Clear Sky Science · de
Das Paradigma retinaler Foundation-Modelle von Schnitten zu Volumen für die optische Kohärenztomographie verschieben
Warum das für die Augengesundheit wichtig ist
Augenscans werden zunehmend zu einem wichtigen Instrument, um sehbedrohende Erkrankungen lange vor Auftreten von Symptomen zu erkennen. Diese Studie untersucht einen neuen Ansatz, wie künstliche Intelligenz (KI) eine der leistungsfähigsten bildgebenden Verfahren des Auges — die optische Kohärenztomographie (OCT) — analysieren kann: nicht als einzelnes Bild, sondern als vollständiges 3D-Volumen, ähnlich einem kurzen Film. Dieser Wechsel verbessert offenbar die Fähigkeit der KI, die wichtigsten Erblindungsursachen zu erkennen, und könnte frühere und verlässlichere Screening‑Möglichkeiten in Kliniken weltweit ermöglichen.
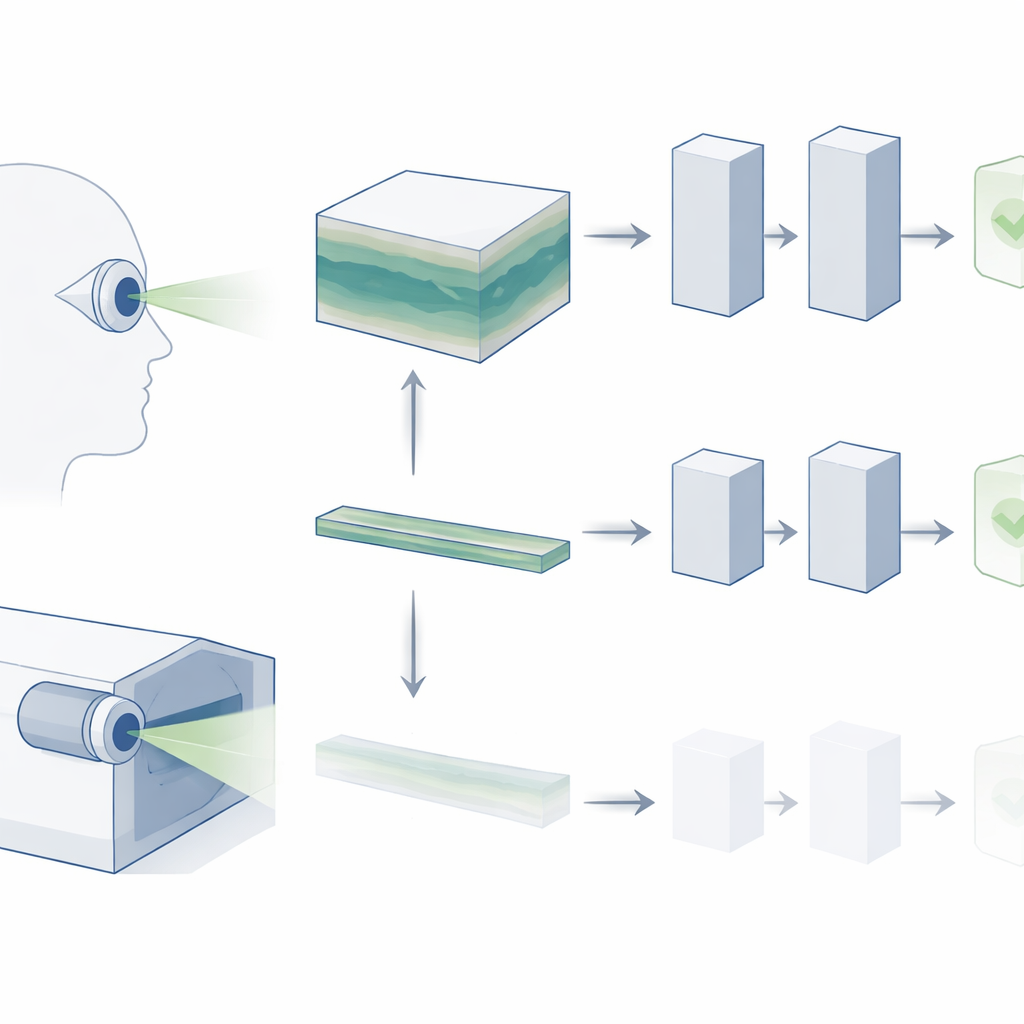
Von flachen Schnappschüssen zu 3D‑Ansichten
OCT erzeugt einen dreidimensionalen Block der Netzhaut, zusammengesetzt aus vielen dünnen Querschnittsschnitten. In der klinischen Praxis scrollen Augenärzte durch dieses gesamte Volumen, um Anzeichen von Erkrankungen zu finden — etwa kleine Ablagerungen bei der altersbedingten Makuladegeneration (AMD) oder subtile strukturelle Veränderungen beim Glaukom. Die meisten vorhandenen KI‑„Foundation‑Modelle“ für retinale Bilder vernachlässigen jedoch diese reichhaltige 3D‑Struktur. Sie betrachten meist nur einen einzelnen zentralen Schnitt, in der Annahme, dass er die wichtigsten Informationen enthält. Die Autoren argumentieren, dass dieser Vereinfachung vieles verloren geht, was Kliniker tatsächlich nutzen, und dass dies ein Grund dafür sein könnte, warum KI‑Systeme noch Schwierigkeiten haben, den Anforderungen der realen Diagnostik gerecht zu werden.
