo come pioggia e neve, spesso eguagliando le tendenze umane. Anche contro attacchi avversari, dove piccole modifiche digitali ingannano molti modelli, i sistemi addestrati con il curriculum di sviluppo restavano sostanzialmente più accurati rispetto ai corrispondenti standard o addestrati avversarialmente.
Cosa significa per un’IA più sicura e più simile all’umano
Offrendo all’IA un’infanzia visiva che riecheggia la nostra, questo lavoro dimostra che come viene addestrato un modello può contare tanto quanto quanto è grande. Un curriculum semplice e ispirato alla biologia ha spinto le reti lontano da trucchi fragili basati sulle texture e verso l’uso robusto della forma, migliorando il riconoscimento di forme astratte nel disordine e la resistenza sia alle distorsioni naturali sia agli attacchi ostili. Per i non specialisti, il messaggio chiave è che partire da una visione “povera” e lasciarla maturare può effettivamente aiutare le macchine a imparare modi di vedere più solidi e più simili a quelli umani, offrendo una strada più efficiente in termini di risorse verso un’IA visiva più sicura.
Citazione: Lu, Z., Thorat, S., Cichy, R.M. et al. Adopting a human developmental visual diet yields robust and shape-based AI vision. Nat Mach Intell 8, 735–748 (2026). https://doi.org/10.1038/s42256-026-01228-6
Parole chiave: visione AI, sviluppo visivo, bias di forma, percezione robusta, deep learning