Clear Sky Science · pl
Zmiana paradygmatu podstawowych modeli siatkówki: od przekrojów do wolumenów w optycznej koherentnej tomografii
Dlaczego to ma znaczenie dla zdrowia oczu
Badania oczu stają się narzędziem pierwszego kontaktu do wykrywania chorób zagrażających wzrok na długo przed pojawieniem się objawów. W tym badaniu opisano nowe podejście, dzięki któremu sztuczna inteligencja (AI) czyta jedno z najpotężniejszych badań oka — optyczną koherentną tomografię (OCT) — traktując je nie jako pojedyncze zdjęcie, lecz jako pełny, trójwymiarowy wolumen przypominający krótki film. Ta zmiana okazuje się poprawiać zdolność AI do rozpoznawania głównych przyczyn ślepoty, co może umożliwić wcześniejsze i bardziej niezawodne przesiewy w placówkach na całym świecie.
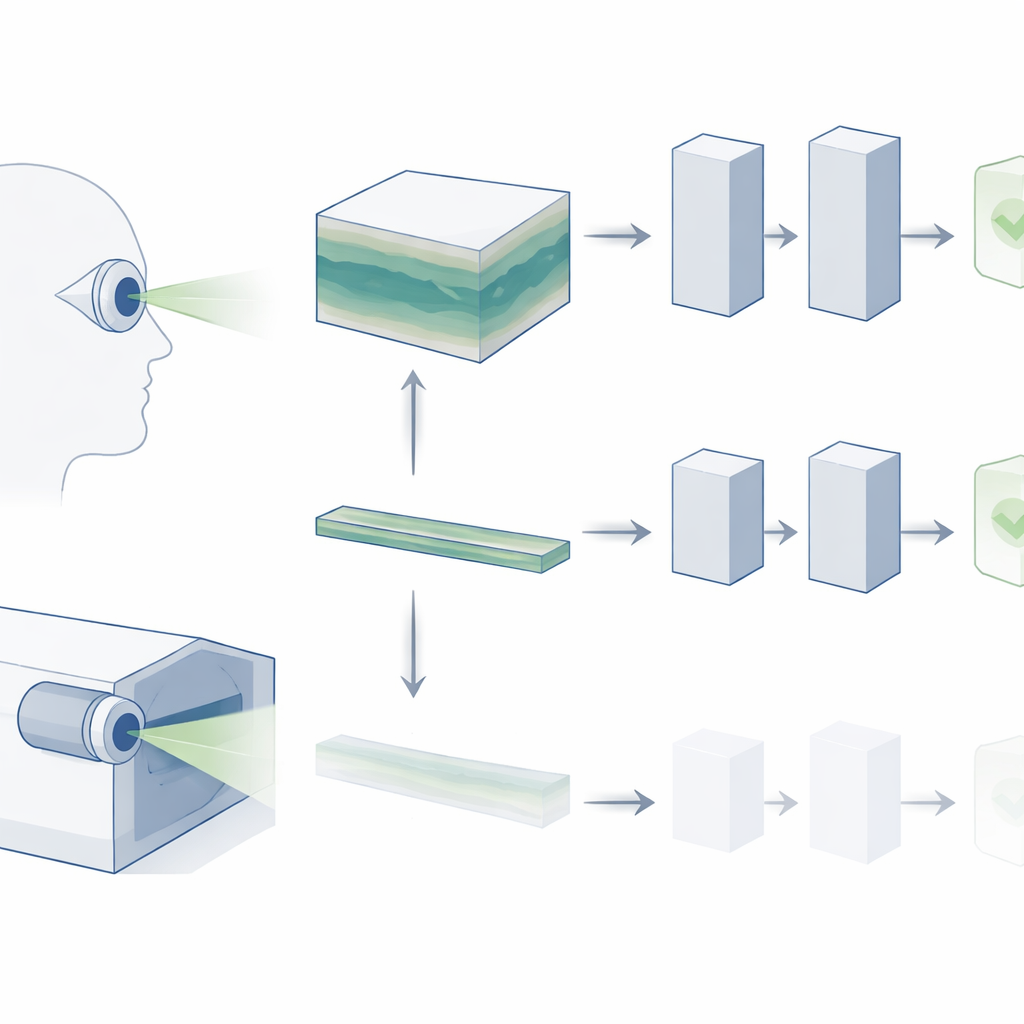
Od płaskich migawków do widoków 3D
OCT tworzy trójwymiarowy blok siatkówki złożony z wielu cienkich przekrojów. W codziennej praktyce klinicznej okulisty przewijają cały ten wolumen, szukając objawów choroby, takich jak drobne złogi w zwyrodnieniu plamki związanego z wiekiem (AMD) czy subtelne zmiany strukturalne w jaskrze. Tymczasem większość istniejących „modeli podstawowych” AI dla obrazów siatkówki pomija tę bogatą strukturę 3D. Zwykle analizują jedynie pojedynczy centralny przekrój, zakładając, że zawiera najważniejsze informacje. Autorzy twierdzą, że takie uproszczenie pozbawia model wielu sygnałów, z których faktycznie korzystają klinicyści, i może być jedną z przyczyn, dla których systemy AI wciąż mają trudności z sprostaniem realnym potrzebom diagnostycznym.
