Clear Sky Science · es
Cambiar el paradigma de los modelos base retinianos de cortes a volúmenes para tomografía de coherencia óptica
Por qué esto importa para la salud ocular
Las exploraciones oculares se están convirtiendo en una herramienta de primera línea para detectar enfermedades que amenazan la visión mucho antes de que la persona note síntomas. Este estudio explora una nueva manera para que la inteligencia artificial (IA) interprete una de las exploraciones oculares más potentes que tenemos—la tomografía de coherencia óptica (OCT)—tratándola no como una imagen única, sino como un volumen tridimensional similar a una película. Ese cambio mejora la capacidad de la IA para reconocer las principales causas de ceguera, lo que podría permitir cribados más tempranos y fiables en clínicas de todo el mundo.
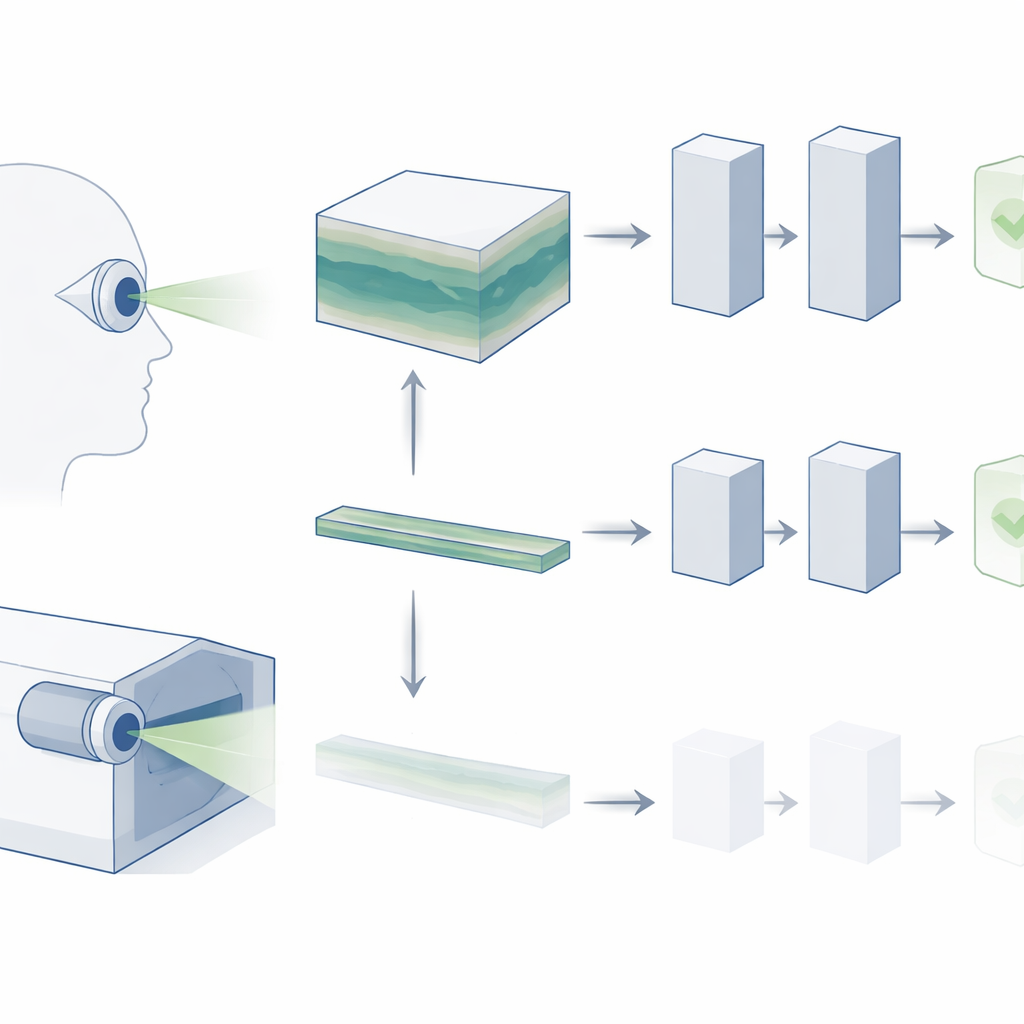
De instantáneas planas a vistas 3D
La OCT genera un bloque tridimensional de la retina, construido a partir de muchas rebanadas transversales delgadas. En la práctica clínica diaria, los oftalmólogos recorren este volumen completo para buscar signos de enfermedad, como pequeños depósitos en la degeneración macular relacionada con la edad (DMAE) o cambios estructurales sutiles en el glaucoma. Sin embargo, la mayoría de los “modelos base” de IA existentes para imágenes retinianas ignoran esta rica estructura 3D. Normalmente analizan solo una rebanada central, partiendo de la suposición de que contiene la información más importante. Los autores sostienen que ese atajo descarta gran parte de lo que los clínicos realmente usan, y puede ser una razón por la que los sistemas de IA aún tienen dificultades para satisfacer las necesidades diagnósticas del mundo real.
