Clear Sky Science · pl
Przyjęcie ludzkiej, rozwojowej diety wzrokowej daje trwałą i opartą na kształcie wizję AI
Dlaczego warto uczyć komputery widzieć jak dzieci
Współczesna wizja komputerowa potrafi oznaczać twoje zdjęcia i wspomagać samochody autonomiczne, ale wciąż postrzega świat bardzo inaczej niż my. Tam, gdzie ludzie naturalnie wychwytują ogólny kształt obiektów i radzą sobie z rozmyciem, szumem czy bałaganem, wiele systemów sztucznej inteligencji przyczepia się do drobnych tekstur i zawodzi, gdy obrazy są zniekształcone. Ten artykuł bada nowy pomysł: zamiast tylko powiększać modele wizji, co by było, gdyby wychowywać je bardziej jak ludzkie dzieci, stopniowo poprawiając to, co widzą?

Jak komputery i ludzie widzą inaczej
Większość popularnych systemów wizji jest trenowana od początku na ostrych, o wysokim kontraście, pełnokolorowych obrazach. W efekcie mają skłonność do silnego polegania na szczegółach powierzchni, takich jak wzory futra czy faktura cegieł. W starannie zaprojektowanych testach, w których obrys obiektu i wzór powierzchni są ze sobą w konflikcie, ludzie niemal zawsze wybierają według obrysu, podczas gdy standardowe sieci zwykle podążają za teksturą. Modele te mają też trudności z dostrzeganiem prostych kształtów ukrytych w zatłoczonych scenach, a ich działanie może się załamać przy rozmyciu, szumie czy drobnych cyfrowych modyfikacjach niewidocznych dla nas. Wszystkie te problemy wskazują na zasadnicze niezgodności między wizją sztuczną a ludzką.
Zapożyczenie wizualnego dzieciństwa ludzi
Niemowlęta nie zaczynają życia z krystalicznie czystym wzrokiem. Ich świat jest początkowo rozmyty, o niskim kontraście i ubogi w kolory, i dopiero powoli staje się ostry i żywy przez wiele lat. Badacze zebrali dziesięciolecia badań nad tym, jak trzy aspekty widzenia dojrzewają od urodzenia do około 25. roku życia: ostrość, czułość na kontrast i czułość na kolor. Przekształcili te pomiary w „kurriculum” przetwarzania obrazu, które nazywają rozwojową dietą wzrokową. Podczas treningu obrazy podawane sieci są najpierw mocno rozmyte, o niskim kontraście i bliskie szarości, a następnie krok po kroku stają się wyraźniejsze, bardziej kontrastowe i pełnokolorowe, odzwierciedlając ludzki rozwój wzroku.
Od podążania za teksturą do widzenia skoncentrowanego na kształcie
Sieci głębokie trenowane z tą rozwojową dietą wzrokową porównano z tradycyjnym treningiem na wysokiej jakości obrazach. W różnych architekturach modeli i zbiorach danych nowe podejście dało znacznie silniejsze preferencje wobec kształtu, osiągając poziom obserwowany u ludzkich obserwatorów przy jednoczesnym zachowaniu większości standardowej dokładności rozpoznawania. Gdy badacze sprawdzili, na których częściach obrazu modele polegają, systemy trenowane rozwojowo skupiały się na regionach obejmujących całe obiekty, podczas gdy modele standardowe fiksowały się na małych fragmentach tekstury lub obszarach tła. Dalsze testy wykazały, że stopniowe zwiększanie kontrastu, bardziej niż samo rozmycie czy kolor, odegrało kluczową rolę w przesunięciu sieci w stronę wykorzystywania szerokiej struktury obiektu zamiast rozproszonych lokalnych detali.