Gegenideen aus der Videoanalyse entleihen
Anstatt OCT als einzelnes Bild zu behandeln, sehen die Forschenden es wie ein kurzes Video: eine Abfolge von Schnitten, die sich durch die Tiefe der Netzhaut ziehen. Sie verwenden ein modernes Video‑Foundation‑Modell namens V‑JEPA, das ursprünglich auf alltäglichen Naturvideos trainiert wurde, und passen es an OCT an. Wie bei anderen modernen KI‑Systemen wird V‑JEPA zunächst selbstüberwacht trainiert, also ohne Labels, indem es fehlende Informationen vorhersagt und ergänzt. Dadurch entsteht ein leistungsfähiges allgemeines „visuelles Vokabular“, das das Modell später wiederverwenden kann. Anschließend feintunen die Forschenden V‑JEPA auf kleineren, beschrifteten OCT‑Datensätzen, damit es gesunde von erkrankten Augen unterscheiden kann.
Tests über Länder und Erkrankungen hinweg
Um zu prüfen, ob dieser 3D‑Ansatz tatsächlich hilft, verglich das Team V‑JEPA mit drei starken bildbasierten Foundation‑Modellen, darunter zwei, die speziell auf retinalen Bildern trainiert wurden, und einem, das auf Naturfotografien trainiert wurde. Alle Modelle nutzten ähnliche zugrunde liegende neuronale Netzarchitekturen, sodass Leistungsunterschiede hauptsächlich widerspiegeln, wie die Daten genutzt werden, nicht wie groß oder komplex die Modelle sind. Die Modelle sollten zwei wichtige Augenerkrankungen erkennen — glaukomatöse optische Neuropathie (eine Form des Glaukoms) und AMD — anhand von fünf unabhängigen OCT‑Datensätzen aus den USA, China, Israel und Iran, die unterschiedliche Scanner, Populationen und Krankheitsmuster abdecken.
Klarere Ergebnisse dank vollständiger 3D‑Informationen
Über diese Datensätze hinweg erreichte das videobasierte V‑JEPA durchweg gleich gute oder bessere Ergebnisse als alle bildbasierten Modelle und erzielte einen durchschnittlichen Flächeninhalt unter der ROC‑Kurve von 0,94 im Vergleich zu 0,90 für das beste Single‑Slice‑Modell — ein statistisch signifikanter Gewinn. Der Vorteil war am größten bei einigen der schwierigeren Datensätze, in denen sich Krankheits‑ und Nicht‑Krankheitsfälle schwerer unterscheiden ließen. Analysen der Aufmerksamkeitskarten des Modells zeigten, dass V‑JEPA relevante Strukturen über mehrere Schnitte hinweg fokussiert, nicht nur auf den zentralen Schnitt. Fehleranalysen ergaben, dass Single‑Slice‑Modelle häufig Fälle übersahen, in denen Pathologie im mittleren Schnitt fehlte oder nur subtil war, aber an anderer Stelle im Volumen vorhanden war. Indem das 3D‑Modell die räumliche Abdeckung effektiv erhöht und lernt, wie Schnitte zueinander in Beziehung stehen, kann es diese Muster besser erfassen.
Leistung und Praktikabilität in Balance
Die Autoren verglichen V‑JEPA außerdem mit anderen Wegen, 3D‑Informationen zu nutzen, wie klassischen dreidimensionalen Faltungsnetzwerken, die von Grund auf trainiert wurden, und einer „2,5D“‑Methode, die viele Schnitte einzeln mit einem Bildmodell verarbeitet und die Ergebnisse anschließend kombiniert. V‑JEPA übertraf diese Alternativen in der Regel, während es weniger Rechenaufwand benötigte als die 2,5D‑Strategie. Wichtig ist, dass seine Vorteile selbst bei nur moderaten Mengen beschrifteter Daten erhalten blieben und die Leistung mit zunehmenden Trainingsdaten weiter stieg, während bildbasierte Modelle dazu neigten, zu stagnieren. Obwohl die Analyse von Volumen langsamer ist als das Lesen eines einzelnen Schnitts, blieb die zusätzliche Verarbeitungszeit gering — im Bereich von Hundertstelsekunden pro Scan auf moderner Hardware.
Was das für die zukünftige Augenversorgung bedeutet
Für Nicht‑Spezialisten ist die Schlussfolgerung klar: Wenn KI die Netzhaut in 3D sieht, wie es Kliniker tun, führt das zu genaueren automatischen Erkennungen häufiger erblindender Erkrankungen. Diese Arbeit legt nahe, dass künftige "Foundation‑Modelle" für die Augenbildgebung von Anfang an so entworfen sein sollten, dass sie vollständige OCT‑Volumen verarbeiten, nicht nur einzelne Schnappschüsse. In Verbindung mit weitergehender Datenfreigabe und schließlich der Integration mit anderen klinischen Informationen könnten solche Modelle dabei helfen, ein konsistentes, hochwertiges Screening auf Glaukom und Makuladegeneration in viele weitere Kliniken und für zahlreiche Patienten weltweit zu bringen.
Zitation: Judkiewicz, R., Berkowitz, E., Meisel, M. et al. Shifting the retinal foundation models paradigm from slices to volumes for optical coherence tomography. npj Digit. Med. 9, 314 (2026). https://doi.org/10.1038/s41746-026-02496-7
Schlüsselwörter: optische Kohärenztomographie, retinale Bildgebung KI, altersbedingte Makuladegeneration, Glaukom-Erkennung, Video-Foundation-Modelle