Clear Sky Science · zh
将视网膜基础模型范式从切片转向体积以用于光学相干断层成像
这对眼健康的重要性
眼部扫描正成为在患者察觉症状之前识别威胁视力疾病的前沿工具。本研究探讨了一种让人工智能(AI)读取我们拥有的最强大眼部扫描之一——光学相干断层成像(OCT)——的新方法:不将其视为单张图像,而是作为完整的类电影三维体积来处理。这一转变被证明能提升AI识别导致失明主要原因的能力,可能把更早期、更可靠的筛查带入全球临床场景。
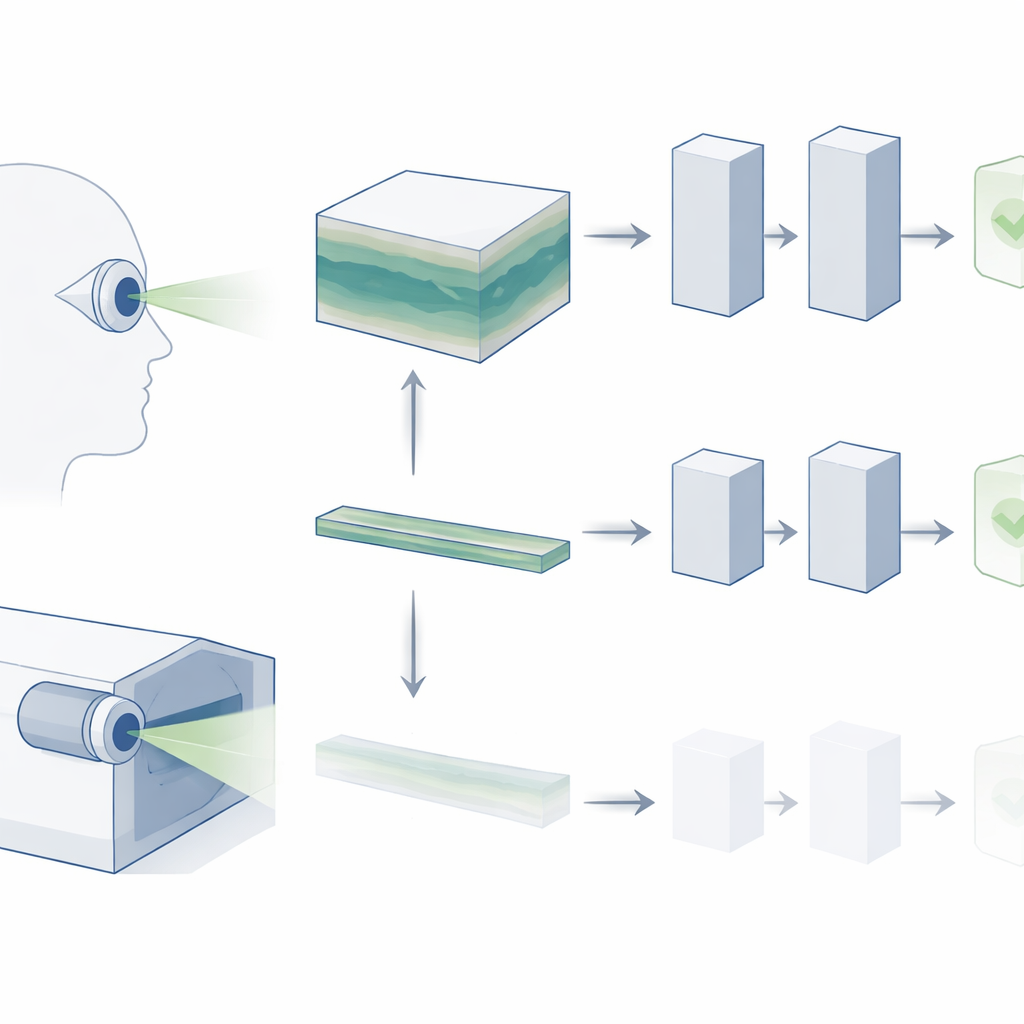
从平面快照到三维视角
OCT生成一个由许多薄横切片构成的视网膜三维块。在日常临床实践中,眼科医生会滚动查看整个体积以寻找疾病迹象,例如年龄相关性黄斑变性(AMD)中的微小沉积物或青光眼中的细微结构变化。然而多数现有的视网膜图像“基础模型”忽略了这种丰富的三维结构。它们通常只查看单张中心切片,假设该切片包含最重要的信息。作者认为,这种捷径丢弃了临床医生实际依赖的大量信息,也可能是AI系统难以满足现实诊断需求的一个原因。
借鉴视频分析的思路
研究人员没有把OCT当作孤立图片,而是将其视为短视频:一系列沿视网膜深度推进的切片。他们采用了一种名为V-JEPA的前沿视频基础模型,该模型最初在日常自然视频上训练,并将其调整用于OCT。与其他现代AI系统类似,V-JEPA先以自监督方式进行训练,学习预测并填补缺失信息,无需标签。这为模型创建了一个强大的通用“视觉词汇”,之后可重复利用。研究者随后在较小的、有标签的OCT数据集上对V-JEPA进行微调,使其能够区分健康眼和病变眼。
跨国家与多疾病的测试
为检验这一三维方法是否真正有益,团队将V-JEPA与三种强大的基于图像的基础模型进行了比较,其中包括两种专门在视网膜图像上训练的模型和一种在自然照片上训练的模型。所有模型使用了相似的底层神经网络架构,因此性能差异主要反映它们如何利用数据,而不是规模或复杂度的不同。模型被要求检测两种主要眼病——视神经性青光眼(青光眼的一种)和AMD——使用来自美国、中国、以色列和伊朗的五个独立OCT数据集,覆盖不同的扫描仪、人口和疾病模式。
来自完整三维信息的更清晰答案
