Clear Sky Science · zh
用随机噪声进行类脑热身训练以校准不确定性
为什么更聪明的人工智能需要知道自己何时可能出错
现代人工智能系统在识别图像、驾驶汽车和进行自然语言对话方面表现出令人瞩目的能力。然而,它们常常存在一个危险的盲点:在极度自信时可能完全错误。这种置信度与正确性之间的不匹配可能导致糟糕的医疗决策、不安全的自动驾驶行为或能够让人信服地捏造事实的聊天机器人。题为“用随机噪声进行类脑热身训练以校准不确定性”的论文探讨了一种出人意料的简单且受生物学启发的方法,教会人工智能模型一种重要的人类习惯:在真正不知道时表达不确定性。
当置信与现实渐行渐远
作者首先检查了当今神经网络如何报告置信度。一个在自然图像上训练的分类器不仅预测所见内容,还会给出其答案正确的概率。理想情况下,如果模型说它有80%的置信度,那么它应当约有80%的时间是正确的。研究者表明,实际上,随着网络变得更深并在有限数据上训练,其置信度会被夸大:它们经常对错误答案赋予非常高的确信度。当模型遇到训练中从未见过的图像——即所谓的分布外数据时,这个问题会更糟:模型仍然表现得过于自信,而不是承认不确定性。
借鉴发育中大脑的热身
为了解决这个问题,研究将目光投向生物学。在出生前,动物的大脑已经很活跃,在有意义的视觉和听觉到来之前就产生自发的电活动模式。神经科学家认为,这种早期的“噪声”有助于连接回路,使它们为真实的感觉体验做好准备。受此启发,作者提出了对人工网络进行热身的阶段:在看到任何真实图像或标签之前,模型在完全随机的输入模式与随机、无意义的标签配对上短暂训练。乍看之下,这似乎毫无意义——网络无法从纯噪声中学到有用的东西。然而在这短暂阶段,其内部反应会稳定到一种输出概率均匀分布的状态,表现为纯粹的机会均等而非过度自信。
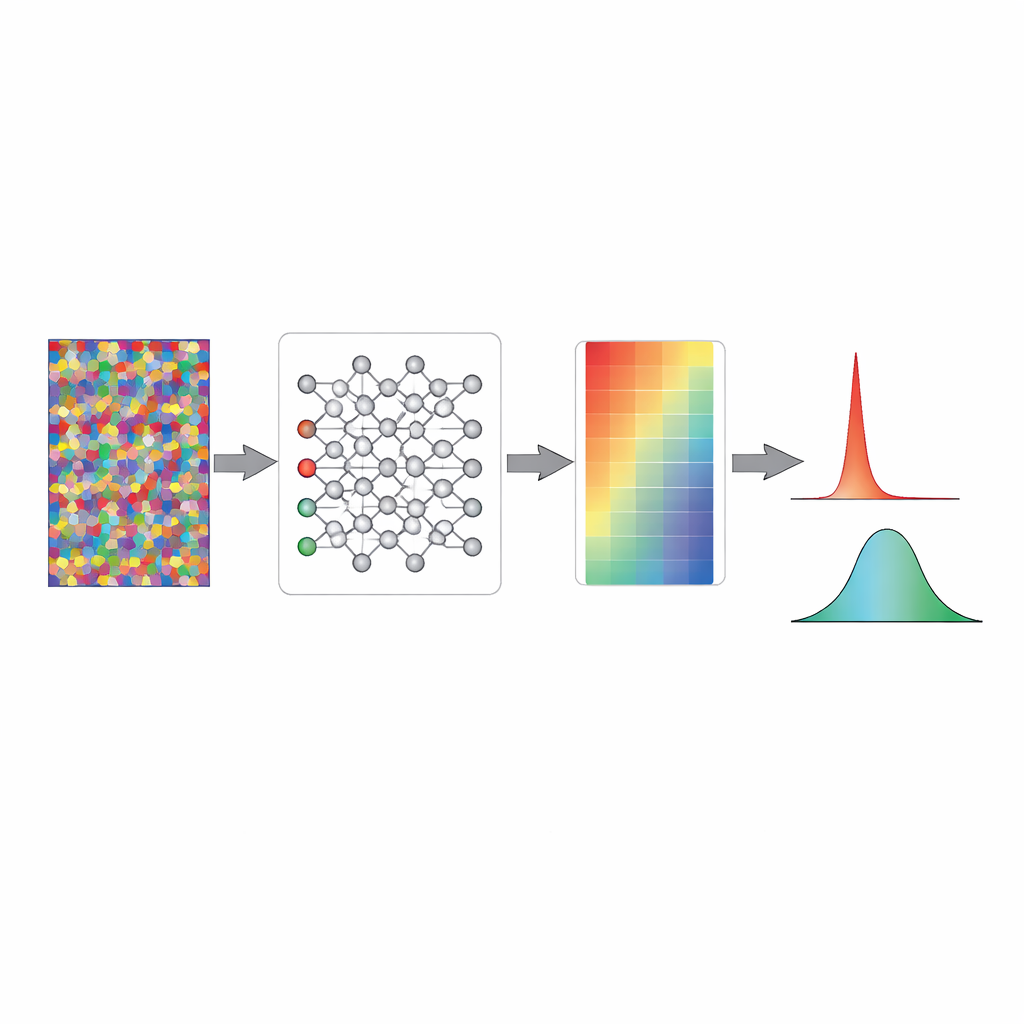
随机噪声如何使置信变得诚实
