Clear Sky Science · pl
Trening rozgrzewkowy inspirowany mózgiem z losowym szumem dla kalibracji niepewności
Dlaczego mądrzejsza SI musi wiedzieć, kiedy może się mylić
Współczesne systemy sztucznej inteligencji potrafią rozpoznawać obrazy, prowadzić samochody i prowadzić rozmowy w języku naturalnym z imponującą biegłością. Mimo to często mają niebezpieczną słabość: mogą być całkowicie w błędzie, a jednocześnie niezwykle pewne siebie. Ta rozbieżność między pewnością a poprawnością może prowadzić do błędnych decyzji medycznych, niebezpiecznych zachowań autonomicznych pojazdów czy chatbotów, które przekonująco zmyślają fakty. Artykuł „Brain-inspired warm-up training with random noise for uncertainty calibration” bada zaskakująco prosty, biologicznie inspirowany sposób nauczenia modeli AI ważnego, ludzkiego nawyku: wyrażania niepewności, gdy naprawdę nie wiedzą.
Gdy pewność i rzeczywistość się rozjeżdżają
Autorzy zaczynają od analizy tego, jak współczesne sieci neuronowe raportują pewność. Klasyfikator wytrenowany na naturalnych obrazach nie tylko przewiduje, co widzi, ale też podaje prawdopodobieństwo, że jego odpowiedź jest poprawna. Idealnie, jeśli model twierdzi, że ma 80% pewności, powinien mieć rację w około 80% przypadków. W praktyce badacze pokazują, że im głębsze sieci i im uboższe dane treningowe, tym bardziej wyolbrzymiona staje się ich pewność: często przyznają bardzo wysoką pewność błędnym odpowiedziom. Problem pogarsza się jeszcze bardziej, gdy model napotyka obrazy, których nigdy wcześniej nie widział — sytuacja znana jako dane poza dystrybucją — gdzie nadal zachowuje przesadną pewność zamiast przyznać niepewność.
Rozgrzewka zapożyczona z rozwijającego się mózgu
Aby się tym zająć, badanie sięga po biologiczne inspiracje. Przed narodzinami mózgi zwierząt są już aktywne, generując spontaniczne wzorce aktywności elektrycznej na długo przed pojawieniem się znaczących wrażeń wzrokowych czy dźwiękowych. Neurolodzy uważają, że wczesny „szum” pomaga organizować obwody tak, by były gotowe na prawdziwe doświadczenia sensoryczne. Zainspirowani tym autorzy proponują fazę rozgrzewkową dla sztucznych sieci: zanim zobaczą jakiekolwiek prawdziwe obrazy czy etykiety, model jest krótko trenowany na całkowicie losowych wzorcach wejściowych sparowanych z losowymi, pozbawionymi sensu etykietami. Na pierwszy rzut oka wydaje się to bezcelowe — sieć nie może nauczyć się niczego użytecznego z czystego szumu. Jednak w trakcie tej krótkiej fazy wewnętrzne odpowiedzi osadzają się w stanie, w którym rozkład prawdopodobieństw wyjściowych jest równomierny, odpowiadając losowi zamiast nadmiernej pewności.
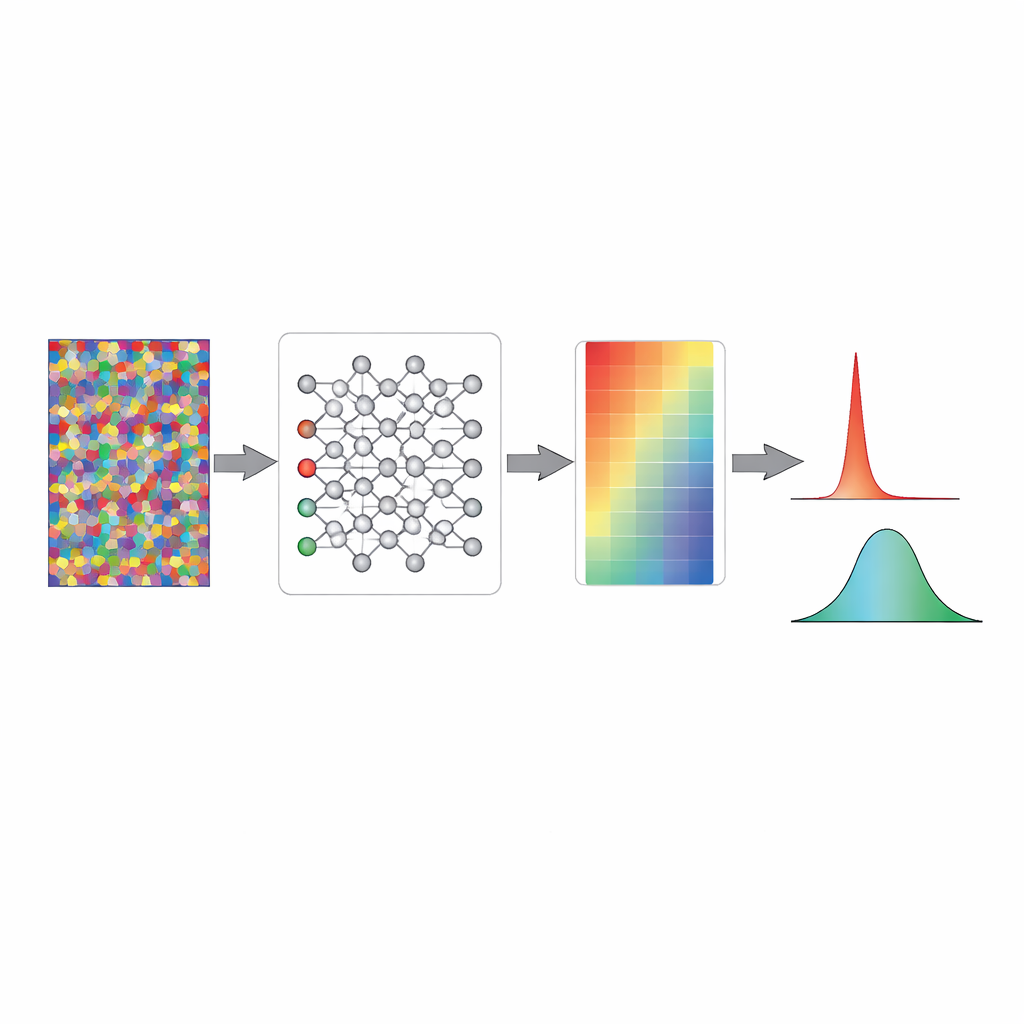
Jak losowy szum uczciwie kształtuje pewność
