Clear Sky Science · sv
Hjärnlik uppvärmningsträning med slumpmässigt brus för kalibrering av osäkerhet
Varför smartare AI behöver veta när den kan ha fel
Moderna artificiella intelligenssystem kan känna igen bilder, köra bilar och föra samtal på naturligt språk med imponerande skicklighet. Ändå har de ofta en farlig blind fläck: de kan ha helt fel samtidigt som de är extremt säkra på sig själva. Denna mismatch mellan självförtroende och korrekthet kan leda till dåliga medicinska beslut, osäkert beteende hos självkörande fordon eller chattbotar som övertygande hittar på fakta. Artikeln "Brain-inspired warm-up training with random noise for uncertainty calibration" undersöker ett överraskande enkelt, biologiskt inspirerat sätt att lära AI-modeller en avgörande mänsklig vana: att uttrycka osäkerhet när de verkligen inte vet.
När förtroende och verklighet glider isär
Författarna börjar med att granska hur dagens neurala nätverk rapporterar förtroende. En klassificerare som tränats på naturliga bilder förutspår inte bara vad den ser, utan också en sannolikhet för att dess svar är korrekt. I idealfallet, om en modell säger att den är 80 % säker, ska den ha rätt ungefär 80 % av gångerna. I praktiken visar forskarna att när nätverk blir djupare och tränas på begränsade data, blir deras självförtroende uppblåst: de tilldelar ofta mycket hög säkerhet åt felaktiga svar. Problemet förvärras ytterligare när modellen stöter på bilder den aldrig sett under träning — en situation som kallas data utanför fördelningen — där den fortfarande agerar överdrivet säker istället för att erkänna osäkerhet.
En uppvärmning lånad från den utvecklande hjärnan
För att ta itu med detta vänder studien sig till biologin. Före födseln är djurhjärnor redan aktiva och avfyrar spontana mönster av elektrisk aktivitet långt innan meningsfulla syn- och ljudintryck når dem. Neuroforskare tror att detta tidiga "brus" hjälper till att koppla upp kretsar så att de är redo för verklig sensorisk erfarenhet. Inspirerade av detta föreslår författarna en uppvärmningsfas för artificiella nätverk: innan modellen får se några riktiga bilder eller etiketter tränas den kort på helt slumpmässiga indata mönster ihopkopplade med slumpmässiga, meningslösa etiketter. Vid första anblick kan detta verka poänglöst — nätverket kan inte lära sig något användbart från rent brus. Ändå, under denna korta fas, stabiliserar sig dess interna svar till ett tillstånd där utsignalernas sannolikheter fördelas jämnt, motsvarande ren slump snarare än överdrivet självförtroende.
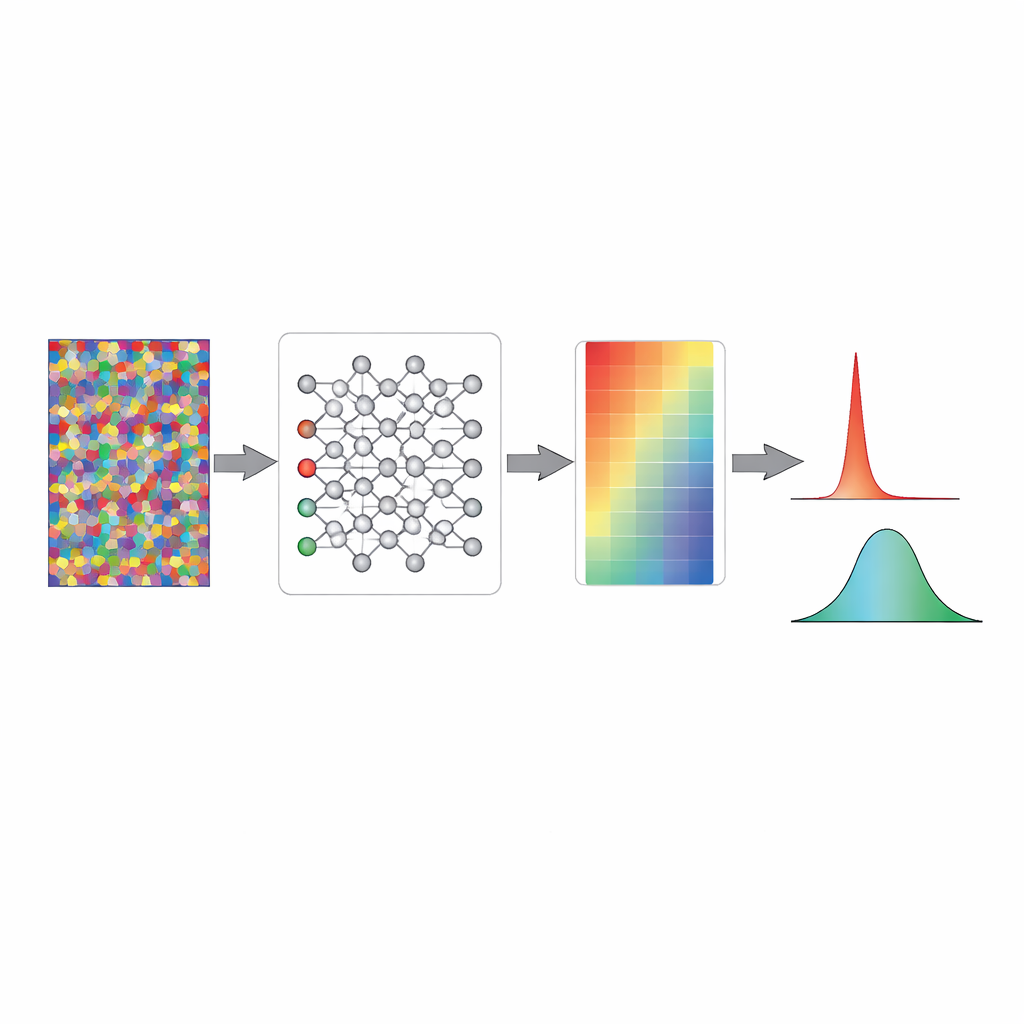
Hur slumpmässigt brus gör förtroendet ärligt