研究者使用简化的玩具模型和完整的图像分类器展示了这种热身在内部的作用。在一个标准的随机初始化网络中,接近最终决策层的数学信号通常波动很大,softmax 函数会将其转换为接近零或一的极端概率。这意味着未经训练的模型即使一无所知也会表现得像是非常有把握。用随机噪声训练会温和地重新缩放这些内部信号,将它们拉入一个使输出概率聚集在机会水平附近的区间。权重本身几乎不变;相反,是整体活动模式被“预先校准”,使得在真正学习开始之前,模型自然而然地对不熟悉的输入表达出最大的不确定性。
在真实与未知数据上表现更好
一旦完成这种类脑热身,同一网络便使用标准方法在真实图像数据集上训练。无论是简单的前馈网络,还是流行的 ResNet、DenseNet 与视觉 Transformer 架构,经噪声训练的网络在学习过程中置信度与实际准确率之间保持更接近的匹配。它们在标准测试集上的表现与传统初始化的网络相当或略有提升,但其置信分数更加值得信赖。关键是,当展示真正不熟悉的图像时,这些预校准模型会给出接近机会水平的低置信度,而不是自信地错误标记。这一简单特性显著提高了它们检测输入为“未知”的能力——这是在现实环境中安全部署的关键要求。
为更可信的人工智能奠定基础
简单来说,这项研究表明,对随机噪声进行极短且廉价的热身可以从一开始就教会神经网络一种谦逊。模型不再以过度自信的猜测者身份开始,而是处于一种谨慎状态,承认自己不知道,并仅在积累真实证据后才把置信度提高。这种方法避免了额外的后处理步骤,适用于多种模型类型与数据规模,并与生物大脑在出生前似乎如何准备自身相呼应。如果被广泛采用,这种类脑热身训练有助于让人工智能系统不仅更准确,也更恰当地认识自己的局限——这是让它们在日常决策中成为更安全、更可靠伙伴的重要一步。
引用: Cheon, J., Paik, SB. Brain-inspired warm-up training with random noise for uncertainty calibration. Nat Mach Intell 8, 602–613 (2026). https://doi.org/10.1038/s42256-026-01215-x
关键词: 不确定性校准, 神经网络, 随机噪声热身, 分布外检测, 类脑人工智能