Clear Sky Science · nl
Een menselijk ontwikkelingsgericht visueel dieet levert robuuste en vormgebaseerde AI-visie op
Waarom het belangrijk is om computers te leren zien zoals kinderen
Moderne computervisie kan je foto’s taggen en zelfrijdende auto’s helpen, maar ziet de wereld nog steeds heel anders dan wij. Waar mensen vanzelf het globale silhouet van objecten begrijpen en omgaan met onscherpte, ruis en rommel, hechten veel kunstmatige-intelligentiesystemen zich aan fijne texturen en vallen ze uit elkaar wanneer beelden worden vervormd. Dit artikel bespreekt een nieuw idee: in plaats van visiemodellen alleen maar groter te maken, wat als we ze meer zouden opvoeden zoals menselijke kinderen, en geleidelijk zouden verbeteren wat ze te zien krijgen?

Hoe computers en mensen nu anders zien
De meeste gangbare visiesystemen worden vanaf het begin getraind op scherpe, hoogcontrasterende, kleurrijke beelden. Daardoor vertrouwen ze sterk op oppervlaktedetails zoals vachtpatronen of baksteenstructuren. In zorgvuldig opgezette tests waarin de contour van een object en het oppervlakspatroon met elkaar in conflict zijn, kiezen mensen bijna altijd op basis van de omtrek, terwijl standaardnetwerken meestal de textuur volgen. Deze modellen hebben ook moeite om eenvoudige vormen in drukke scènes te herkennen, en hun prestaties kunnen instorten bij onscherpte, ruis of kleine digitale aanpassingen die voor ons onzichtbaar zijn. Al deze problemen wijzen op een fundamentele mismatch tussen kunstmatige en menselijke visie.
Het visuele kinderleven van mensen lenen
Babies beginnen het leven niet met kristalhelder zicht. Hun wereld is aanvankelijk wazig, weinig contrastrijk en arm aan kleur, en wordt pas langzaam scherp en levendig over vele jaren. De onderzoekers verzamelden decennia aan studies over hoe drie aspecten van het zicht zich ontwikkelen van de geboorte tot ongeveer 25 jaar: scherpte, contrastgevoeligheid en kleurgevoeligheid. Ze zetten deze metingen om in een beeldverwerkings-„curriculum” dat ze een ontwikkelingsgericht visueel dieet noemen. Tijdens training worden beelden die aan een netwerk worden gevoerd eerst sterk vervaagd, laag in contrast en bijna grijs, en stap voor stap helderder, rijker aan contrast en volledig gekleurd, wat de menselijke visuele groei weerspiegelt.
Van textuurvolgend naar vormgericht zien
Diepe netwerken die met dit ontwikkelingsgerichte visuele dieet werden getraind, werden vergeleken met de gebruikelijke hoogkwalitatieve training. Over verschillende modelontwerpen en beeldverzamelingen produceerde de nieuwe aanpak een veel sterkere voorkeur voor vorm, binnen het bereik dat bij menselijke waarnemers wordt gezien, terwijl ze weinig verloren in standaard herkenningsnauwkeurigheid. Toen de onderzoekers onderzochten op welke delen van een afbeelding de modellen vertrouwden, richtten de ontwikkelingstrainingnetwerken zich op hele objectgebieden, terwijl de standaardmodellen zich fixeerden op kleine textuurvlekken of achtergrondgebieden. Verdere tests toonden aan dat de geleidelijke verbetering van contrast, meer dan alleen onscherpte of kleur, een sleutelrol speelde bij het duwen van netwerken naar het gebruiken van brede objectstructuur in plaats van verspreide lokale details.
