Clear Sky Science · fr
Adopter un régime visuel de développement humain produit une vision IA robuste et fondée sur la forme
Pourquoi apprendre aux ordinateurs à voir comme des enfants importe
La vision par ordinateur moderne peut étiqueter vos photos et guider des véhicules autonomes, mais elle voit encore le monde très différemment de nous. Là où les humains saisissent naturellement la forme d’ensemble des objets et gèrent le flou, le bruit et l’encombrement, de nombreux systèmes d’intelligence artificielle s’accrochent à de fins détails de texture et s’effondrent lorsque les images sont dégradées. Cet article explore une idée nouvelle : au lieu de simplement rendre les modèles de vision plus grands, et si on les élevait davantage comme des enfants humains, en améliorant progressivement ce qu’ils voient au fil du temps ?

Comment les ordinateurs et les humains voient différemment aujourd’hui
La plupart des systèmes de vision populaires sont entraînés dès le départ sur des images nettes, à fort contraste et en couleur. En conséquence, ils ont tendance à s’appuyer fortement sur des détails de surface comme les motifs de pelage ou la texture des briques. Dans des tests soigneusement conçus où le contour d’un objet et son motif de surface sont mis en conflit, les humains choisissent presque toujours selon le contour, tandis que les réseaux standard suivent généralement la texture. Ces modèles ont aussi du mal à repérer des formes simples dissimulées dans des scènes encombrées, et leurs performances peuvent s’effondrer sous l’effet du flou, du bruit ou de petites altérations numériques invisibles pour nous. Tous ces problèmes indiquent un décalage fondamental entre la vision artificielle et la vision humaine.
Emprunter l’enfance visuelle des humains
Les bébés humains ne commencent pas la vie avec une vue cristalline. Leur monde est d’abord flou, peu contrasté et pauvre en couleurs, et ne devient précis et vivant que lentement, sur de nombreuses années. Les chercheurs ont rassemblé des décennies d’études sur la maturation, de la naissance jusqu’à environ 25 ans, de trois aspects de la vision : l’acuité, la sensibilité au contraste et la sensibilité aux couleurs. Ils ont transformé ces mesures en un « curriculum » de traitement d’images qu’ils appellent un régime visuel développemental. Lors de l’entraînement, les images présentées au réseau sont d’abord fortement floutées, à faible contraste et proches du gris, puis deviennent étape par étape plus nettes, plus contrastées et pleinement colorées, reflétant la croissance visuelle humaine.
De la vision axée sur la texture à la vision centrée sur la forme
Des réseaux profonds entraînés avec ce régime visuel développemental ont été comparés à l’entraînement classique sur images haute qualité. À travers plusieurs architectures et jeux d’images, la nouvelle approche a produit une préférence bien plus marquée pour la forme, atteignant la fourchette observée chez les sujets humains tout en perdant peu en précision de reconnaissance standard. Lorsque les chercheurs ont examiné les parties de l’image sur lesquelles les modèles se fiaient, les systèmes entraînés de manière développementale se concentraient sur des régions d’objet globales, tandis que les modèles standard fixaient des petits patchs de texture ou des zones d’arrière-plan. D’autres tests ont montré que l’amélioration progressive du contraste, plus que le flou ou la couleur seuls, jouait un rôle clé pour pousser les réseaux à utiliser la structure large de l’objet plutôt que des détails locaux dispersés.
