Clear Sky Science · pt
Adotar uma dieta visual de desenvolvimento humano produz visão de IA robusta e baseada em forma
Por que ensinar computadores a ver como crianças importa
A visão computacional moderna pode marcar suas fotos e guiar carros autônomos, mas ainda vê o mundo de maneira bem diferente da nossa. Onde as pessoas naturalmente captam a forma geral dos objetos e lidam com desfoque, ruído e desordem, muitos sistemas de inteligência artificial se fixam em texturas finas e desmoronam quando as imagens são distorcidas. Este artigo explora uma ideia nova: em vez de apenas tornar modelos de visão maiores, e se os criássemos mais como crianças humanas, melhorando gradualmente aquilo que veem ao longo do tempo?

Como computadores e pessoas veem de forma diferente hoje
A maioria dos sistemas de visão populares é treinada desde o início com imagens nítidas, de alto contraste e cores completas. Como resultado, eles tendem a depender fortemente de detalhes superficiais, como padrões de pelagem ou texturas de tijolo. Em testes cuidadosamente projetados, onde o contorno de um objeto e seu padrão de superfície entram em conflito, os humanos quase sempre escolhem conforme o contorno, enquanto redes padrão normalmente seguem a textura. Esses modelos também têm dificuldade em identificar formas simples ocultas em cenas ocupadas, e seu desempenho pode colapsar sob desfoque, ruído ou pequenos ajustes digitais invisíveis para nós. Todos esses problemas apontam para um descompasso básico entre a visão artificial e a humana.
Tomando emprestada a infância visual dos humanos
Bebês humanos não começam a vida com visão cristalina. O mundo deles é inicialmente borrado, de baixo contraste e pobre em cor, e só lentamente se torna nítido e vívido ao longo de muitos anos. Os pesquisadores reuniram décadas de estudos sobre como três aspectos da visão amadurecem desde o nascimento até cerca de 25 anos: acuidade (nitidez), sensibilidade ao contraste e sensibilidade à cor. Eles transformaram essas medidas em um “currículo” de processamento de imagens que chamam de dieta visual de desenvolvimento. Durante o treinamento, as imagens fornecidas a uma rede são primeiro fortemente borradas, de baixo contraste e próximas do cinza, e então, passo a passo, tornam-se mais claras, ricas em contraste e totalmente coloridas, espelhando o crescimento visual humano.
De seguir texturas a focar na forma
Redes profundas treinadas com essa dieta visual de desenvolvimento foram comparadas ao treinamento habitual com alta qualidade. Em vários projetos de modelo e coleções de imagens, a nova abordagem produziu uma preferência por forma muito mais forte, alcançando a faixa observada em observadores humanos, sem perder quase nada em acurácia de reconhecimento padrão. Quando os pesquisadores examinaram em quais partes da imagem os modelos se apoiavam, os sistemas treinados de forma desenvolvimental focavam em regiões de objeto inteiras, enquanto os modelos padrão fixavam-se em pequenos pedaços de textura ou áreas de fundo. Testes adicionais mostraram que a melhoria gradual do contraste, mais do que o desfoque ou a cor isoladamente, desempenhou um papel chave em empurrar as redes a usar a estrutura ampla do objeto em vez de detalhes locais dispersos.
