Clear Sky Science · de
Die Übernahme einer menschlichen entwicklungsbasierten visuellen Diät führt zu robuster und formbasierter KI-Sehfähigkeit
Warum es wichtig ist, Computern das Sehen wie Kindern beizubringen
Moderne Computer-Sehsysteme können Ihre Fotos markieren und selbstfahrende Autos leiten, doch sie sehen die Welt immer noch ganz anders als wir. Während Menschen automatisch die Gesamtform von Objekten erfassen und mit Unschärfe, Rauschen und Unordnung umgehen, klammern sich viele künstliche Intelligenzsysteme an feine Texturen und versagen, wenn Bilder verzerrt werden. Dieser Artikel untersucht eine neue Idee: Statt Vision-Modelle nur größer zu machen, was wäre, wenn wir sie eher wie menschliche Kinder aufziehen und das, was sie sehen, schrittweise verbessern?

Wie Computer und Menschen derzeit unterschiedlich sehen
Die meisten verbreiteten Sehsysteme werden von Anfang an mit scharfen, kontrastreichen Vollfarbbildern trainiert. Infolgedessen verlassen sie sich stark auf Oberflächendetails wie Fellmuster oder Ziegeltexturen. In sorgfältig gestalteten Tests, in denen die Umrisse eines Objekts und sein Oberflächenmuster in Konflikt geraten, wählen Menschen fast immer nach dem Umriss, während Standardnetzwerke meist der Textur folgen. Diese Modelle haben auch Schwierigkeiten, einfache Formen in überladenen Szenen zu erkennen, und ihre Leistung kann bei Unschärfe, Rauschen oder kleinen digitalen Änderungen, die für uns unsichtbar sind, zusammenbrechen. All diese Probleme weisen auf eine grundlegende Diskrepanz zwischen künstlicher und menschlicher Sicht hin.
Die visuelle Kindheit des Menschen entleihen
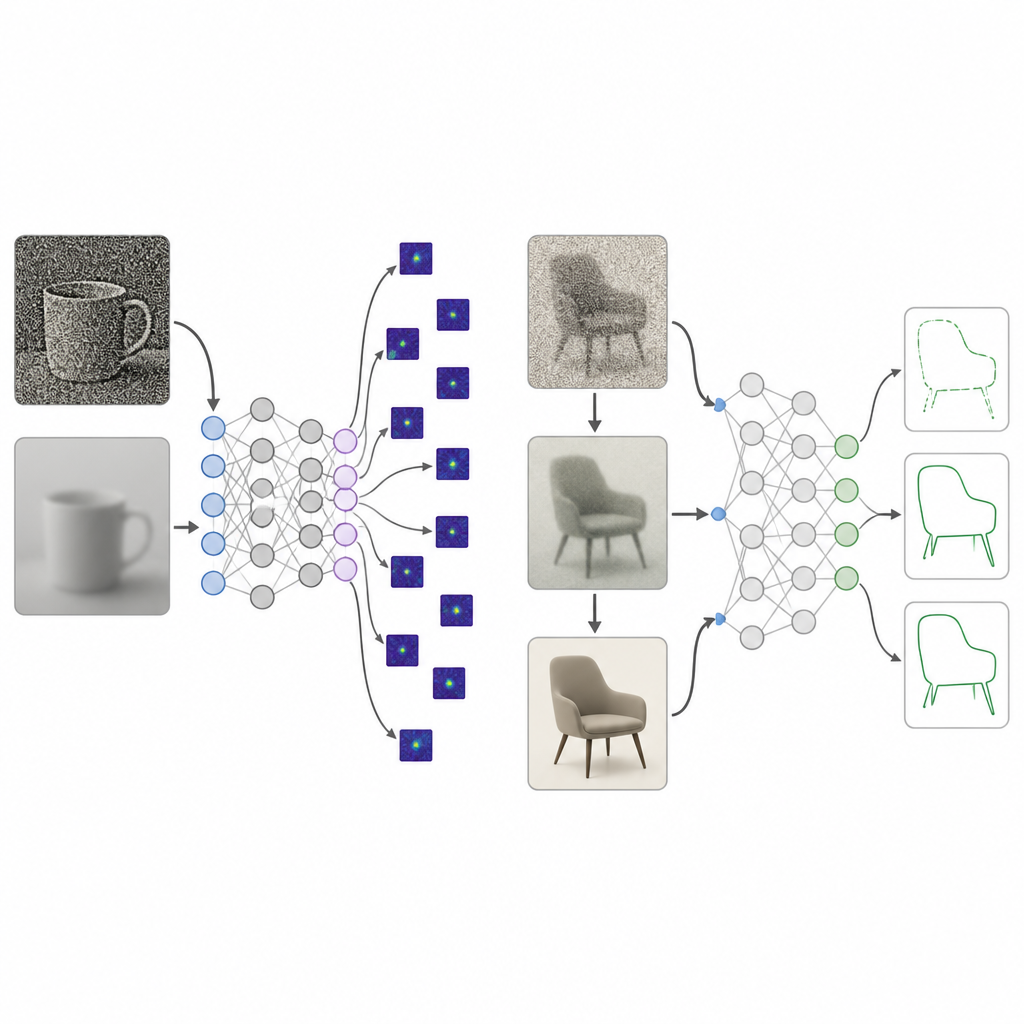
Menschliche Babys beginnen ihr Leben nicht mit kristallklarer Sicht. Ihre Welt ist anfangs verschwommen, kontrastarm und farbschwach und wird nur langsam über viele Jahre hinweg schärfer und lebendiger. Die Forschenden fassten Jahrzehnte an Studien zusammen, wie drei Aspekte des Sehens von der Geburt bis etwa 25 Jahre reifen: Schärfe, Kontrastempfindlichkeit und Farbsensitivität. Sie verwandten diese Messungen in ein Bildverarbeitungs-„Curriculum“, das sie als entwicklungsbasierte visuelle Diät bezeichnen. Während des Trainings werden Bildern, die einem Netzwerk zugeführt werden, zunächst stark verwischt, kontrastarm und graunah gemacht und dann schrittweise klarer, kontrastreicher und voll eingefärbt — was das menschliche visuelle Wachstum nachahmt.
