Clear Sky Science · sv
Skiftet inom retinala foundation-modeller från skivor till volymer för optisk koherenstomografi
Varför detta spelar roll för ögonhälsan
Ögonskanningar blir ett förstahandsverktyg för att upptäcka synhotande sjukdomar långt innan en person märker symtom. Denna studie undersöker ett nytt sätt för artificiell intelligens (AI) att tolka en av de mest kraftfulla ögonskanningarna vi har—optisk koherenstomografi (OCT)—genom att behandla den inte som en enstaka bild utan som en full 3D-volym lik en kort film. Denna förändring visar sig göra AI bättre på att känna igen huvudorsaker till blindhet, vilket potentiellt kan ge tidigare och mer pålitlig screening i kliniker världen över.
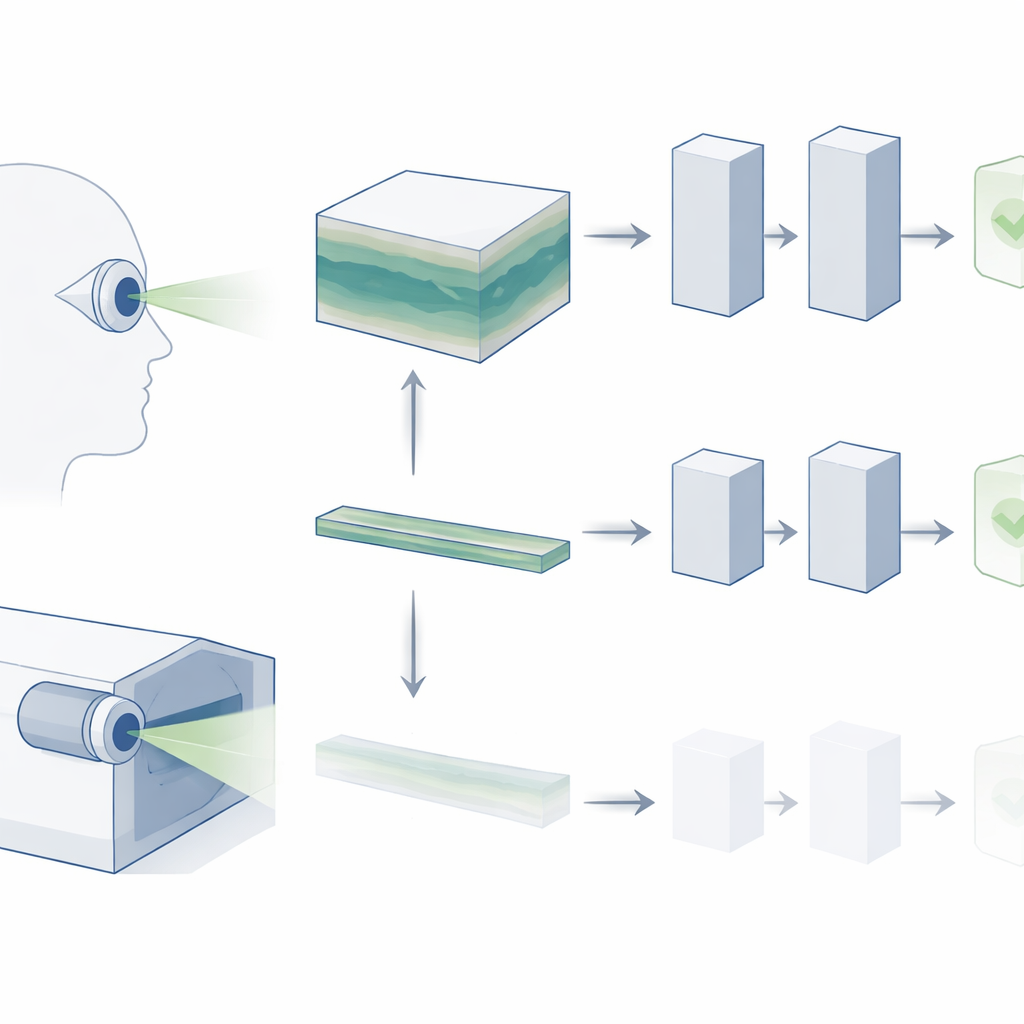
Från platta ögonblicksbilder till 3D-vyer
OCT skapar en tredimensionell blockbild av näthinnan, uppbyggd av många tunna tvärsnittsskivor. I klinisk rutin bläddrar ögonläkare igenom hela denna volym för att leta efter tecken på sjukdom, såsom små avlagringar vid åldersrelaterad makuladegeneration (AMD) eller subtila strukturella förändringar vid glaukom. Ändå bortser de flesta befintliga AI "foundation-modeller" för retinala bilder från denna rika 3D-struktur. De tittar vanligtvis bara på en enskild central skiva, utgående från antagandet att den innehåller den viktigaste informationen. Författarna menar att denna förenkling kastar bort mycket av det som kliniker faktiskt använder och kan vara en orsak till att AI-system fortfarande har svårt att motsvara verkliga diagnostiska behov.
