Clear Sky Science · en
Adopting a human developmental visual diet yields robust and shape-based AI vision
Why teaching computers to see like children matters
Modern computer vision can tag your photos and guide self-driving cars, yet it still sees the world very differently from us. Where people naturally grasp the overall shape of objects and cope with blur, noise and clutter, many artificial intelligence systems latch onto fine textures and fall apart when images are distorted. This article explores a fresh idea: instead of just making vision models bigger, what if we raised them more like human children, gradually improving what they see over time?

How computers and people currently see differently
Most popular vision systems are trained from the start on sharp, high-contrast, full-color images. As a result, they tend to rely heavily on surface details such as fur patterns or brick textures. In carefully designed tests where an object’s outline and its surface pattern are put into conflict, humans almost always choose according to the outline, while standard networks usually follow the texture. These models also struggle to spot simple shapes hidden in busy scenes, and their performance can collapse under blur, noise, or tiny digital tweaks that are invisible to us. All these problems point to a basic mismatch between artificial and human vision.
Borrowing the visual childhood of humans
Human babies do not start life with crystal-clear sight. Their world is initially blurry, low in contrast, and poor in color, and only slowly becomes sharp and vivid over many years. The researchers pulled together decades of studies on how three aspects of vision mature from birth to about 25 years of age: sharpness, contrast sensitivity, and color sensitivity. They turned these measurements into an image processing “curriculum” they call a developmental visual diet. During training, images fed to a network are first heavily blurred, low contrast, and close to gray, then step by step become clearer, richer in contrast, and fully colored, mirroring human visual growth.
From texture-following to shape-focused vision
Deep networks trained with this developmental visual diet were compared with the usual high-quality training. Across several model designs and image collections, the new approach produced a much stronger preference for shape, reaching the range seen in human observers while losing little in standard recognition accuracy. When the researchers examined which parts of an image the models relied on, the developmentally trained systems focused on whole-object regions, whereas the standard models fixated on small texture patches or background areas. Further tests showed that the gradual improvement of contrast, more than blur or color alone, played a key role in pushing networks toward using broad object structure instead of scattered local details.
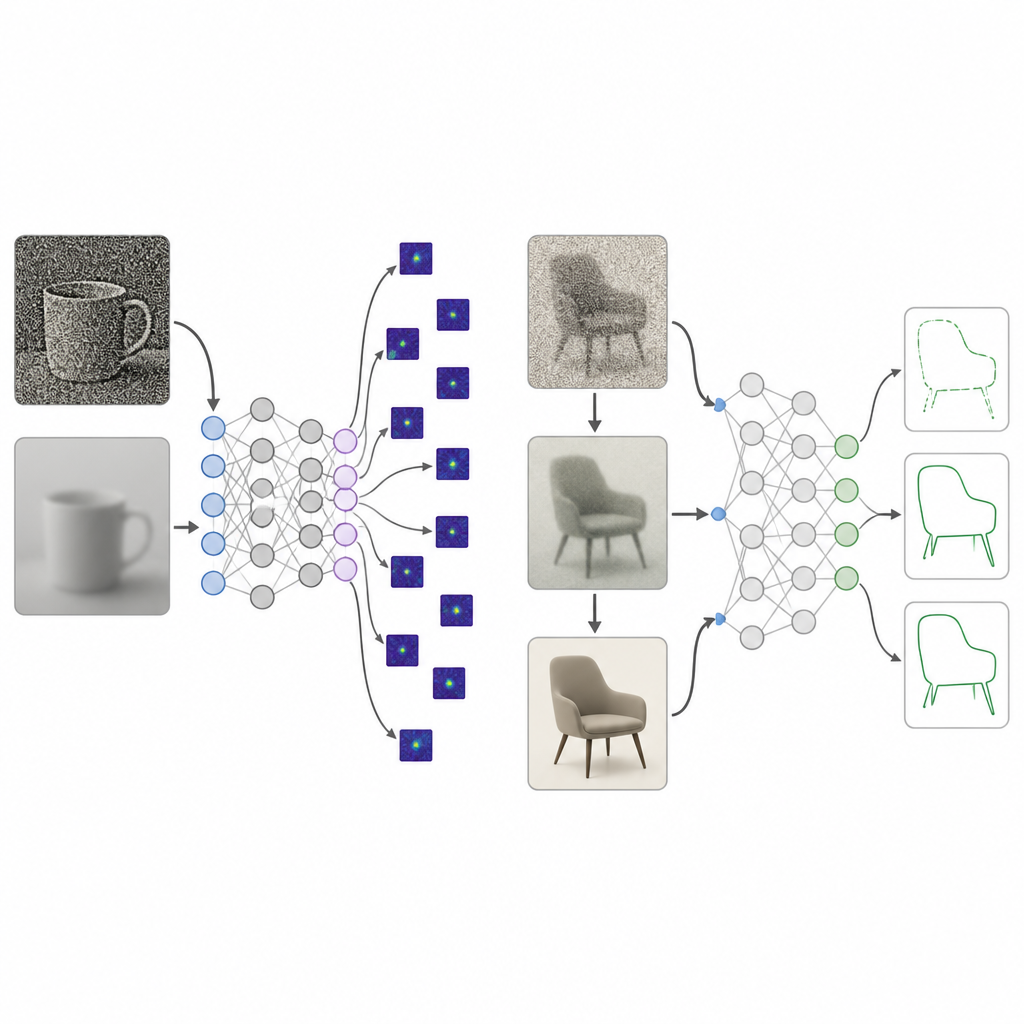
Recognizing hidden shapes and handling messy images
The team next challenged the models with pictures where familiar shapes such as a bicycle or dolphin were subtly woven into complex scenes. People easily spot these contours, but most existing systems, including large vision–language models, mainly respond to the scene’s background. Networks raised on the developmental visual diet were far better at recalling the hidden shapes and less distracted by the scene. They also held up much more gracefully when images were corrupted by blur, noise, bad lighting, or weather-like effects such as rain and snow, often matching human trends. Even against adversarial attacks, where tiny digital changes trick many models, the developmentally trained systems remained substantially more accurate than standard or adversarially trained counterparts.
What this means for safer and more human-like AI
By feeding AI a visual childhood that echoes our own, this work shows that how a model is trained can matter as much as how large it is. A simple, biologically inspired curriculum pushed networks away from brittle texture tricks and toward robust use of shape, improved recognition of abstract forms in clutter, and better resistance to both natural distortions and hostile attacks. For non-specialists, the key message is that starting with “poor” vision and letting it mature can actually help machines learn sturdier, more human-like ways of seeing, offering a more resource-efficient path toward safer visual AI.
Citation: Lu, Z., Thorat, S., Cichy, R.M. et al. Adopting a human developmental visual diet yields robust and shape-based AI vision. Nat Mach Intell 8, 735–748 (2026). https://doi.org/10.1038/s42256-026-01228-6
Keywords: AI vision, visual development, shape bias, robust perception, deep learning