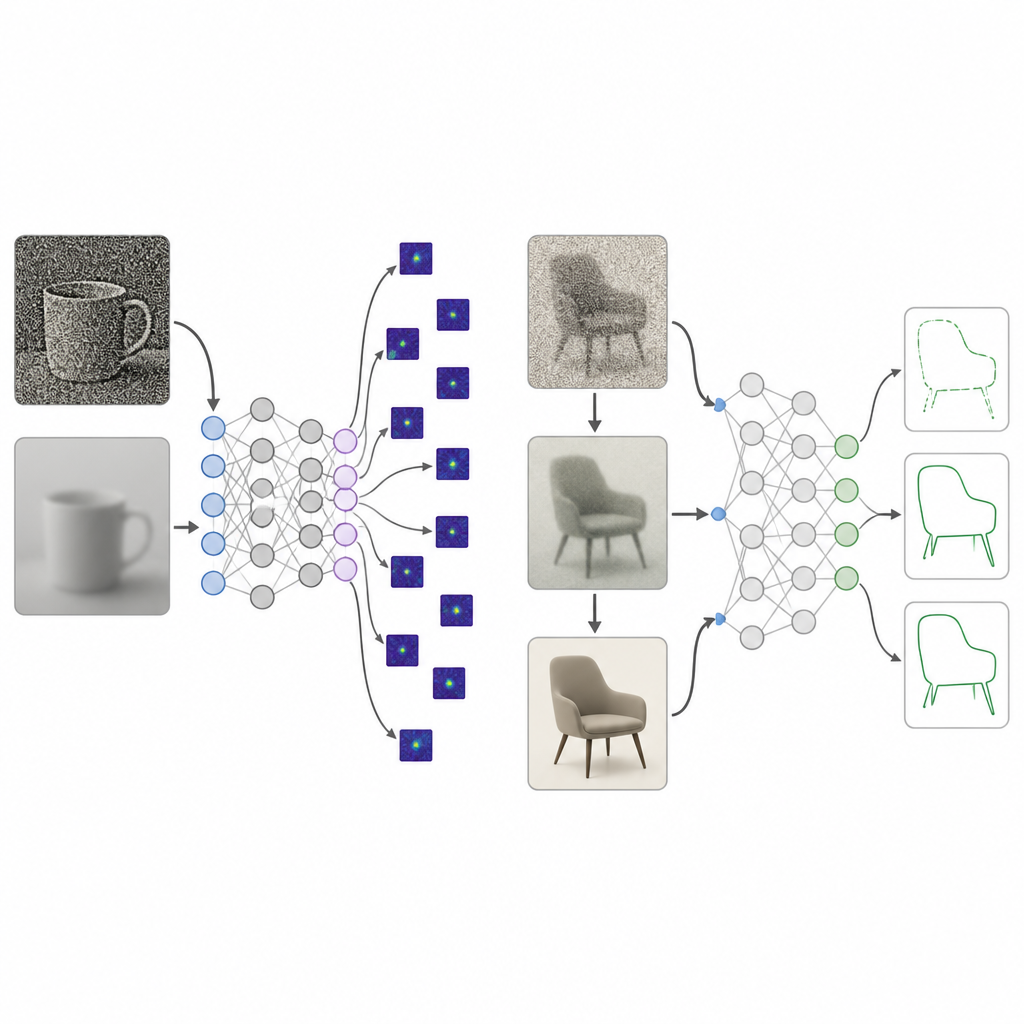
Rozpoznawanie ukrytych kształtów i radzenie sobie z zabałaganionymi obrazami
Zespół postawił następnie modele wobec obrazów, w których znajome kształty, takie jak rower czy delfin, były subtelnie wplecione w złożone sceny. Ludzie z łatwością wychwytują te kontury, ale większość istniejących systemów, w tym duże modele wizja–język, reaguje głównie na tło sceny. Sieci wychowane na rozwojowej diecie wzrokowej były znacznie lepsze w przypominaniu ukrytych kształtów i mniej rozpraszały się sceną. Radziły sobie też znacznie lepiej, gdy obrazy były zniekształcone przez rozmycie, szum, słabe oświetlenie czy efekty przypominające pogodę, takie jak deszcz i śnieg, często odwzorowując trendy ludzkie. Nawet wobec ataków adwersarialnych, gdzie drobne cyfrowe zmiany mylą wiele modeli, systemy trenowane rozwojowo pozostawały zauważalnie bardziej dokładne niż standardowe czy specjalnie odporne warianty.
Co to oznacza dla bezpieczniejszej i bardziej ludzkiej AI
Dając AI wizualne dzieciństwo odbijające nasze własne, ta praca pokazuje, że sposób, w jaki model jest trenowany, może mieć równie duże znaczenie jak jego rozmiar. Proste, inspirowane biologicznie kurriculum odciągnęło sieci od kruchych sztuczek z teksturą i skierowało je ku odpornej pracy na kształcie, poprawiło rozpoznawanie abstrakcyjnych form w zagraconych scenach oraz zwiększyło odporność na naturalne zniekształcenia i wrogie ataki. Dla osób niebędących specjalistami kluczowy wniosek jest taki, że zaczynając od „słabszego” widzenia i pozwalając mu dojrzewać, można pomóc maszynom nauczyć się solidniejszych, bardziej ludzkich sposobów widzenia, oferując bardziej efektywną pod względem zasobów ścieżkę do bezpieczniejszej wizualnej sztucznej inteligencji.
Cytowanie: Lu, Z., Thorat, S., Cichy, R.M. et al. Adopting a human developmental visual diet yields robust and shape-based AI vision. Nat Mach Intell 8, 735–748 (2026). https://doi.org/10.1038/s42256-026-01228-6
Słowa kluczowe: wizja AI, rozwój wzrokowy, uprzedzenie kształtu, odporne postrzeganie, uczenie głębokie