Clear Sky Science · pt
Mudando o paradigma dos modelos fundacionais retinais de fatias para volumes para tomografia de coerência óptica
Por que isso importa para a saúde ocular
Exames oculares estão se tornando uma ferramenta de primeira linha para identificar doenças que ameaçam a visão muito antes de a pessoa notar sintomas. Este estudo explora uma nova forma de a inteligência artificial (IA) interpretar um dos exames oculares mais poderosos que temos — a tomografia de coerência óptica (OCT) — tratando-a não como uma imagem isolada, mas como um volume 3D semelhante a um pequeno filme. Essa mudança melhora a capacidade da IA de reconhecer as principais causas de cegueira, potencialmente levando a triagens mais precoces e confiáveis em clínicas ao redor do mundo.
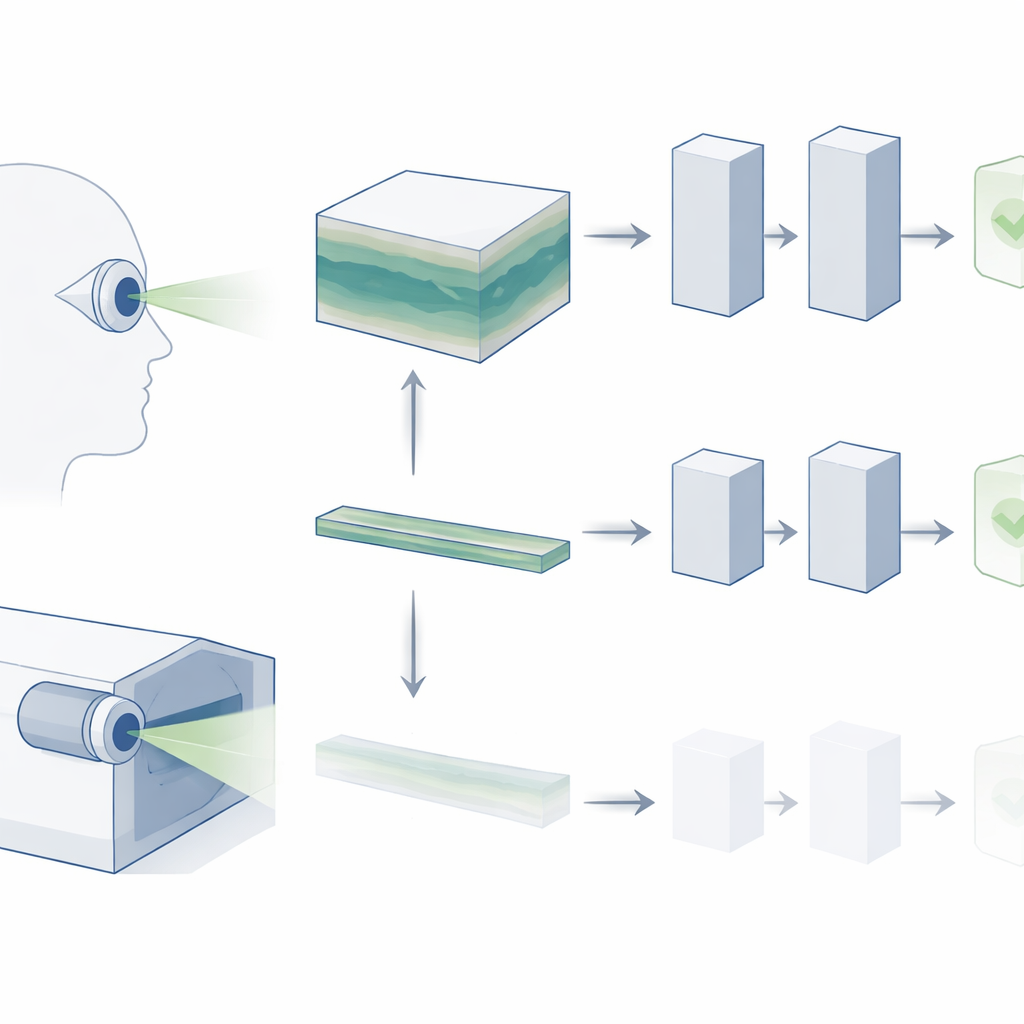
De instantâneos planos a vistas 3D
A OCT cria um bloco tridimensional da retina, construído a partir de muitas fatias seccionais finas. Na prática clínica diária, oftalmologistas percorrem todo esse volume para buscar sinais de doença, como depósitos microscópicos na degeneração macular relacionada à idade (DMRI) ou alterações estruturais sutis no glaucoma. Ainda assim, a maioria dos “modelos fundacionais” de IA para imagens retinianas ignora essa rica estrutura 3D. Eles normalmente analisam apenas uma fatia central, partindo da suposição de que ela contém a informação mais importante. Os autores argumentam que esse atalho descarta grande parte do que os clínicos realmente usam e pode ser uma das razões pelas quais os sistemas de IA ainda têm dificuldade em atender às necessidades diagnósticas do mundo real.
