Clear Sky Science · ru
Сдвиг парадигмы фундаментальных моделей сетчатки: от срезов к объёмам для оптической когерентной томографии
Почему это важно для здоровья глаз
Сканирования глаза становятся одним из основных инструментов для выявления заболеваний, угрожающих зрению, задолго до появления симптомов. В этом исследовании предлагается новый способ для искусственного интеллекта (ИИ) «читать» один из самых информативных типов снимков глаза — оптическую когерентную томографию (ОКТ) — рассматривая её не как одно изображение, а как полноценный трёхмерный объём, похожий на короткий фильм. Этот подход повышает способность ИИ распознавать основные причины слепоты и может обеспечить более ранний и надёжный скрининг в клиниках по всему миру.
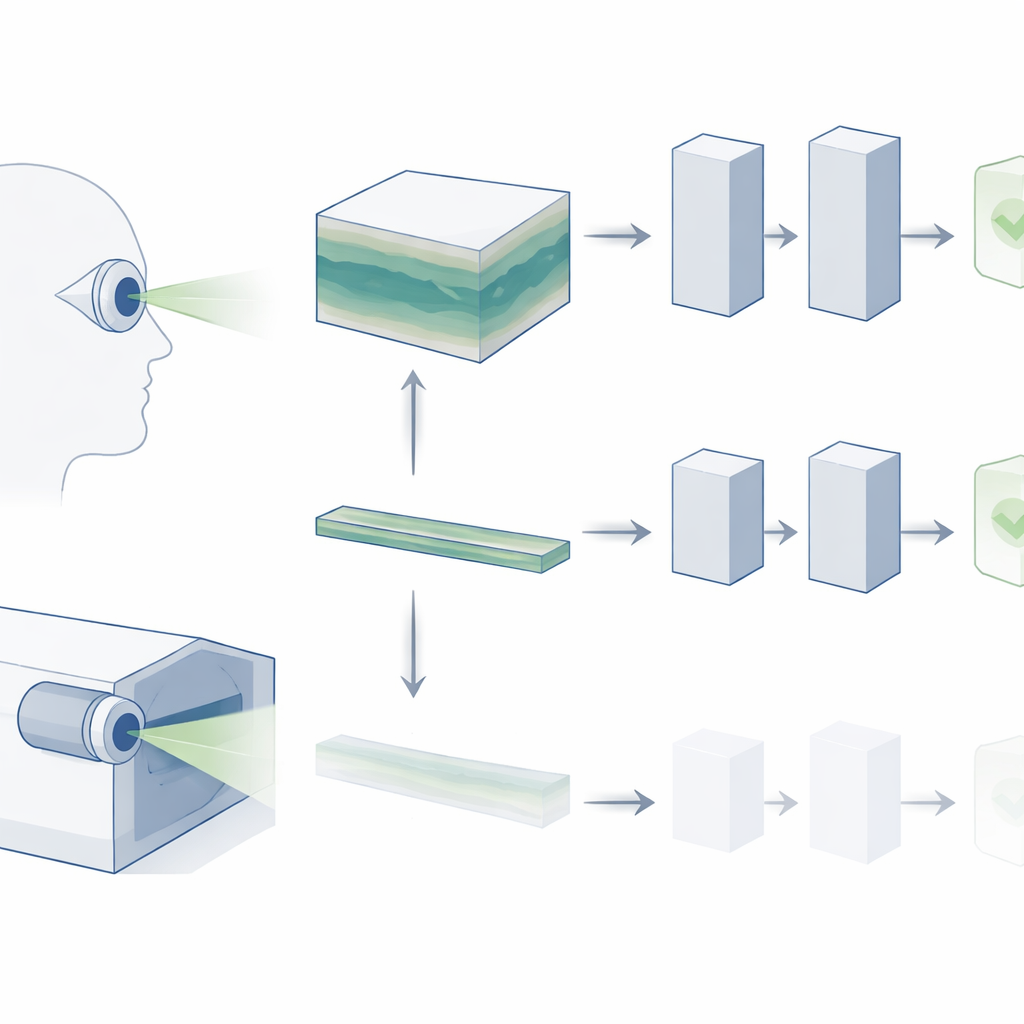
От плоских снимков к 3D-обзору
ОКТ формирует трёхмерный блок сетчатки, собранный из множества тонких поперечных срезов. В повседневной клинической практике офтальмологи прокручивают весь этот объём в поисках признаков заболевания — например, мелких отложений при возрастной макулярной дегенерации (ВМД) или тонких структурных изменений при глаукоме. Однако большинство существующих «фундаментальных моделей» для ретинальных изображений игнорируют этот богатый 3D-контекст. Обычно они анализируют только один центральный срез, предполагая, что он содержит всю ключевую информацию. Авторы утверждают, что такой упрощённый подход выбрасывает большую часть того, чем действительно пользуются клиницисты, и может быть одной из причин, почему ИИ-системы ещё не полностью соответствуют реальным диагностическим потребностям.
