Clear Sky Science · nl
Het paradigma van fundamentele netwerken voor het netvlies verleggen van slices naar volumes voor optische coherentie tomografie
Waarom dit belangrijk is voor ooggezondheid
Oogscans worden een belangrijk hulpmiddel om ziekten die het zicht bedreigen op te sporen, lang voordat iemand zelf symptomen opmerkt. Deze studie onderzoekt een nieuwe manier waarop kunstmatige intelligentie (AI) één van de krachtigste oogscans — optische coherentie tomografie (OCT) — kan lezen, door deze niet als één enkele afbeelding maar als een volledig driedimensionaal, filmachtig volume te behandelen. Die verschuiving blijkt de AI beter te maken in het herkennen van belangrijke oorzaken van blindheid, wat mogelijk eerder en betrouwbaarder screenen in klinieken wereldwijd kan brengen.
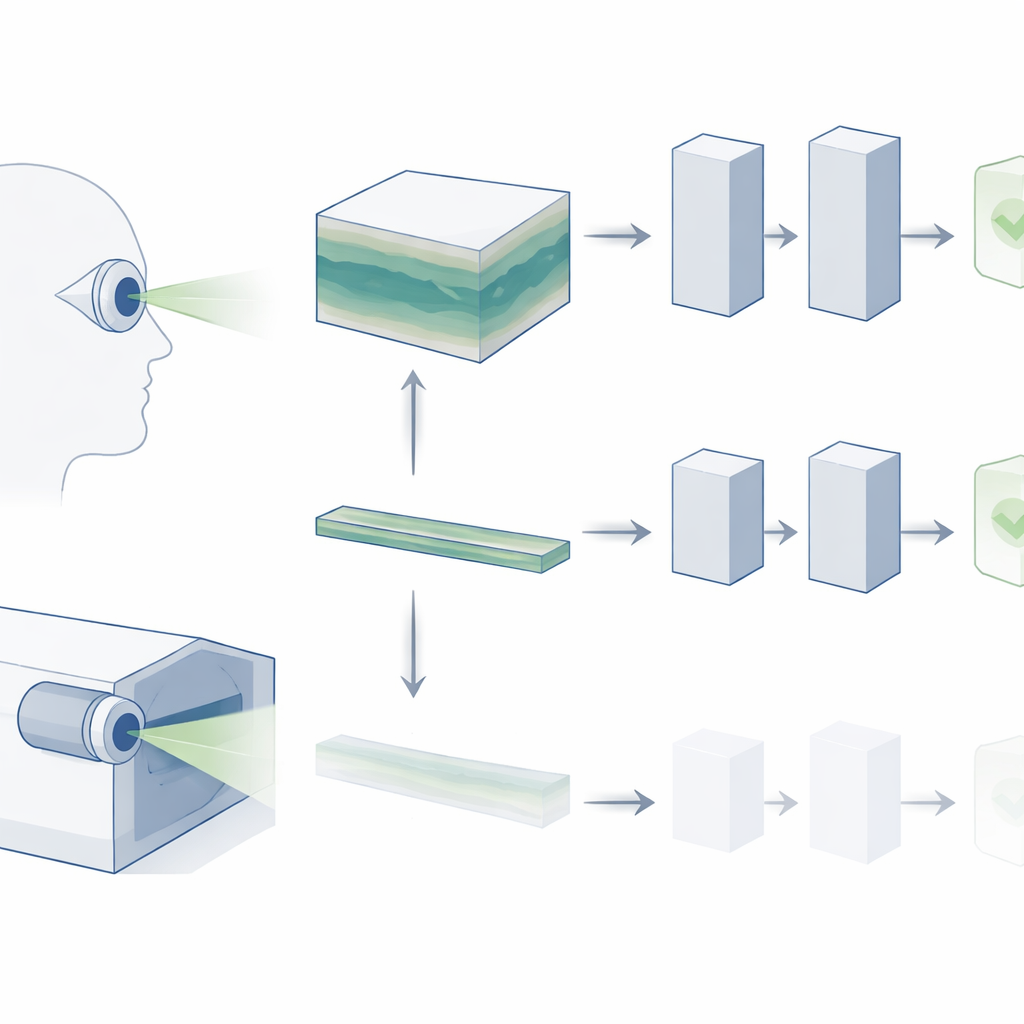
Van platte snapshots naar 3D-weergaven
OCT maakt een driedimensionaal blok van het netvlies, opgebouwd uit vele dunne dwarsneden. In de dagelijkse klinische praktijk scrollen oogartsen door dit gehele volume om tekenen van ziekte te zoeken, zoals kleine afzettingen bij leeftijdsgebonden maculadegeneratie (LMD) of subtiele structurele veranderingen bij glaucoom. Toch negeren de meeste bestaande AI-«foundation»-modellen voor netvliesbeelden deze rijke 3D-structuur. Ze bekijken meestal slechts één centrale slice, uitgaande van de veronderstelling dat die de belangrijkste informatie bevat. De auteurs stellen dat deze verkorting veel van wat clinici daadwerkelijk gebruiken weggooit en mogelijk een reden is waarom AI-systemen nog worstelen om aan diagnostische eisen in de praktijk te voldoen.
