Clear Sky Science · it
Allenamento di riscaldamento ispirato al cervello con rumore casuale per la calibrazione dell’incertezza
Perché un’IA più intelligente deve sapere quando potrebbe sbagliare
I moderni sistemi di intelligenza artificiale sono in grado di riconoscere immagini, guidare automobili e conversare in linguaggio naturale con abilità impressionante. Eppure spesso hanno un pericoloso punto cieco: possono sbagliarsi completamente pur essendo estremamente sicuri di sé. Questo disallineamento fra fiducia e correttezza può portare a decisioni mediche sbagliate, comportamenti insicuri nei veicoli autonomi o chatbot che inventano fatti in modo convincente. L’articolo "Brain-inspired warm-up training with random noise for uncertainty calibration" esplora un modo sorprendentemente semplice e ispirato alla biologia per insegnare ai modelli di IA un’abitudine cruciale simile a quella umana: esprimere incertezza quando davvero non sanno.
Quando fiducia e realtà divergono
Gli autori cominciano esaminando come le reti neurali odierne riportano la fiducia. Un classificatore addestrato su immagini naturali non solo predice ciò che vede, ma assegna anche una probabilità che la sua risposta sia corretta. Idealmente, se un modello dice di essere sicuro all’80%, dovrebbe avere ragione circa l’80% delle volte. In pratica, i ricercatori mostrano che man mano che le reti diventano più profonde e sono addestrate su dati limitati, la loro fiducia si gonfia: assegnano frequentemente altissima certezza a risposte sbagliate. Questo problema peggiora ulteriormente quando il modello incontra immagini mai viste durante l’addestramento — una situazione nota come dati out-of-distribution — dove continua ad apparire eccessivamente sicuro invece di ammettere incertezza.
Un riscaldamento preso in prestito dal cervello in sviluppo
Per affrontare il problema, lo studio si ispira alla biologia. Prima della nascita, i cervelli degli animali sono già attivi, producendo schemi spontanei di attività elettrica molto prima che arrivino stimoli sensoriali significativi. I neuroscienziati ritengono che questo precoce “rumore” aiuti a connettere i circuiti in modo che siano pronti per le esperienze sensoriali reali. Ispirandosi a ciò, gli autori propongono una fase di riscaldamento per le reti artificiali: prima di vedere qualsiasi immagine reale o etichetta, il modello viene brevemente addestrato su pattern di input completamente casuali abbinati a etichette casuali e prive di significato. A prima vista sembra inutile — la rete non può imparare nulla di utile dal puro rumore. Eppure durante questa breve fase le sue risposte interne si stabilizzano in uno stato in cui le probabilità in uscita sono distribuite uniformemente, corrispondendo al caso piuttosto che a un’eccessiva fiducia.
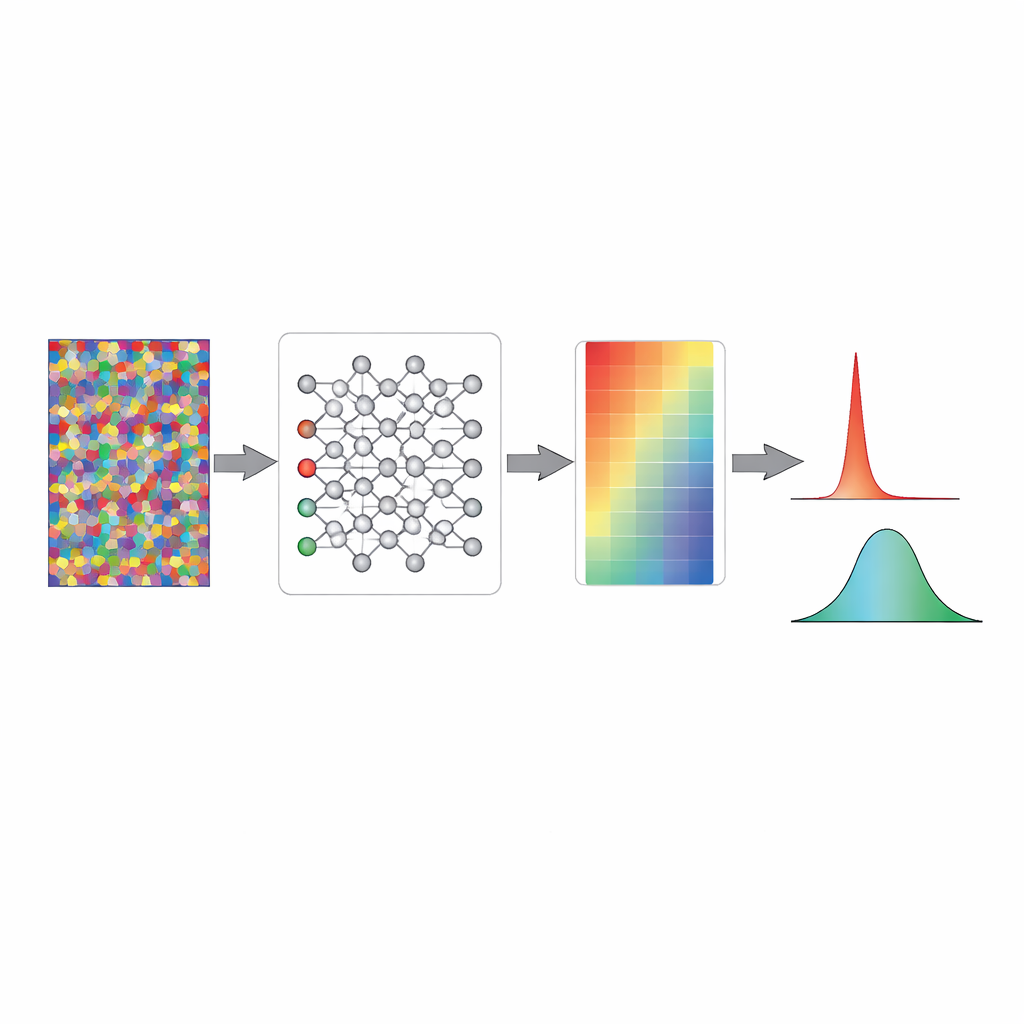
Come il rumore casuale rende la fiducia onesta