Tomando ideas del análisis de vídeo
En lugar de tratar la OCT como una imagen aislada, los investigadores la consideran como si fuera un vídeo corto: una secuencia de rebanadas que avanzan a través de la profundidad de la retina. Adoptan un modelo base de vídeo de vanguardia llamado V-JEPA, entrenado originalmente con vídeos naturales cotidianos, y lo adaptan a OCT. Como otros sistemas modernos de IA, V-JEPA se entrena primero de forma auto-supervisada, aprendiendo a predecir y completar información faltante sin necesitar etiquetas. Esto crea un poderoso “vocabulario visual” general que el modelo puede reutilizar. Los investigadores afinan después V-JEPA con conjuntos de datos OCT pequeños y etiquetados para que distinga entre ojos sanos y enfermos.
Pruebas entre países y enfermedades
Para comprobar si este enfoque 3D realmente ayuda, el equipo comparó V-JEPA con tres sólidos modelos base basados en imágenes, incluidos dos entrenados específicamente con imágenes retinianas y otro entrenado con fotografías naturales. Todos los modelos usaron arquitecturas neuronales subyacentes similares, de modo que las diferencias en el rendimiento reflejan principalmente cómo usan los datos, no su tamaño o complejidad. Se pidió a los modelos detectar dos enfermedades oculares importantes—neuropatía óptica glaucomatosa (una forma de glaucoma) y DMAE—utilizando cinco conjuntos de OCT independientes recogidos en Estados Unidos, China, Israel e Irán, que abarcan distintos escáneres, poblaciones y patrones de enfermedad.
Respuestas más claras con la información 3D completa
En todos estos conjuntos de datos, el modelo basado en vídeo V-JEPA igualó o superó a todos los modelos basados en imágenes, alcanzando una media del área bajo la curva ROC de 0,94 frente a 0,90 del mejor modelo de una sola rebanada—una ganancia estadísticamente significativa. La ventaja fue mayor en algunos de los datos más desafiantes, donde resultaba más difícil distinguir casos con y sin enfermedad. Los análisis de los mapas de atención del modelo mostraron que V-JEPA se centra en estructuras relevantes repartidas en varias rebanadas, no solo en la central. El análisis de errores reveló que los modelos de una sola rebanada a menudo pasaban por alto casos en los que la patología estaba ausente o era sutil en la rebanada media pero estaba presente en otra parte del volumen. Al aumentar efectivamente la cobertura espacial y aprender cómo se relacionan las rebanadas entre sí, el modelo 3D pudo capturar mejor estos patrones.
Equilibrando rendimiento y practicidad
Los autores también compararon V-JEPA con otras formas de aprovechar la información 3D, como las clásicas redes convolucionales tridimensionales entrenadas desde cero y un método “2.5D” que procesa muchas rebanadas una por una con un modelo de imagen y luego combina los resultados. V-JEPA superó en general a estas alternativas mientras requería menos cálculo que la estrategia 2.5D. Es importante que sus beneficios se mantuvieron incluso cuando solo había cantidades modestas de datos etiquetados, y su rendimiento continuó mejorando a medida que aumentaba la cantidad de datos de entrenamiento, mientras que los modelos basados en imágenes tendían a estabilizarse. Aunque analizar volúmenes es más lento que leer una sola rebanada, el tiempo adicional de procesamiento siguió siendo pequeño—del orden de centésimas de segundo por exploración en hardware moderno.
Qué significa esto para la atención ocular futura
Para quienes no son especialistas, la conclusión es clara: permitir que la IA vea la retina en 3D, como lo hacen los clínicos, conduce a una detección automatizada más precisa de las enfermedades comunes que causan ceguera. Este trabajo sugiere que los futuros “modelos base” para imagen ocular deberían diseñarse desde el principio para manejar volúmenes OCT completos, no solo instantáneas individuales. Combinados con un mayor intercambio de datos y, eventualmente, la integración con otra información clínica, dichos modelos podrían ayudar a llevar cribados consistentes y de alta calidad para el glaucoma y la degeneración macular a muchas más clínicas y pacientes en todo el mundo.
Cita: Judkiewicz, R., Berkowitz, E., Meisel, M. et al. Shifting the retinal foundation models paradigm from slices to volumes for optical coherence tomography. npj Digit. Med. 9, 314 (2026). https://doi.org/10.1038/s41746-026-02496-7
Palabras clave: tomografía de coherencia óptica, IA en imagen retiniana, degeneración macular relacionada con la edad, detección de glaucoma, modelos base para vídeo