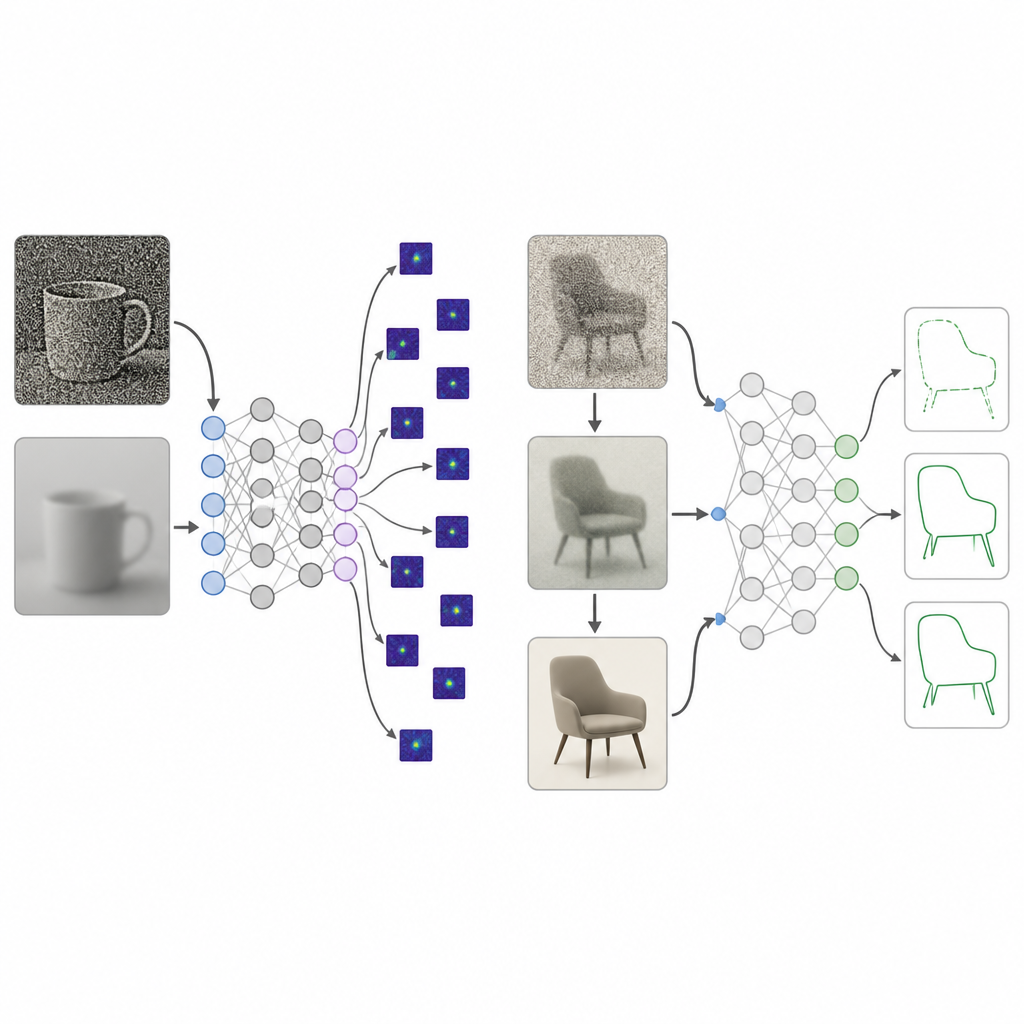
Reconhecendo formas ocultas e lidando com imagens bagunçadas
A equipe em seguida desafiou os modelos com imagens onde formas familiares, como uma bicicleta ou um golfinho, estavam sutilmente entrelaçadas em cenas complexas. Pessoas detectam esses contornos facilmente, mas a maioria dos sistemas existentes, incluindo grandes modelos de visão e linguagem, responde principalmente ao fundo da cena. Redes criadas com a dieta visual de desenvolvimento se saíram muito melhor em recuperar as formas ocultas e ficaram menos distraídas pela cena. Elas também aguentaram muito melhor quando as imagens foram corrompidas por desfoque, ruído, iluminação ruim ou efeitos parecidos com clima, como chuva e neve, frequentemente igualando tendências humanas. Mesmo contra ataques adversariais, onde pequenas mudanças digitais enganam muitos modelos, os sistemas treinados desenvolvimentalmente mantiveram-se substancialmente mais precisos do que os equivalentes padrão ou treinados adversarialmente.
O que isso significa para IA mais segura e mais parecida com a humana
Ao alimentar a IA com uma infância visual que ecoa a nossa, este trabalho mostra que como um modelo é treinado pode importar tanto quanto o seu tamanho. Um currículo simples, inspirado biologicamente, afastou as redes de truques frágeis baseados em textura e as conduziu ao uso robusto da forma, melhor reconhecimento de formas abstratas em meio à desordem e maior resistência tanto a distorções naturais quanto a ataques hostis. Para não especialistas, a mensagem chave é que começar com uma visão “pobre” e deixá-la amadurecer pode, na verdade, ajudar máquinas a aprender modos de ver mais sólidos e mais humanos, oferecendo um caminho mais eficiente em recursos rumo a uma visão artificial mais segura.
Citação: Lu, Z., Thorat, S., Cichy, R.M. et al. Adopting a human developmental visual diet yields robust and shape-based AI vision. Nat Mach Intell 8, 735–748 (2026). https://doi.org/10.1038/s42256-026-01228-6
Palavras-chave: visão por IA, desenvolvimento visual, viés de forma, percepção robusta, aprendizado profundo