Clear Sky Science · sv
Att adoptera en mänsklig utvecklingsbaserad visuell diet ger robust och formbaserad AI-syn
Varför det spelar roll att lära datorer att se som barn
Modern datorseende kan tagga dina foton och styra självkörande bilar, men det ser fortfarande världen mycket annorlunda än vi gör. Där människor naturligt uppfattar objektens övergripande form och klarar av suddighet, brus och rörighet, hakar många artificiella intelligenssystem upp sig på finare texturer och faller samman när bilder blir förvrängda. Denna artikel utforskar en ny idé: i stället för att bara göra synmodeller större, vad händer om vi uppfostrar dem mer som mänskliga barn och gradvis förbättrar vad de ser över tid?

Hur datorer och människor för närvarande ser olika
De flesta populära synsystem tränas från början på skarpa, högkontrast- och fullfärgade bilder. Som ett resultat tenderar de att förlita sig starkt på ytdetaljer som pälsmönster eller tegelstrukturer. I noggrant utformade tester där ett objekts kontur och dess ytmönster sätts i konflikt väljer människor nästan alltid enligt konturen, medan standardnätverk vanligtvis följer texturen. Dessa modeller har också svårt att hitta enkla former som döljs i röriga scener, och deras prestanda kan kollapsa vid suddighet, brus eller små digitala ändringar som är osynliga för oss. Alla dessa problem pekar på en grundläggande missanpassning mellan artificiell och mänsklig syn.
Att låna människans visuella barndom
Babyns syn börjar inte livet krispklar. Deras värld är initialt suddig, låg i kontrast och fattig på färg, och blir först långsamt skarp och levande över många år. Forskarna samlade decennier av studier om hur tre aspekter av synen mognar från födseln till omkring 25 års ålder: skärpa, kontrastkänslighet och färgkänslighet. De omvandlade dessa mätningar till ett bildbehandlings-"curriculum" som de kallar en utvecklingsbaserad visuell diet. Under träningen matas bilder till ett nätverk som först är kraftigt suddiga, låga i kontrast och nära gråskaliga, för att stegvis bli klarare, rikare i kontrast och fullt färgade, i en spegling av människans visuella tillväxt.
Från texturföljande till formfokuserad syn
Djupa nätverk tränade med denna utvecklingsbaserade visuella diet jämfördes med den vanliga träningen på högkvalitativa bilder. Över flera modelltyper och bildsamlingar gav det nya tillvägagångssättet en mycket starkare preferens för form, inom det intervall som ses hos mänskliga observatörer, samtidigt som det tappade lite i standardigenkänningsnoggrannhet. När forskarna undersökte vilka delar av en bild modellerna förlitade sig på fokuserade de utvecklingstränade systemen på hela objektregioner, medan standardmodellerna fixerade på små texturfläckar eller bakgrundsområden. Ytterligare tester visade att den gradvisa förbättringen av kontrast, mer än suddighet eller färg ensamt, spelade en nyckelroll för att driva nätverk mot att använda bred objektstruktur i stället för spridda lokala detaljer.