Med hjälp av förenklade leksaksmodeller och fullt utvecklade bildklassificerare visar forskarna vad denna uppvärmning gör under ytan. I ett standardnätverk som initialiserats slumpmässigt tenderar de matematiska signalerna precis före det sista beslutsskiktet att ha stora svängningar, vilka softmax-funktionen omvandlar till extrema sannolikheter nära noll eller ett. Det innebär att en otränad modell redan beter sig som om den är mycket säker, trots att den inte vet något. Träning på slumpmässigt brus omskalär försiktigt dessa interna signaler och drar dem in i ett intervall där utsignalernas sannolikheter klustrar runt slumpnivån. Vikterna förändras knappt; istället blir det övergripande aktivitetsmönstret "prek-alibrerat" så att modellen, innan verkligt lärande börjar, naturligt uttrycker maximal osäkerhet inför obekanta indata.
Bättre beteende på verkliga och okända data
När denna hjärninspirerade uppvärmning är genomförd tränas samma nätverk sedan på riktiga bilddatasätt med standardmetoder. Över många arkitekturer — från enkla framåtriktade nät till populära ResNet-, DenseNet- och vision-transformer-modeller — behåller brus-tränade nätverk en närmare överensstämmelse mellan förtroende och faktisk noggrannhet under hela inlärningen. De presterar lika bra som eller något bättre än konventionellt initialiserade nätverk på standardtestset, men deras förtroendepoäng är mycket mer tillförlitliga. Avgörande är att när de får visa verkligt främmande bilder tilldelar dessa prek-alibrerade modeller låg säkerhet som ligger nära slumpnivån, istället för att självsäkert felmärka dem. Denna enkla egenskap förbättrar dramatiskt deras förmåga att upptäcka när en indatan är "okänd" — en nyckelkrav för säker användning i verkliga miljöer.
Grund för mer trovärdig AI
Enkelt uttryckt visar studien att en mycket kort, billig uppvärmning på slumpmässigt brus kan lära neurala nätverk en slags ödmjukhet från början. Istället för att börja som överdrivet självsäkra gissare börjar modeller i ett försiktigt tillstånd där de medger att de inte vet, och ökar först sitt förtroende när de samlat riktig evidens. Denna metod undviker extra efterbehandlingssteg, fungerar över många modelltyper och datamängder, och speglar hur biologiska hjärnor verkar förbereda sig före födseln. Om den antas i stor skala kan sådan hjärninspirerad uppvärmningsträning hjälpa AI-system att bli inte bara mer precisa, utan också lämpligt medvetna om sina egna gränser — ett viktigt steg mot att göra dem säkrare och mer pålitliga partner i vardagliga beslut.
Citering: Cheon, J., Paik, SB. Brain-inspired warm-up training with random noise for uncertainty calibration. Nat Mach Intell 8, 602–613 (2026). https://doi.org/10.1038/s42256-026-01215-x
Nyckelord: kalibrering av osäkerhet, neurala nätverk, slumpmässig brusuppvärmning, detektion av data utanför fördelningen, hjärninspirerad AI