Ideeën lenen uit videoanalyse
In plaats van OCT als een losse foto te behandelen, benaderen de onderzoekers het alsof het een korte video is: een reeks slices die de diepte van het netvlies doorlopen. Ze passen een geavanceerd video-foundation-model toe genaamd V-JEPA, oorspronkelijk getraind op alledaagse natuurvideo’s, en passen het aan voor OCT. Net als andere moderne AI-systemen wordt V-JEPA eerst zelfgestuurd getraind, waarbij het leert ontbrekende informatie te voorspellen en aan te vullen zonder labeled voorbeelden. Dat creëert een krachtig algemeen "visueel vocabulaire" dat het model later kan hergebruiken. De onderzoekers finetunen V-JEPA daarna op kleinere, gelabelde OCT-datasets zodat het gezond en ziek kan onderscheiden.
Testen over landen en ziektes heen
Om te onderzoeken of deze 3D-aanpak daadwerkelijk helpt, vergeleek het team V-JEPA met drie sterke op afbeeldingen gebaseerde foundation-modellen, waaronder twee die specifiek op netvliesbeelden waren getraind en één die op natuurfoto’s was getraind. Alle modellen gebruikten vergelijkbare neurale netwerkarchitecturen, zodat prestatiedifferenties vooral weerspiegelen hoe ze de data gebruiken, niet hoe groot of complex ze zijn. De modellen moesten twee belangrijke oogziekten detecteren — glaucomateuze optische neuropathie (een vorm van glaucoom) en LMD — met vijf onafhankelijke OCT-datasets verzameld in de Verenigde Staten, China, Israël en Iran, die verschillende scanners, populaties en ziektepatronen omvatten.
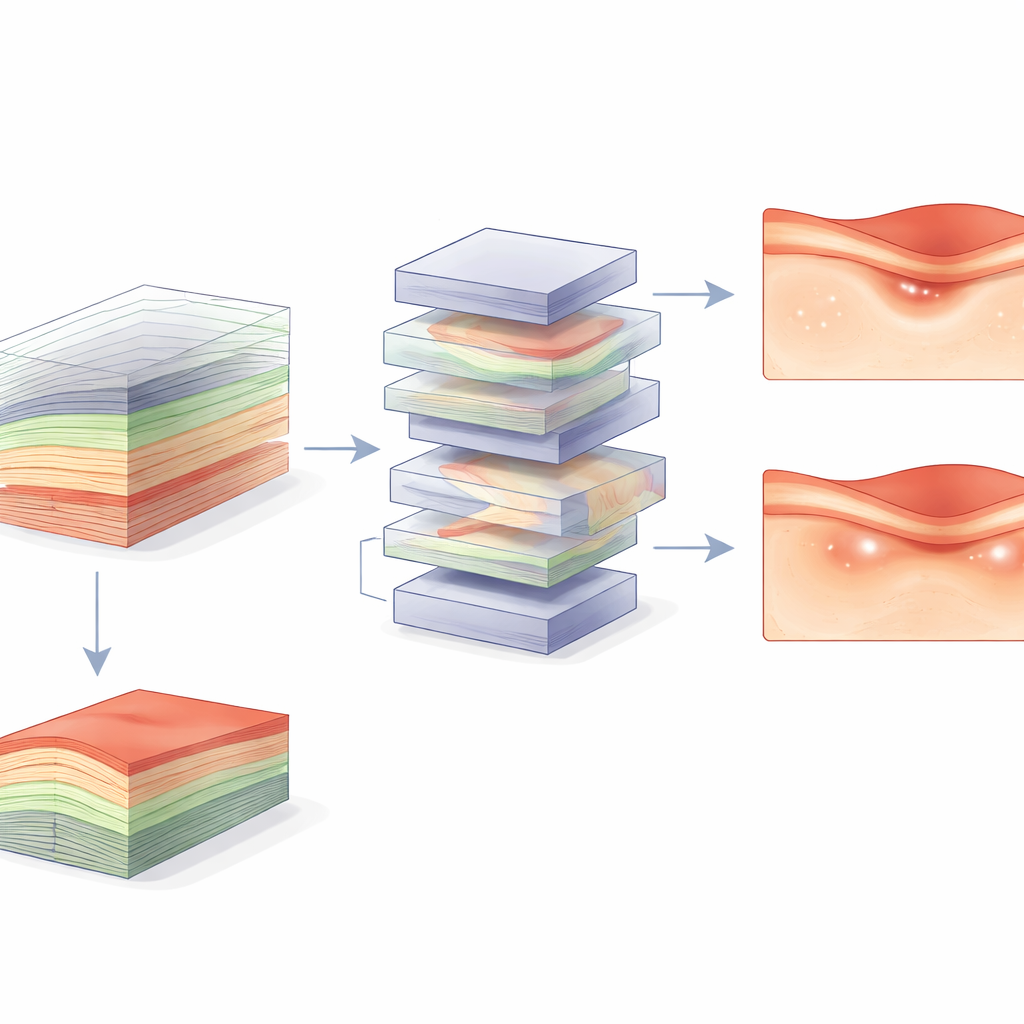
Helderdere antwoorden door volledige 3D-informatie
Over deze datasets heen presteerde het video-gebaseerde V-JEPA gelijk aan of beter dan alle op afbeeldingen gebaseerde modellen, met een gemiddelde area under the ROC curve van 0,94 vergeleken met 0,90 voor het beste single-slice-model — een statistisch significante verbetering. Het voordeel was het grootst voor enkele van de moeilijkere datasets, waar ziekte- en niet-ziektegevallen lastiger te onderscheiden waren. Analyse van de aandachtkaarten van het model toonde dat V-JEPA zich richt op relevante structuren verspreid over meerdere slices, niet alleen de centrale. Foutenanalyse liet zien dat single-slice-modellen vaak gevallen misten waarin pathologie afwezig of subtiel was in de middelste slice maar elders in het volume aanwezig was. Door de ruimtelijke dekking effectief te vergroten en te leren hoe slices zich tot elkaar verhouden, kon het 3D-model deze patronen beter vastleggen.