Zap借yczając pomysły z analizy wideo
Zamiast traktować OCT jak pojedyncze zdjęcie, badacze potraktowali je jak krótki film: sekwencję przekrojów przesuwających się przez głębię siatkówki. Zaadaptowali nowoczesny model podstawowy do wideo o nazwie V-JEPA, pierwotnie trenowany na codziennych naturalnych nagraniach, i dostosowali go do OCT. Podobnie jak inne współczesne systemy AI, V-JEPA jest najpierw trenowany w sposób samoucący się, ucząc się przewidywać i uzupełniać brakujące informacje bez potrzeby etykiet. To tworzy potężne, ogólne „wzorcownictwo wizualne”, które model może później ponownie wykorzystać. Następnie badacze dopracowali (fine-tuning) V-JEPA na mniejszych, oznakowanych zbiorach OCT, aby mógł rozróżniać oczy zdrowe od chorych.
Testy w różnych krajach i przy różnych chorobach
Aby sprawdzić, czy podejście 3D naprawdę pomaga, zespół porównał V-JEPA z trzema silnymi modelami opartymi na obrazach, w tym z dwoma trenowanymi specjalnie na obrazach siatkówki oraz jednym trenowanym na fotografiach naturalnych. Wszystkie modele korzystały z podobnych architektur sieci neuronowych, więc różnice w wynikach odzwierciedlają głównie sposób wykorzystania danych, a nie wielkość czy złożoność modelu. Modele miały wykrywać dwie główne choroby oka — neuropatię nerwu wzrokowego związaną z jaskrą (forma jaskry) oraz AMD — używając pięciu niezależnych zbiorów OCT pochodzących ze Stanów Zjednoczonych, Chin, Izraela i Iranu, obejmujących różne skanery, populacje i wzorce chorobowe.
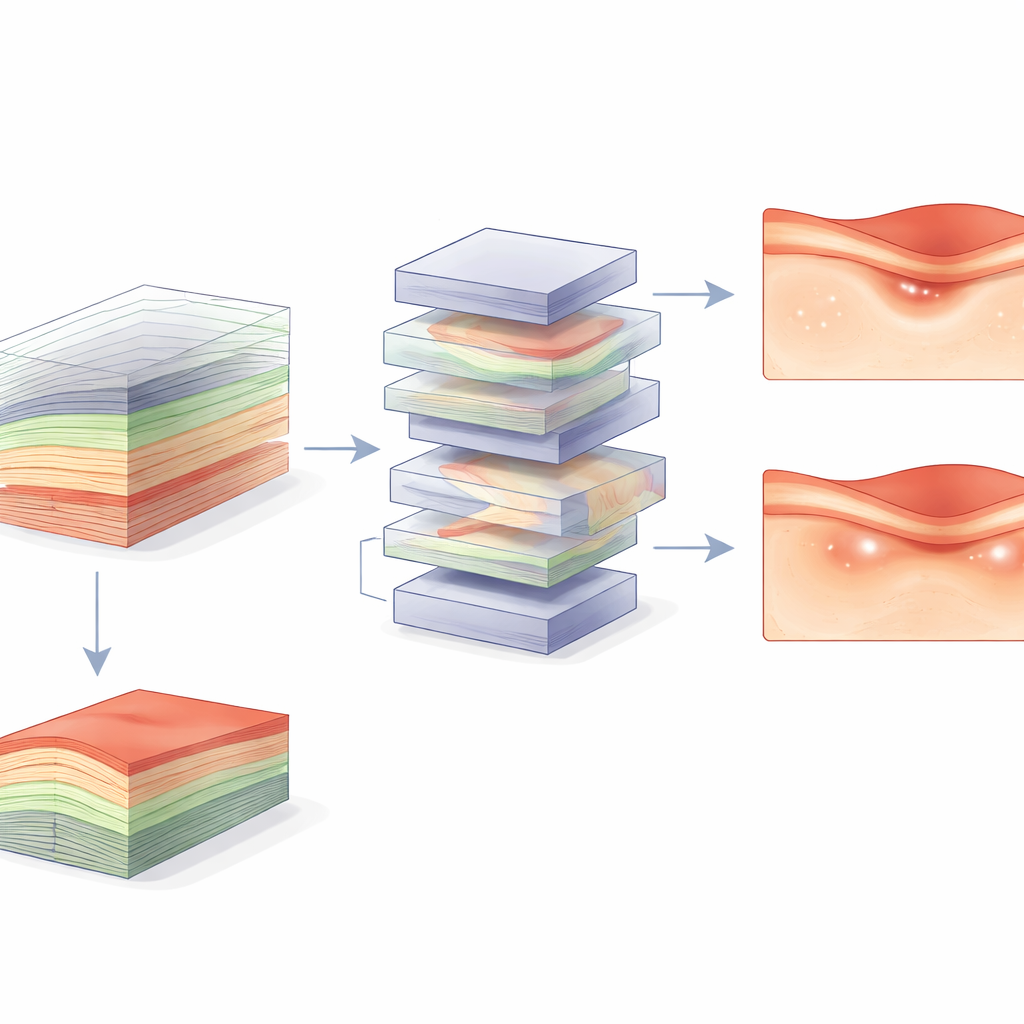
Wyraźniejsze odpowiedzi dzięki pełnym informacjom 3D
W tych zestawach danych model wideo V-JEPA albo dorównywał, albo przewyższał wszystkie modele oparte na obrazach, osiągając średni wynik pola pod krzywą ROC (AUC) równy 0,94 w porównaniu z 0,90 dla najlepszego modelu analizującego pojedynczy przekrój — istotny statystycznie wzrost. Przewaga była największa w niektórych trudniejszych danych, gdzie trudniej było odróżnić przypadki chorobowe od niechorobowych. Analiza map uwagi modelu pokazała, że V-JEPA skupia się na istotnych strukturach rozmieszczonych w wielu przekrojach, nie tylko w centralnym. Analiza błędów ujawniła, że modele pojedynczych przekrojów często pomijały przypadki, w których patologia była nieobecna lub dyskretna w środkowym przekroju, ale występowała w innych częściach wolumenu. Poprzez efektywne zwiększenie pokrycia przestrzennego i naukę relacji między przekrojami, model 3D lepiej wychwytywał takie wzorce.