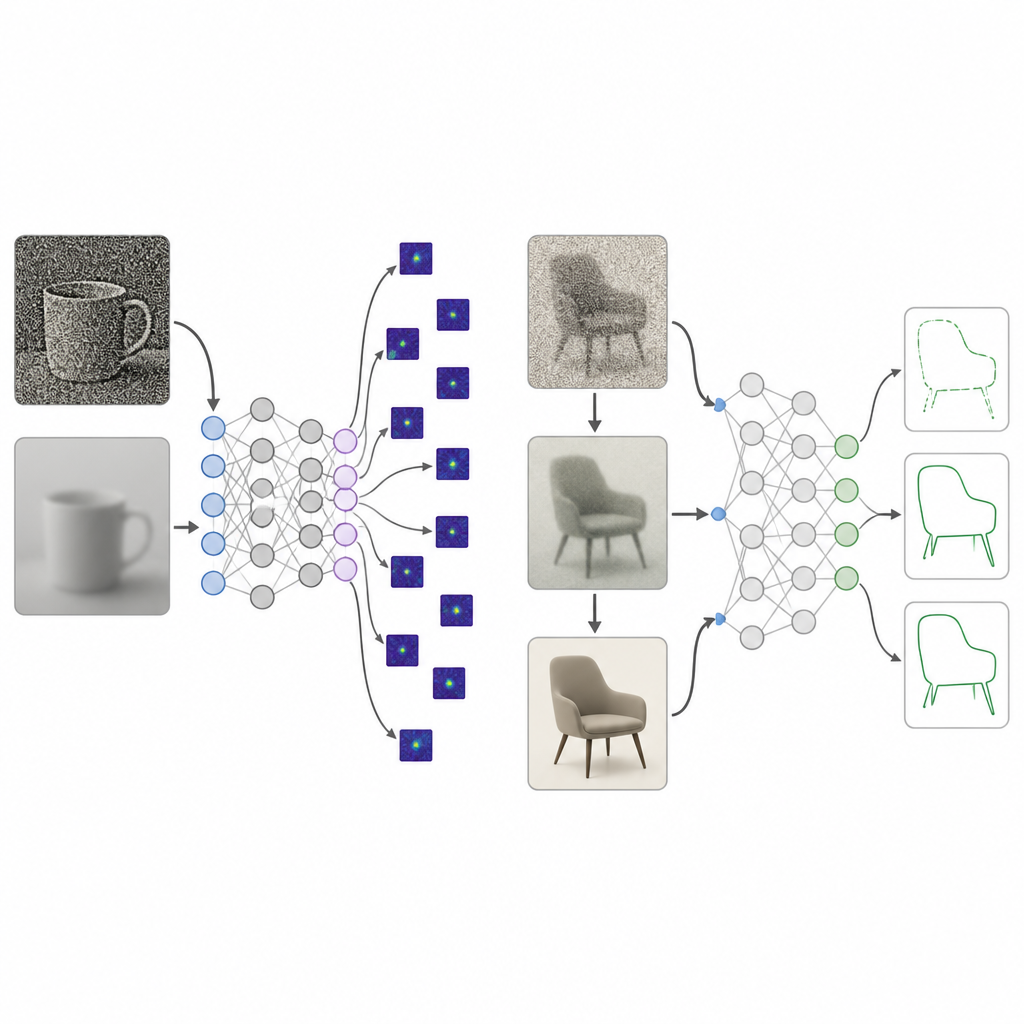
Att känna igen dolda former och hantera röriga bilder
Teamet utmanade sedan modellerna med bilder där bekanta former som en cykel eller en delfin subtilt vävts in i komplexa scener. Människor upptäcker lätt dessa konturer, men de flesta befintliga system, inklusive stora visions–språk-modeller, reagerar främst på scenens bakgrund. Nätverk som fostrats med den utvecklingsbaserade visuella dieten var mycket bättre på att återkalla de dolda formerna och mindre lättdistraherade av scenen. De höll sig också långt bättre när bilder korruptes av suddighet, brus, dålig belysning eller väderliknande effekter som regn och snö, ofta i linje med mänskliga mönster. Även mot adversariala attacker, där små digitala förändringar lurar många modeller, förblev de utvecklingstränade systemen avsevärt mer korrekta än standard- eller adversarialt tränade motsvarigheter.
Vad detta betyder för säkrare och mer människolik AI
Genom att mata AI med en visuell barndom som ekar vår egen visar detta arbete att hur en modell tränas kan vara lika viktigt som hur stor den är. Ett enkelt, biologiskt inspirerat curriculum flyttade nätverk bort från spröda texturknep och mot robust användning av form, förbättrad igenkänning av abstrakta former i röran och bättre motstånd mot både naturliga förvrängningar och fientliga attacker. För icke-specialister är huvudbudskapet att börja med "sämre" syn och låta den mogna faktiskt kan hjälpa maskiner att lära sig stadigare, mer människolika sätt att se, och erbjuda en mer resurseffektiv väg mot säkrare visuell AI.
Citering: Lu, Z., Thorat, S., Cichy, R.M. et al. Adopting a human developmental visual diet yields robust and shape-based AI vision. Nat Mach Intell 8, 735–748 (2026). https://doi.org/10.1038/s42256-026-01228-6
Nyckelord: AI-syn, visuell utveckling, form-bias, robust perception, djuplärande