Emprestando ideias da análise de vídeo
Em vez de tratar a OCT como uma imagem isolada, os pesquisadores a consideram como se fosse um pequeno vídeo: uma sequência de fatias que avançam pela profundidade da retina. Eles adotam um modelo fundacional de vídeo de ponta chamado V-JEPA, originalmente treinado em vídeos naturais cotidianos, e o adaptam para OCT. Como outros sistemas modernos de IA, o V-JEPA é inicialmente treinado de forma auto-supervisionada, aprendendo a prever e preencher informações faltantes sem precisar de rótulos. Isso cria um poderoso “vocabulário visual” geral que o modelo pode reutilizar. Em seguida, os pesquisadores refinam o V-JEPA em conjuntos de dados OCT rotulados menores para que ele possa distinguir entre olhos saudáveis e doentes.
Testes entre países e doenças
Para avaliar se essa abordagem 3D realmente ajuda, a equipe comparou o V-JEPA com três fortes modelos fundacionais baseados em imagem, incluindo dois treinados especificamente em imagens retinianas e um treinado em fotografias naturais. Todos os modelos usaram arquiteturas de rede neural subjacentes semelhantes, de modo que as diferenças de desempenho refletem principalmente como eles usam os dados, não quão grandes ou complexos são. Os modelos foram solicitados a detectar duas grandes doenças oculares — neuropatia óptica glaucomatosa (uma forma de glaucoma) e DMRI — usando cinco conjuntos de dados OCT independentes coletados nos Estados Unidos, China, Israel e Irã, cobrindo diferentes aparelhos, populações e padrões de doença.
Respostas mais claras a partir da informação 3D completa
Nesses conjuntos de dados, o V-JEPA baseado em vídeo igualou ou superou todos os modelos baseados em imagem, alcançando uma área média sob a curva ROC de 0,94 contra 0,90 do melhor modelo de fatia única — um ganho estatisticamente significativo. A vantagem foi maior em alguns dos dados mais desafiadores, onde casos com e sem doença eram mais difíceis de distinguir. Análises dos mapas de atenção do modelo mostraram que o V-JEPA foca em estruturas relevantes espalhadas por múltiplas fatias, e não apenas na central. A análise de erros revelou que modelos de fatia única frequentemente perdiam casos em que a patologia estava ausente ou era sutil na fatia central, mas presente em outras partes do volume. Ao aumentar efetivamente a cobertura espacial e aprender como as fatias se relacionam entre si, o modelo 3D capturou melhor esses padrões.
Equilibrando desempenho e praticidade
Os autores também compararam o V-JEPA com outras formas de usar informação 3D, como redes convolucionais tridimensionais clássicas treinadas do zero e um método “2,5D” que processa muitas fatias uma a uma com um modelo de imagem e depois combina os resultados. O V-JEPA geralmente superou essas alternativas enquanto requeria menos computação do que a estratégia 2,5D. Importante, seus benefícios se mantiveram mesmo quando havia apenas quantidades modestas de dados rotulados, e seu desempenho continuou a melhorar conforme aumentava a quantidade de dados de treinamento, enquanto os modelos baseados em imagem tendiam a plateaurar. Embora analisar volumes seja mais lento do que ler uma única fatia, o tempo extra de processamento permaneceu pequeno — na ordem de centésimos de segundo por exame em hardware moderno.
O que isso significa para o cuidado ocular futuro
Para não especialistas, a conclusão é direta: permitir que a IA veja a retina em 3D, da mesma forma que os clínicos fazem, leva a uma detecção automatizada mais precisa de doenças cegantes comuns. Este trabalho sugere que futuros “modelos fundacionais” para imagens oculares devem ser projetados desde o início para lidar com volumes OCT completos, não apenas com instantâneos individuais. Combinados com maior compartilhamento de dados e, eventualmente, integração com outras informações clínicas, esses modelos poderiam ajudar a levar triagens consistentes e de alta qualidade para glaucoma e degeneração macular a muito mais clínicas e pacientes no mundo todo.
Citação: Judkiewicz, R., Berkowitz, E., Meisel, M. et al. Shifting the retinal foundation models paradigm from slices to volumes for optical coherence tomography. npj Digit. Med. 9, 314 (2026). https://doi.org/10.1038/s41746-026-02496-7
Palavras-chave: tomografia de coerência óptica, IA para imagem retiniana, degeneração macular relacionada à idade, detecção de glaucoma, modelos fundacionais de vídeo