在这些数据集中,基于视频的V-JEPA要么与所有基于图像的模型不相上下,要么表现更好,平均受试者工作特征曲线下面积(AUC)为0.94,而最佳单切片模型为0.90——这一提升具有统计学显著性。优势在一些更具挑战性的数据上最为明显,那里的病变与非病变病例更难区分。模型注意力图的分析显示,V-JEPA关注的是分布在多张切片上的相关结构,而不仅仅是中心切片。错误分析表明,单切片模型常常漏检那些在中间切片缺乏或仅有细微病变但在体积其他位置存在病变的案例。通过有效增加空间覆盖并学习切片间的关联,三维模型能更好地捕捉这些模式。
在性能与可行性之间的平衡
作者还将V-JEPA与其他利用三维信息的方法进行了比较,例如从头训练的经典三维卷积网络以及一种“2.5D”方法——用图像模型逐张处理多张切片再合并结果。V-JEPA总体上优于这些替代方案,同时比2.5D策略所需计算更少。重要的是,即便只有有限的有标签数据可用,其优势仍然存在,且随着训练数据的增加,其性能继续提升,而基于图像的模型往往趋于平台期。虽然分析体积比读取单张切片更慢,但额外处理时间仍很小——在现代硬件上每次扫描大约增加百分之一秒量级(即几十毫秒的数量级)。
对未来眼护的意义
对非专业读者而言,结论很直观:让AI像临床医生那样以三维方式观察视网膜,会带来更准确的常见致盲疾病自动检测。这项工作表明,未来用于眼部影像的“基础模型”应从一开始就被设计为处理完整的OCT体积,而不是单张快照。配合更广泛的数据共享并最终与其他临床信息整合,此类模型有望将一致且高质量的青光眼与黄斑变性筛查带到更多诊所和患者身边。
引用: Judkiewicz, R., Berkowitz, E., Meisel, M. et al. Shifting the retinal foundation models paradigm from slices to volumes for optical coherence tomography. npj Digit. Med. 9, 314 (2026). https://doi.org/10.1038/s41746-026-02496-7
关键词: 光学相干断层成像, 视网膜影像人工智能, 年龄相关性黄斑变性, 青光眼检测, 视频基础模型