Заём идей из анализа видео
Вместо того чтобы рассматривать ОКТ как одиночное изображение, исследователи трактуют её как короткое видео: последовательность срезов, меняющихся по глубине сетчатки. Они используют современную видео-фундаментальную модель V-JEPA, изначально обученную на обычных природных видео, и адаптируют её под ОКТ. Как и другие современные ИИ-системы, V-JEPA сначала обучается в режиме самоконтроля, предсказывая и восстанавливая недостающую информацию без меток. Это создаёт мощный общий «визуальный словарь», который модель затем может переиспользовать. После этого V-JEPA дообучают на меньших размеченных наборах ОКТ, чтобы она научилась различать здоровые и поражённые глаза.
Тестирование в разных странах и при разных заболеваниях
Чтобы проверить, действительно ли помогает 3D-подход, команда сравнила V-JEPA с тремя сильными моделями, ориентированными на изображения, включая две, специально обученные на ретинальных снимках, и одну, обученную на естественных фотографиях. Все модели использовали схожие базовые архитектуры нейросетей, поэтому различия в эффективности в основном отражают то, как они используют данные, а не их размер или сложность. Моделям предлагалось обнаруживать два основных заболевания глаза — глаукоматозную оптическую нейропатию (форма глаукомы) и ВМД — на пяти независимых наборах ОКТ, собранных в США, Китае, Израиле и Иране, с разными томографами, популяциями и паттернами заболеваний.
Более точные ответы благодаря полному 3D
По всем наборам данных видеоподход V-JEPA либо соответствовал, либо превосходил все модели, основанные на отдельных изображениях, достигая среднего значения площади под ROC-кривой 0,94 против 0,90 у лучшей модели, работающей с отдельным срезом — статистически значимое улучшение. Наибольшее преимущество наблюдалось на наиболее сложных данных, где различить заболевания и их отсутствие было труднее. Анализ карт внимания показал, что V-JEPA фокусируется на релевантных структурах, распределённых по нескольким срезам, а не только на центральном. Анализ ошибок выявил, что модели, работающие с одним срезом, часто пропускают случаи, когда патология отсутствует или слабо выражена в среднем срезе, но присутствует в других частях объёма. За счёт расширенного охвата пространства и обучения взаимосвязям между срезами 3D-модель лучше улавливает такие паттерны.
Баланс между эффективностью и практичностью
Авторы также сравнили V-JEPA с другими способами использования 3D-информации: классическими трёхмерными сверточными сетями, обученными с нуля, и «2.5D»-методом, который обрабатывает множество срезов по одному с помощью 2D-модели, а затем объединяет результаты. V-JEPA в целом превосходила эти альтернативы и при этом требовала меньше вычислительных ресурсов, чем стратегия 2.5D. Существенно, что преимущества сохранялись даже при наличии лишь скромного объёма размеченных данных, и производительность продолжала улучшаться по мере роста обучающей выборки, тогда как модели, основанные на отдельных изображениях, как правило, выходили на плато. Хотя анализ объёмов медленнее, чем чтение одного среза, дополнительное время обработки оставалось небольшим — порядка сотых долей секунды на скан при современном оборудовании.
Что это значит для будущей офтальмологии
Для неспециалистов вывод прост: позволив ИИ видеть сетчатку в 3D, так же как это делают клиницисты, можно получить более точное автоматизированное обнаружение распространённых слепящих заболеваний. Работа указывает, что будущие «фундаментальные модели» для офтальмологической визуализации следует проектировать изначально с учётом полноты ОКТ-томограмм, а не отдельных снимков. В сочетании с расширением обмена данными и, в перспективе, интеграцией с другой клинической информацией такие модели могут помочь обеспечить последовательный и качественный скрининг глаукомы и макулярной дегенерации во многих клиниках и для большего числа пациентов во всём мире.
Цитирование: Judkiewicz, R., Berkowitz, E., Meisel, M. et al. Shifting the retinal foundation models paradigm from slices to volumes for optical coherence tomography. npj Digit. Med. 9, 314 (2026). https://doi.org/10.1038/s41746-026-02496-7
Ключевые слова: оптическая когерентная томография, ИИ в ретинальной визуализации, возрастная макулярная дегенерация, обнаружение глаукомы, фундаментальные модели для видео