Balanceren van prestatie en praktische toepasbaarheid
De auteurs vergeleken V-JEPA ook met andere manieren om 3D-informatie te gebruiken, zoals klassieke driedimensionale convolutionele netwerken die from scratch zijn getraind en een "2.5D"-methode die vele slices één voor één verwerkt met een beeldmodel en vervolgens de resultaten combineert. V-JEPA presteerde over het algemeen beter dan deze alternatieven en vroeg minder rekenkracht dan de 2.5D-strategie. Belangrijk is dat de voordelen bleven bestaan zelfs wanneer slechts bescheiden hoeveelheden gelabelde data beschikbaar waren, en dat de prestatie bleef toenemen naarmate er meer trainingsdata kwam, terwijl op afbeeldingen gebaseerde modellen de neiging hadden te stabiliseren. Hoewel het analyseren van volumes trager is dan het lezen van één slice, bleef de extra verwerkingstijd klein — in de orde van honderdsten van een seconde per scan op moderne hardware.
Wat dit betekent voor toekomstige oogzorg
Voor niet-specialisten is de conclusie duidelijk: AI de retina in 3D laten zien, zoals clinici dat doen, leidt tot nauwkeurigere automatische detectie van veelvoorkomende blindmakende ziekten. Dit werk suggereert dat toekomstige "foundation-modellen" voor oogbeeldvorming vanaf het begin ontworpen moeten worden om volledige OCT-volumes te verwerken, niet alleen individuele snapshots. Gecombineerd met bredere gegevensdeling en uiteindelijk integratie met andere klinische informatie, zouden zulke modellen kunnen bijdragen aan consistente, hoogwaardige screening voor glaucoom en maculadegeneratie in veel meer klinieken en voor veel meer patiënten wereldwijd.
Bronvermelding: Judkiewicz, R., Berkowitz, E., Meisel, M. et al. Shifting the retinal foundation models paradigm from slices to volumes for optical coherence tomography. npj Digit. Med. 9, 314 (2026). https://doi.org/10.1038/s41746-026-02496-7
Trefwoorden: optische coherentie tomografie, AI voor netvliesbeeldvorming, leeftijdsgebonden maculadegeneratie, glaucoomdetectie, foundation-modellen voor video