Von der Texturfixierung zur formzentrierten Wahrnehmung
Tiefen-Netzwerke, die mit dieser entwicklungsbasierten visuellen Diät trainiert wurden, wurden mit dem üblichen Training an hochwertigen Bildern verglichen. Über mehrere Modelltypen und Bildsammlungen hinweg erzeugte der neue Ansatz eine deutlich stärkere Präferenz für Form und erreichte Werte, die bei menschlichen Beobachtern liegen, ohne die Standarderkennungsgenauigkeit wesentlich zu verringern. Als die Forschenden untersuchten, auf welche Bildbereiche die Modelle sich stützten, konzentrierten sich die entwicklungsbasiert trainierten Systeme auf ganze Objektregionen, während die Standardmodelle auf kleine Texturpatches oder Hintergrundbereiche fixierten. Weitere Tests zeigten, dass die schrittweise Verbesserung des Kontrasts — mehr noch als allein Unschärfe oder Farbe — eine Schlüsselrolle dabei spielte, Netzwerke dahin zu bringen, breite Objektstrukturen anstelle verstreuter lokaler Details zu nutzen.
Verborgene Formen erkennen und mit unordentlichen Bildern umgehen
Das Team stellte die Modelle anschließend vor Aufgaben, bei denen vertraute Formen wie ein Fahrrad oder ein Delfin subtil in komplexe Szenen eingewoben waren. Menschen erkennen diese Konturen leicht, aber die meisten bestehenden Systeme, einschließlich großer Vision–Language-Modelle, reagieren hauptsächlich auf den Hintergrund der Szene. Netzwerke, die mit der entwicklungsbasierten visuellen Diät aufgewachsen waren, erinnerten sich deutlich besser an die versteckten Formen und ließen sich weniger von der Szene ablenken. Sie hielten sich auch deutlich besser, wenn Bilder durch Unschärfe, Rauschen, schlechte Beleuchtung oder wetterähnliche Effekte wie Regen und Schnee beeinträchtigt wurden und zeigten oft menschähnliche Trends. Selbst gegenüber adversarialen Angriffen, bei denen winzige digitale Änderungen viele Modelle täuschen, blieben die entwicklungsbasiert trainierten Systeme erheblich genauer als Standard- oder adversarial trainierte Gegenstücke.
Was das für sicherere und menschenähnlichere KI bedeutet
Indem man der KI eine visuelle Kindheit verabreicht, die unserer eigenen ähnelt, zeigt diese Arbeit, dass die Art des Trainings genauso wichtig sein kann wie die Größe eines Modells. Ein einfaches, biologisch inspiriertes Curriculum bewegte Netzwerke weg von brüchigen Texturtricks hin zu einer robusten Nutzung von Form, verbesserter Erkennung abstrakter Gestalten in Unordnung und größerer Widerstandsfähigkeit gegenüber natürlichen Verzerrungen und böswilligen Angriffen. Für Nicht-Spezialisten lautet die zentrale Botschaft: Mit „schlechtem“ Sehen zu beginnen und es reifen zu lassen kann Maschinen tatsächlich helfen, stabilere, menschenähnlichere Sehweisen zu erlernen und bietet einen ressourceneffizienteren Weg zu sichererer visueller KI.
Zitation: Lu, Z., Thorat, S., Cichy, R.M. et al. Adopting a human developmental visual diet yields robust and shape-based AI vision. Nat Mach Intell 8, 735–748 (2026). https://doi.org/10.1038/s42256-026-01228-6
Schlüsselwörter: KI-Sehen, visuelle Entwicklung, Form-Bias, robuste Wahrnehmung, Deep Learning