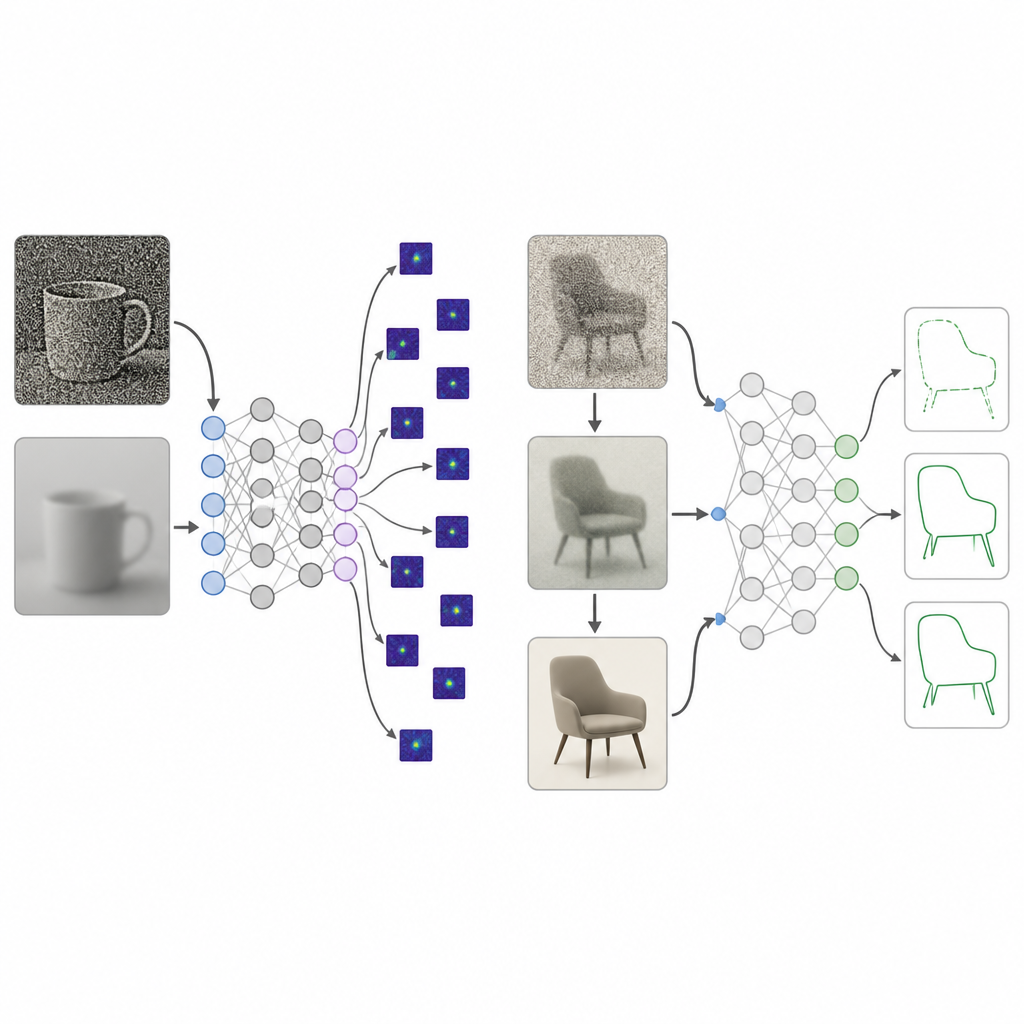
Reconnaître des formes cachées et gérer des images encombrées
L’équipe a ensuite mis les modèles au défi avec des images où des formes familières comme un vélo ou un dauphin étaient subtilement tissées dans des scènes complexes. Les humains repèrent facilement ces contours, mais la plupart des systèmes existants, y compris de grands modèles vision–langage, répondent principalement à l’arrière-plan de la scène. Les réseaux élevés avec le régime visuel développemental se sont montrés bien meilleurs pour rappeler les formes cachées et moins distraits par la scène. Ils ont aussi tenu beaucoup mieux le coup lorsque les images étaient corrompues par le flou, le bruit, un mauvais éclairage ou des effets météorologiques comme la pluie et la neige, souvent en suivant les tendances humaines. Même face à des attaques adversariales, où de minuscules modifications numériques trompent de nombreux modèles, les systèmes entraînés de façon développementale sont restés sensiblement plus précis que leurs homologues standard ou entraînés adversarialement.
Ce que cela signifie pour une IA plus sûre et plus humaine
En donnant à l’IA une enfance visuelle qui fait écho à la nôtre, ce travail montre que la façon dont un modèle est entraîné peut avoir autant d’importance que sa taille. Un curriculum simple, inspiré biologiquement, a détourné les réseaux de ruses fragiles basées sur la texture vers une utilisation robuste de la forme, amélioré la reconnaissance de formes abstraites dans le désordre et renforcé la résistance aux distorsions naturelles comme aux attaques hostiles. Pour un public non spécialiste, le message clé est que commencer par une vision « pauvre » et la laisser mûrir peut en réalité aider les machines à apprendre des façons de voir plus solides et plus proches de l’humain, offrant une voie plus économe en ressources vers une IA visuelle plus sûre.
Citation: Lu, Z., Thorat, S., Cichy, R.M. et al. Adopting a human developmental visual diet yields robust and shape-based AI vision. Nat Mach Intell 8, 735–748 (2026). https://doi.org/10.1038/s42256-026-01228-6
Mots-clés: vision par IA, développement visuel, biais de forme, perception robuste, apprentissage profond