Używając uproszczonych modeli zabawkowych i pełnych klasyfikatorów obrazów, badacze pokazują, co ta rozgrzewka robi „pod maską”. W standardowo losowo zainicjowanej sieci matematyczne sygnały tuż przed warstwą decyzyjną często mają duże wahania, które funkcja softmax przekształca w skrajne prawdopodobieństwa bliskie zera lub jedynki. Oznacza to, że nieprzetrenowany model już zachowuje się tak, jakby był bardzo pewny, mimo że niczego nie wie. Trening na losowym szumie delikatnie przeskalowuje te wewnętrzne sygnały, przesuwając je do zakresu, w którym prawdopodobieństwa wyjściowe grupują się wokół poziomu losowego trafienia. Same wagi praktycznie się nie zmieniają; zamiast tego ogólny wzorzec aktywności jest „wstępnie skalibrowany”, tak że przed rozpoczęciem rzeczywistego uczenia model naturalnie wyraża maksymalną niepewność wobec nieznanych wejść.
Lepsze zachowanie na danych rzeczywistych i nieznanych
Po zakończeniu tej inspirowanej mózgiem rozgrzewki te same sieci są trenowane na rzeczywistych zbiorach obrazów za pomocą standardowych metod. W wielu architekturach — od prostych sieci jednokierunkowych po popularne ResNet, DenseNet i modele vision transformer — sieci trenowane na szumie utrzymują bliższe dopasowanie pomiędzy pewnością a rzeczywistą dokładnością przez cały proces uczenia. Osiągają wyniki porównywalne lub nieco lepsze niż sieci z konwencjonalną inicjalizacją na standardowych zestawach testowych, ale ich oceny pewności są znacznie bardziej godne zaufania. Co kluczowe, gdy pokazuje się im naprawdę nieznane obrazy, te wstępnie skalibrowane modele przypisują niską pewność oscylującą wokół poziomu losowego, zamiast pewnie je błędnie oznaczać. Ta prosta właściwość znacząco poprawia ich zdolność do wykrywania, kiedy wejście jest „nieznane” — kluczowy wymóg bezpiecznego wdrożenia w rzeczywistym świecie.
Podstawy bardziej godnej zaufania SI
Mówiąc prosto, badanie pokazuje, że bardzo krótka, tania rozgrzewka na losowym szumie może od zaraz nauczyć sieci neuronowe pewnej pokory. Zamiast rozpoczynać życie jako nadmiernie pewni zgadywacze, modele zaczynają w ostrożnym stanie, w którym przyznają, że nie wiedzą, a następnie podnoszą swoją pewność dopiero w miarę gromadzenia prawdziwych dowodów. Podejście to unika dodatkowych kroków postprocessingowych, działa w różnych typach modeli i rozmiarach danych, oraz odzwierciedla sposób, w jaki wydają się przygotowywać się mózgi biologiczne przed narodzinami. Jeśli zostanie szeroko przyjęte, taka inspirowana mózgiem rozgrzewka może sprawić, że systemy AI będą nie tylko dokładniejsze, ale też odpowiednio świadome własnych ograniczeń — istotny krok w kierunku uczynienia ich bezpieczniejszymi i bardziej niezawodnymi partnerami w codziennym podejmowaniu decyzji.
Cytowanie: Cheon, J., Paik, SB. Brain-inspired warm-up training with random noise for uncertainty calibration. Nat Mach Intell 8, 602–613 (2026). https://doi.org/10.1038/s42256-026-01215-x
Słowa kluczowe: kalibracja niepewności, sieci neuronowe, rozgrzewka z losowym szumem, wykrywanie danych poza dystrybucją, Sztuczna inteligencja inspirowana mózgiem