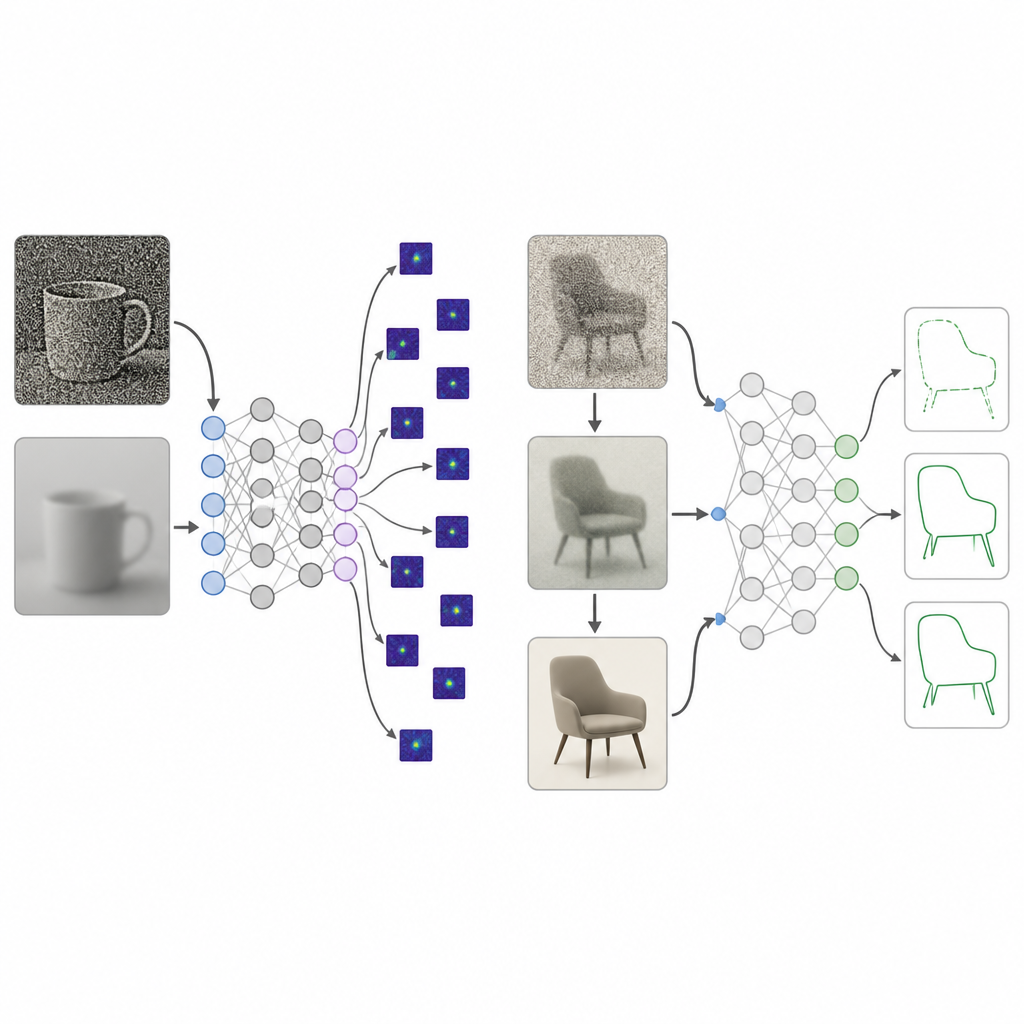
Verborgen vormen herkennen en omgaan met rommelige beelden
Het team daagde de modellen vervolgens uit met afbeeldingen waarin bekende vormen zoals een fiets of dolfijn subtiel waren verweven in complexe scènes. Mensen zien deze contouren gemakkelijk, maar de meeste bestaande systemen, inclusief grote visie–taalmodellen, reageren vooral op de achtergrond van de scène. Netwerken die waren opgegroeid met het ontwikkelingsgerichte visuele dieet waren veel beter in het terugvinden van de verborgen vormen en minder snel afgeleid door de scène. Ze hielden het ook veel beter vol wanneer beelden werden gecorrumpeerd door onscherpte, ruis, slechte belichting of weersachtige effecten zoals regen en sneeuw, en volgden vaak menselijke trends. Zelfs tegen adversariële aanvallen, waarbij kleine digitale veranderingen veel modellen misleiden, bleven de ontwikkelingsgetrainde systemen aanzienlijk nauwkeuriger dan standaard of adversariëel getrainde tegenhangers.
Wat dit betekent voor veiliger en menselijker AI
Door AI een visuele kindertijd te geven die onze eigen echoot, toont dit werk aan dat de manier waarop een model wordt getraind even belangrijk kan zijn als hoe groot het is. Een eenvoudig, biologisch geïnspireerd curriculum duwde netwerken weg van broze textuurtrucs en richting robuust gebruik van vorm, verbeterde herkenning van abstracte vormen in rommel en betere weerstand tegen zowel natuurlijke vervormingen als vijandige aanvallen. Voor niet-specialisten is de kernboodschap dat beginnen met „slecht” zicht en het laten rijpen ervan machines juist kan helpen robuustere, meer mensachtige manieren van zien te leren, en daarmee een meer resource-efficiënte route naar veiligere visuele AI biedt.
Bronvermelding: Lu, Z., Thorat, S., Cichy, R.M. et al. Adopting a human developmental visual diet yields robust and shape-based AI vision. Nat Mach Intell 8, 735–748 (2026). https://doi.org/10.1038/s42256-026-01228-6
Trefwoorden: AI-visie, visuele ontwikkeling, vormvoorkeur, robuuste waarneming, deep learning