Równoważenie wydajności i praktyczności
Autorzy porównali V-JEPA także z innymi sposobami wykorzystania informacji 3D, takimi jak klasyczne trójwymiarowe sieci konwolucyjne trenowane od zera oraz metoda „2,5D”, która przetwarza wiele przekrojów pojedynczo za pomocą modelu obrazowego, a następnie łączy wyniki. V-JEPA z reguły przewyższał te alternatywy, wymagając przy tym mniej obliczeń niż strategia 2,5D. Co ważne, jego korzyści utrzymywały się nawet przy umiarkowanej liczbie oznakowanych danych, a wydajność nadal poprawiała się wraz ze wzrostem danych treningowych, podczas gdy modele oparte na obrazach miały tendencję do osiągania plateau. Chociaż analiza wolumenów jest wolniejsza niż odczyt pojedynczego przekroju, dodatkowy czas przetwarzania pozostawał niewielki — rzędu setnych sekundy na skan na nowoczesnym sprzęcie.
Co to oznacza dla przyszłej opieki okulistycznej
Dla osób niebędących specjalistami wniosek jest prosty: pozwolenie AI na oglądanie siatkówki w 3D, tak jak robią to klinicyści, prowadzi do dokładniejszego automatycznego wykrywania powszechnych chorób powodujących ślepotę. Praca ta sugeruje, że przyszłe „modele podstawowe” do obrazowania oka powinny być projektowane od początku z myślą o obsłudze pełnych wolumenów OCT, a nie pojedynczych migawkach. W połączeniu z szerszym udostępnianiem danych i, ostatecznie, integracją z innymi informacjami klinicznymi, takie modele mogą pomóc w zapewnieniu spójnych, wysokiej jakości badań przesiewowych w kierunku jaskry i zwyrodnienia plamki w większej liczbie klinik i dla większej liczby pacjentów na świecie.
Cytowanie: Judkiewicz, R., Berkowitz, E., Meisel, M. et al. Shifting the retinal foundation models paradigm from slices to volumes for optical coherence tomography. npj Digit. Med. 9, 314 (2026). https://doi.org/10.1038/s41746-026-02496-7
Słowa kluczowe: optyczna koherentna tomografia, sztuczna inteligencja w obrazowaniu siatkówki, zwyrodnienie plamki związane z wiekiem, wykrywanie jaskry, podstawowe modele wideo