Lånar idéer från videoanalys
I stället för att behandla OCT som en ensam bild, betraktar forskarna den som om det vore en kort video: en sekvens av skivor som går genom näthinnans djup. De använder en avancerad videobaserad foundation-modell kallad V-JEPA, ursprungligen tränad på vardagliga naturliga videor, och anpassar den till OCT. Liksom andra moderna AI-system tränas V-JEPA först självövervakat, där den lär sig förutsäga och fylla i saknad information utan etiketter. Detta skapar ett kraftfullt generellt "visuellt vokabulär" som modellen senare kan återanvända. Forskarna finjusterar sedan V-JEPA på mindre, etiketterade OCT-datasets så att den kan skilja på friska och sjuka ögon.
Testning över länder och sjukdomar
För att avgöra om detta 3D-tänk verkligen hjälper, jämförde teamet V-JEPA med tre starka bildbaserade foundation-modeller, inklusive två tränade specifikt på retinala bilder och en tränad på naturliga fotografier. Alla modeller använde liknande underliggande neurala nätverksarkitekturer, så skillnader i prestanda speglar främst hur de använder datan, inte hur stora eller komplexa de är. Modellerna ombads upptäcka två stora ögonsjukdomar—glaukomatös optisk neuropati (en form av glaukom) och AMD—med hjälp av fem oberoende OCT-datasets insamlade i USA, Kina, Israel och Iran, som täcker olika skannrar, populationer och sjukdomsmönster.
Tydligare svar från full 3D-information
Över dessa datasets matchade eller överträffade den videobaserade V-JEPA alla bildbaserade modeller och uppnådde ett genomsnittligt area under ROC-kurvan på 0,94 jämfört med 0,90 för den bästa enkelskivemodellen—en statistiskt signifikant förbättring. Fördelen var störst för vissa av de mer utmanande data där det var svårare att skilja sjukdomsfall från icke-sjukdomsfall. Analys av modellens uppmärksamhetskartor visade att V-JEPA fokuserar på relevanta strukturer spridda över flera skivor, inte bara den centrala. Felanalys visade att enkelskivemodeller ofta missade fall där patologi saknades eller var subtil i mittskivan men fanns någon annanstans i volymen. Genom att effektivt öka det spatiala omfånget och lära sig hur skivorna relaterar till varandra kunde 3D-modellen bättre fånga dessa mönster.
Balansering av prestanda och praktikalitet
Författarna jämförde också V-JEPA med andra sätt att använda 3D-information, såsom klassiska tredimensionella konvolutionsnät tränade från början och en "2,5D"-metod som bearbetar många skivor en och en med en bildmodell för att sedan kombinera resultaten. V-JEPA presterade generellt bättre än dessa alternativ samtidigt som den krävde mindre beräkningsresurser än 2,5D-strategin. Viktigt är att dess fördelar höll i sig även när endast måttliga mängder etiketterad data fanns tillgängliga, och dess prestanda fortsatte att förbättras när träningsdatan ökade, medan bildbaserade modeller tenderade att nå en platå. Även om volymsanalys är långsammare än att läsa en enskild skiva, förblev den extra bearbetningstiden liten—i storleksordningen hundradelar av en sekund per skanning på modern hårdvara.
Vad detta betyder för framtidens ögonvård
För icke-specialister är slutsatsen enkel: att låta AI se näthinnan i 3D, på samma sätt som kliniker gör, leder till mer exakt automatisk upptäckt av vanliga blindinga sjukdomar. Detta arbete tyder på att framtida "foundation-modeller" för ögonbildtagning bör utformas från start för att hantera fullständiga OCT-volymer, inte bara individuella ögonblicksbilder. I kombination med bredare datadelning och, så småningom, integration med annan klinisk information, skulle sådana modeller kunna bidra till att erbjuda konsekvent, högkvalitativ screening för glaukom och makuladegeneration till många fler kliniker och patienter världen över.
Citering: Judkiewicz, R., Berkowitz, E., Meisel, M. et al. Shifting the retinal foundation models paradigm from slices to volumes for optical coherence tomography. npj Digit. Med. 9, 314 (2026). https://doi.org/10.1038/s41746-026-02496-7
Nyckelord: optisk koherenstomografi, retinal bildbehandlings-AI, åldersrelaterad makuladegeneration, glaukomdetektion, videobaserade foundation-modeller