Utilizzando modelli giocattolo semplificati e classificatori di immagini completi, i ricercatori mostrano cosa fa questo riscaldamento a livello interno. In una rete standard inizializzata casualmente, i segnali matematici immediatamente prima dello strato decisionale finale spesso oscillano molto, e la funzione softmax li trasforma in probabilità estreme vicine a zero o uno. Ciò significa che un modello non addestrato si comporta già come se fosse molto sicuro, nonostante non sappia nulla. L’addestramento su rumore casuale ridimensiona delicatamente quei segnali interni, portandoli in un intervallo in cui le probabilità in uscita si raggruppano attorno al livello del caso. I pesi stessi cambiano appena; invece, il pattern complessivo di attività viene “pre-calibrato” in modo che, prima che inizi il vero apprendimento, il modello esprima naturalmente massima incertezza su input non familiari.
Migliore comportamento su dati reali e sconosciuti
Completato questo riscaldamento ispirato al cervello, le stesse reti vengono poi addestrate su set di immagini reali con metodi standard. Su molte architetture — dalle semplici reti feed-forward ai popolari modelli ResNet, DenseNet e vision transformer — le reti addestrate con rumore mantengono una corrispondenza più stretta tra fiducia e accuratezza reale durante l’apprendimento. Prestano quanto meno quanto o leggermente meglio rispetto alle reti inizializzate in modo convenzionale sui set di test standard, ma i loro punteggi di fiducia sono molto più affidabili. Crucialmente, quando vengono mostrate immagini veramente non familiari, questi modelli pre-calibrati assegnano bassa fiducia che si aggira vicino al caso, invece di etichettarle con sicurezza. Questa semplice proprietà migliora in modo significativo la loro capacità di rilevare quando un input è “sconosciuto” — un requisito chiave per un dispiegamento sicuro nel mondo reale.
Fondamenti per un’IA più affidabile
In termini semplici, lo studio mostra che un riscaldamento molto breve ed economico su rumore casuale può insegnare alle reti neurali una sorta di umiltà fin dall’inizio. Piuttosto che nascere come indovini eccessivamente fiduciosi, i modelli cominciano in uno stato prudente in cui ammettono di non sapere, e poi aumentano la fiducia solo man mano che accumulano prove reali. Questo approccio evita passaggi di post-elaborazione aggiuntivi, funziona su molti tipi di modelli e dimensioni di dati, e riecheggia il modo in cui i cervelli biologici sembrano prepararsi prima della nascita. Se adottato su larga scala, un tale allenamento di riscaldamento ispirato al cervello potrebbe aiutare i sistemi di IA a diventare non solo accurati, ma anche consapevoli dei propri limiti — un passo essenziale per renderli partner più sicuri e affidabili nelle decisioni quotidiane.
Citazione: Cheon, J., Paik, SB. Brain-inspired warm-up training with random noise for uncertainty calibration. Nat Mach Intell 8, 602–613 (2026). https://doi.org/10.1038/s42256-026-01215-x
Parole chiave: calibrazione dell’incertezza, reti neurali, riscaldamento con rumore casuale, rilevamento out-of-distribution, IA ispirata al cervello